 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIf Turing played piano with an artificial partner
Feb 09, 2024Music is an inherently social activity that allows people to share experiences and feel connected with one another. There has been little progress in designing artificial partners exhibiting a similar social experience as playing with another person. Neural network architectures that implement generative models, such as large language models, are suited for producing musical scores. Playing music socially, however, involves more than playing a score; it must complement the other musicians' ideas and keep time correctly. We addressed the question of whether a convincing social experience is made possible by a generative model trained to produce musical scores, not necessarily optimized for synchronization and continuation. The network, a variational autoencoder trained on a large corpus of digital scores, was adapted for a timed call-and-response task with a human partner. Participants played piano with a human or artificial partner-in various configurations-and rated the performance quality and first-person experience of self-other integration. Overall, the artificial partners held promise but were rated lower than human partners. The artificial partner with simplest design and highest similarity parameter was not rated differently from the human partners on some measures, suggesting that interactive rather than generative sophistication is important in enabling social AI.
Malakai: Music That Adapts to the Shape of Emotions
Dec 03, 2021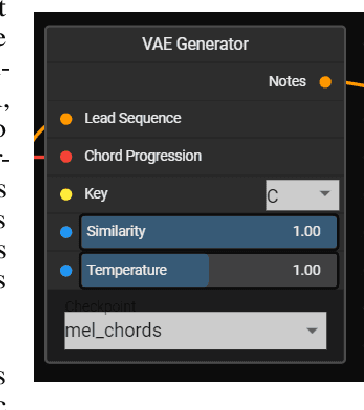
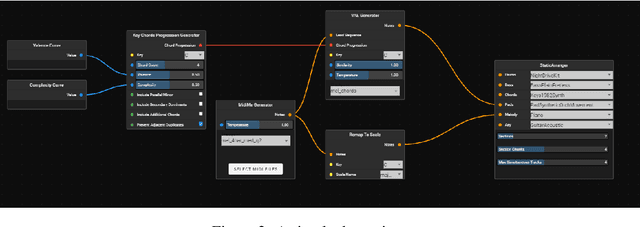
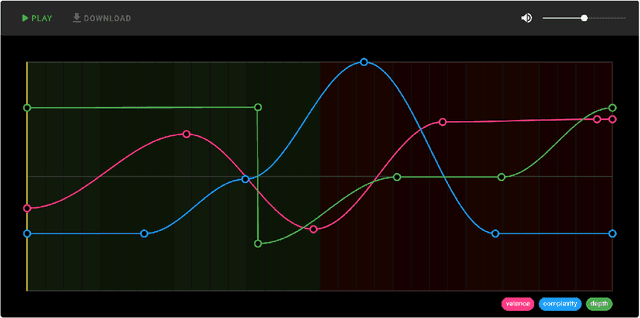
The advent of ML music models such as Google Magenta's MusicVAE now allow us to extract and replicate compositional features from otherwise complex datasets. These models allow computational composers to parameterize abstract variables such as style and mood. By leveraging these models and combining them with procedural algorithms from the last few decades, it is possible to create a dynamic song that composes music in real-time to accompany interactive experiences. Malakai is a tool that helps users of varying skill levels create, listen to, remix and share such dynamic songs. Using Malakai, a Composer can create a dynamic song that can be interacted with by a Listener