 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Lexical Diversity in Texts: The Twofold Length Problem
Jul 29, 2023The impact of text length on the estimation of lexical diversity has captured the attention of the scientific community for more than a century. Numerous indices have been proposed, and many studies have been conducted to evaluate them, but the problem remains. This methodological review provides a critical analysis not only of the most commonly used indices in language learning studies, but also of the length problem itself, as well as of the methodology for evaluating the proposed solutions. The analysis of three datasets of English language-learners' texts revealed that indices that reduce all texts to the same length using a probabilistic or an algorithmic approach solve the length dependency problem; however, all these indices failed to address the second problem, which is their sensitivity to the parameter that determines the length to which the texts are reduced. The paper concludes with recommendations for optimizing lexical diversity analysis.
Comparing Formulaic Language in Human and Machine Translation: Insight from a Parliamentary Corpus
Jun 22, 2022



A recent study has shown that, compared to human translations, neural machine translations contain more strongly-associated formulaic sequences made of relatively high-frequency words, but far less strongly-associated formulaic sequences made of relatively rare words. These results were obtained on the basis of translations of quality newspaper articles in which human translations can be thought to be not very literal. The present study attempts to replicate this research using a parliamentary corpus. The text were translated from French to English by three well-known neural machine translation systems: DeepL, Google Translate and Microsoft Translator. The results confirm the observations on the news corpus, but the differences are less strong. They suggest that the use of text genres that usually result in more literal translations, such as parliamentary corpora, might be preferable when comparing human and machine translations. Regarding the differences between the three neural machine systems, it appears that Google translations contain fewer highly collocational bigrams, identified by the CollGram technique, than Deepl and Microsoft translations.
Please, Don't Forget the Difference and the Confidence Interval when Seeking for the State-of-the-Art Status
May 23, 2022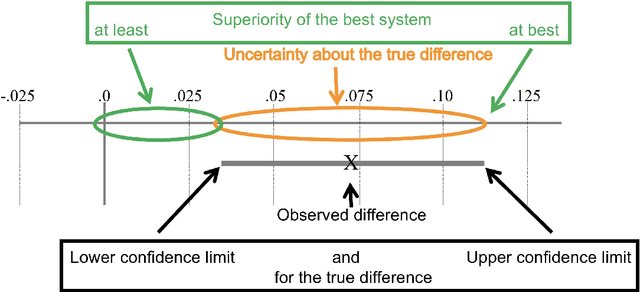

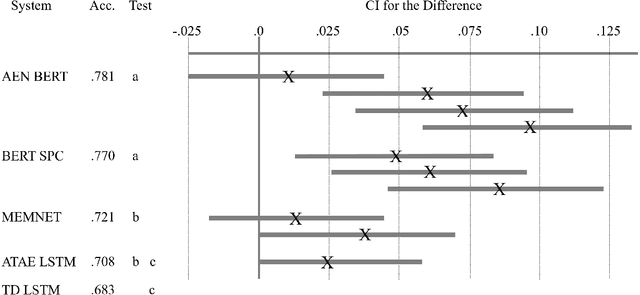
This paper argues for the widest possible use of bootstrap confidence intervals for comparing NLP system performances instead of the state-of-the-art status (SOTA) and statistical significance testing. Their main benefits are to draw attention to the difference in performance between two systems and to help assessing the degree of superiority of one system over another. Two cases studies, one comparing several systems and the other based on a K-fold cross-validation procedure, illustrate these benefits. A python module for obtaining these confidence intervals as well as a second function implementing the Fisher-Pitman test for paired samples are freely available on PyPi.
SATLab at SemEval-2022 Task 4: Trying to Detect Patronizing and Condescending Language with only Character and Word N-grams
Mar 10, 2022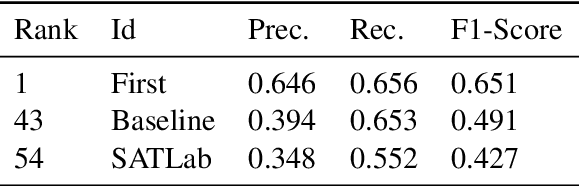
A logistic regression model only fed with character and word n-grams is proposed for the SemEval-2022 Task 4 on Patronizing and Condescending Language Detection (PCL). It obtained an average level of performance, well above the performance of a system that tries to guess without using any knowledge about the task, but much lower than the best teams. As the proposed model is very similar to the one that performed well on a task requiring to automatically identify hate speech and offensive content, this paper confirms the difficulty of PCL detection.
A simple language-agnostic yet very strong baseline system for hate speech and offensive content identification
Feb 05, 2022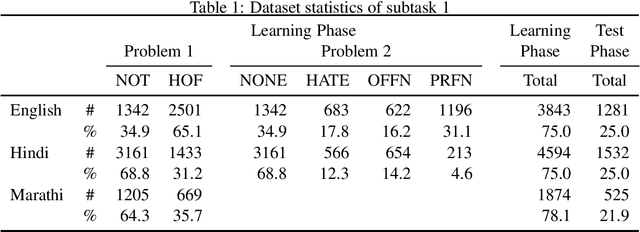
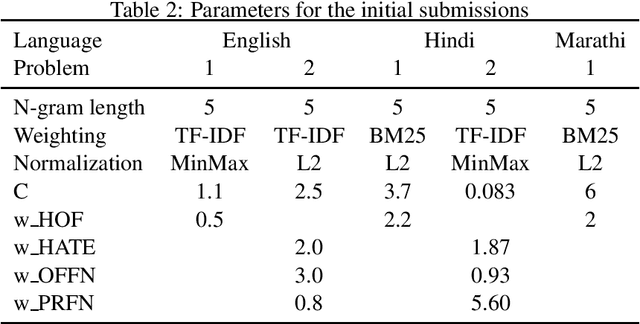
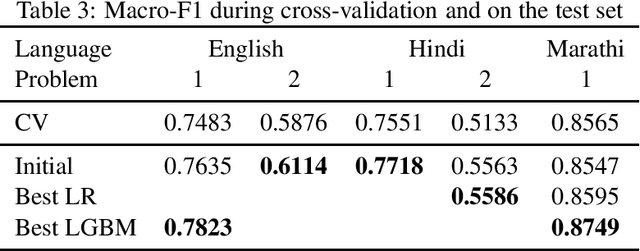
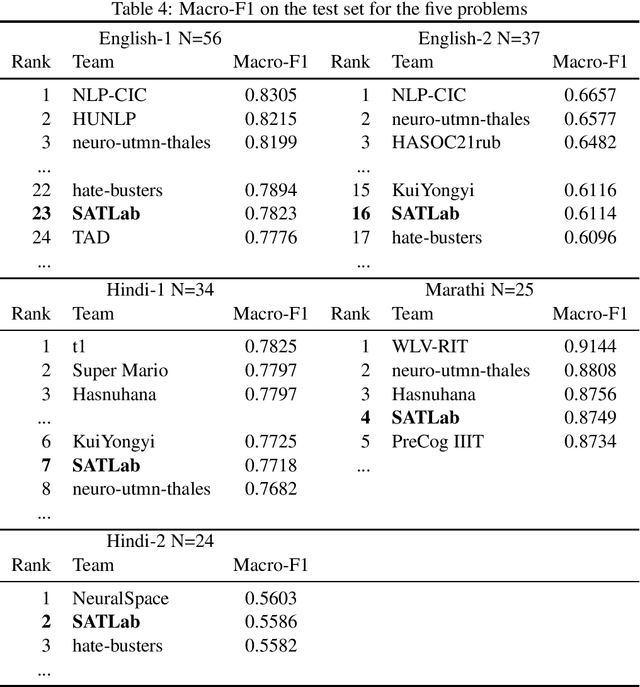
For automatically identifying hate speech and offensive content in tweets, a system based on a classical supervised algorithm only fed with character n-grams, and thus completely language-agnostic, is proposed by the SATLab team. After its optimization in terms of the feature weighting and the classifier parameters, it reached, in the multilingual HASOC 2021 challenge, a medium performance level in English, the language for which it is easy to develop deep learning approaches relying on many external linguistic resources, but a far better level for the two less resourced language, Hindi and Marathi. It ends even first when performances are averaged over the three tasks in these languages, outperforming many deep learning approaches. These performances suggest that it is an interesting reference level to evaluate the benefits of using more complex approaches such as deep learning or taking into account complementary resources.
Using CollGram to Compare Formulaic Language in Human and Neural Machine Translation
Jul 23, 2021


A comparison of formulaic sequences in human and neural machine translation of quality newspaper articles shows that neural machine translations contain less lower-frequency, but strongly-associated formulaic sequences, and more high-frequency formulaic sequences. These differences were statistically significant and the effect sizes were almost always medium or large. These observations can be related to the differences between second language learners of various levels and between translated and untranslated texts. The comparison between the neural machine translation systems indicates that some systems produce more formulaic sequences of both types than other systems.
LAST at SemEval-2021 Task 1: Improving Multi-Word Complexity Prediction Using Bigram Association Measures
May 20, 2021



This paper describes the system developed by the Laboratoire d'analyse statistique des textes (LAST) for the Lexical Complexity Prediction shared task at SemEval-2021. The proposed system is made up of a LightGBM model fed with features obtained from many word frequency lists, published lexical norms and psychometric data. For tackling the specificity of the multi-word task, it uses bigram association measures. Despite that the only contextual feature used was sentence length, the system achieved an honorable performance in the multi-word task, but poorer in the single word task. The bigram association measures were found useful, but to a limited extent.
Using Fisher's Exact Test to Evaluate Association Measures for N-grams
Apr 29, 2021

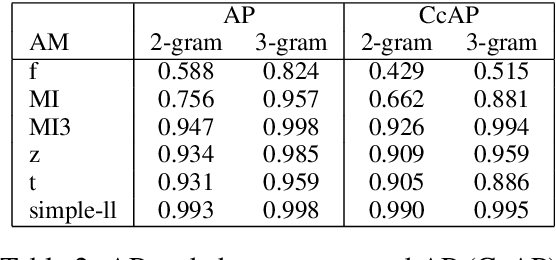
To determine whether some often-used lexical association measures assign high scores to n-grams that chance could have produced as frequently as observed, we used an extension of Fisher's exact test to sequences longer than two words to analyse a corpus of four million words. The results, based on the precision-recall curve and a new index called chance-corrected average precision, show that, as expected, simple-ll is extremely effective. They also show, however, that MI3 is more efficient than the other hypothesis tests-based measures and even reaches a performance level almost equal to simple-ll for 3-grams. It is additionally observed that some measures are more efficient for 3-grams than for 2-grams, while others stagnate.
LAST at CMCL 2021 Shared Task: Predicting Gaze Data During Reading with a Gradient Boosting Decision Tree Approach
Apr 27, 2021
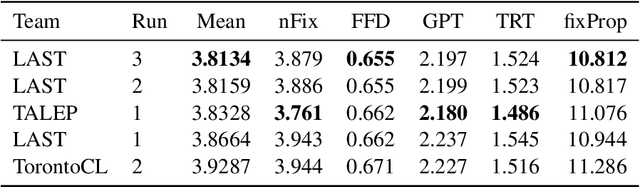

A LightGBM model fed with target word lexical characteristics and features obtained from word frequency lists, psychometric data and bigram association measures has been optimized for the 2021 CMCL Shared Task on Eye-Tracking Data Prediction. It obtained the best performance of all teams on two of the five eye-tracking measures to predict, allowing it to rank first on the official challenge criterion and to outperform all deep-learning based systems participating in the challenge.