 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture Proportion Estimation and Weakly-supervised Kernel Test for Conditional Independence
Apr 08, 2026Mixture proportion estimation (MPE) aims to estimate class priors from unlabeled data. This task is a critical component in weakly supervised learning, such as PU learning, learning with label noise, and domain adaptation. Existing MPE methods rely on the \textit{irreducibility} assumption or its variant for identifiability. In this paper, we propose novel assumptions based on conditional independence (CI) given the class label, which ensure identifiability even when irreducibility does not hold. We develop method of moments estimators under these assumptions and analyze their asymptotic properties. Furthermore, we present weakly-supervised kernel tests to validate the CI assumptions, which are of independent interest in applications such as causal discovery and fairness evaluation. Empirically, we demonstrate the improved performance of our estimators compared with existing methods and that our tests successfully control both type I and type II errors.\label{key}
Transductive Data Augmentation with Relational Path Rule Mining for Knowledge Graph Embedding
Nov 01, 2021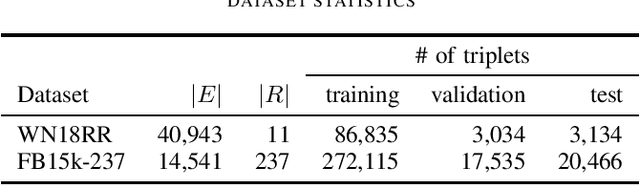
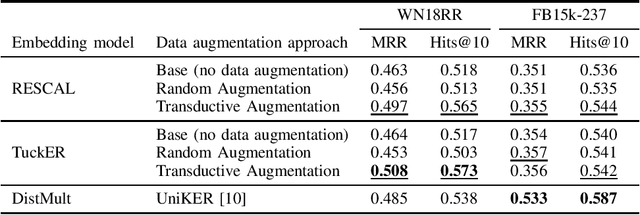
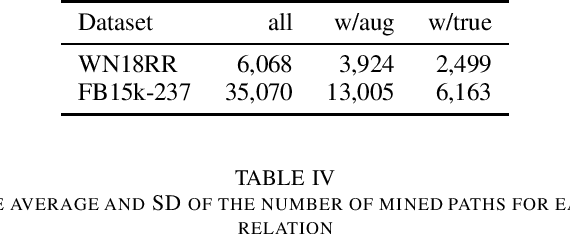

For knowledge graph completion, two major types of prediction models exist: one based on graph embeddings, and the other based on relation path rule induction. They have different advantages and disadvantages. To take advantage of both types, hybrid models have been proposed recently. One of the hybrid models, UniKER, alternately augments training data by relation path rules and trains an embedding model. Despite its high prediction accuracy, it does not take full advantage of relation path rules, as it disregards low-confidence rules in order to maintain the quality of augmented data. To mitigate this limitation, we propose transductive data augmentation by relation path rules and confidence-based weighting of augmented data. The results and analysis show that our proposed method effectively improves the performance of the embedding model by augmenting data that include true answers or entities similar to them.