 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslation Analytics for Freelancers II: Benchmarking Local LLMs for Confidential Translation Workflows
May 29, 2026Building on our previous work, this paper develops practical, low-barrier methods for freelance translators and smaller language service providers to evaluate translation technologies using rigorous yet accessible analytic methods. Here we address a high-stakes, specialized need: offline translation for confidentiality-sensitive domains in which privacy constraints preclude the use of cloud-based engines and commercial LLMs. We expand the Reeve Foundation Trilingual Corpus (RFTC) used in our previous work into a multilingual corpus (RFMC) by adding sentence-aligned German and Simplified Chinese reference translations. We then benchmark several locally runnable language models (via Ollama) across four language directions on 1000+ sentences selected from this corpus. We use consistent single-prompt calls without fine-tuning or domain adaptation, comparing local LLM outputs against commercial NMTs (DeepL, Baidu), a frontier LLM (GPT-5.2), and professional-grade local NMT systems (OPUS-CAT, NeuralDesktop, Promt). Automatic evaluation is conducted with MATEO. Results reveal substantial variation in local LLM performance across language directions and model sizes. The best local LLMs match or surpass local NMT systems and a frontier LLM, though they remain behind top commercial NMTs. These findings underscore the viability of carefully selected local LLM translation for privacy-constrained professionals and inform future research on model scaling and multilingual capability.
Translation in the Wild
May 29, 2025



Large Language Models (LLMs) excel in translation among other things, demonstrating competitive performance for many language pairs in zero- and few-shot settings. But unlike dedicated neural machine translation models, LLMs are not trained on any translation-related objective. What explains their remarkable translation abilities? Are these abilities grounded in "incidental bilingualism" (Briakou et al. 2023) in training data? Does instruction tuning contribute to it? Are LLMs capable of aligning and leveraging semantically identical or similar monolingual contents from different corners of the internet that are unlikely to fit in a single context window? I offer some reflections on this topic, informed by recent studies and growing user experience. My working hypothesis is that LLMs' translation abilities originate in two different types of pre-training data that may be internalized by the models in different ways. I discuss the prospects for testing the "duality" hypothesis empirically and its implications for reconceptualizing translation, human and machine, in the age of deep learning.
Translation Analytics for Freelancers: I. Introduction, Data Preparation, Baseline Evaluations
Apr 20, 2025



This is the first in a series of papers exploring the rapidly expanding new opportunities arising from recent progress in language technologies for individual translators and language service providers with modest resources. The advent of advanced neural machine translation systems, large language models, and their integration into workflows via computer-assisted translation tools and translation management systems have reshaped the translation landscape. These advancements enable not only translation but also quality evaluation, error spotting, glossary generation, and adaptation to domain-specific needs, creating new technical opportunities for freelancers. In this series, we aim to empower translators with actionable methods to harness these advancements. Our approach emphasizes Translation Analytics, a suite of evaluation techniques traditionally reserved for large-scale industry applications but now becoming increasingly available for smaller-scale users. This first paper introduces a practical framework for adapting automatic evaluation metrics -- such as BLEU, chrF, TER, and COMET -- to freelancers' needs. We illustrate the potential of these metrics using a trilingual corpus derived from a real-world project in the medical domain and provide statistical analysis correlating human evaluations with automatic scores. Our findings emphasize the importance of proactive engagement with emerging technologies to not only adapt but thrive in the evolving professional environment.
The boundaries of meaning: a case study in neural machine translation
Oct 02, 2022

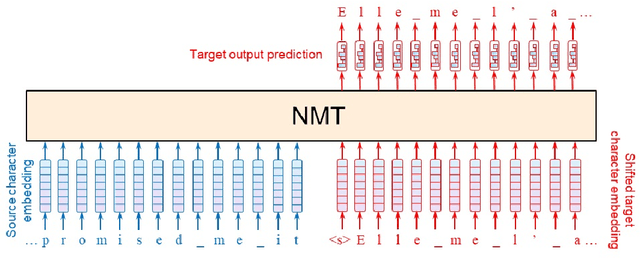

The success of deep learning in natural language processing raises intriguing questions about the nature of linguistic meaning and ways in which it can be processed by natural and artificial systems. One such question has to do with subword segmentation algorithms widely employed in language modeling, machine translation, and other tasks since 2016. These algorithms often cut words into semantically opaque pieces, such as 'period', 'on', 't', and 'ist' in 'period|on|t|ist'. The system then represents the resulting segments in a dense vector space, which is expected to model grammatical relations among them. This representation may in turn be used to map 'period|on|t|ist' (English) to 'par|od|ont|iste' (French). Thus, instead of being modeled at the lexical level, translation is reformulated more generally as the task of learning the best bilingual mapping between the sequences of subword segments of two languages; and sometimes even between pure character sequences: 'p|e|r|i|o|d|o|n|t|i|s|t' $\rightarrow$ 'p|a|r|o|d|o|n|t|i|s|t|e'. Such subword segmentations and alignments are at work in highly efficient end-to-end machine translation systems, despite their allegedly opaque nature. The computational value of such processes is unquestionable. But do they have any linguistic or philosophical plausibility? I attempt to cast light on this question by reviewing the relevant details of the subword segmentation algorithms and by relating them to important philosophical and linguistic debates, in the spirit of making artificial intelligence more transparent and explainable.
* 35 pages, 4 figures, 1 table