 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixel-level Quality Assessment for Oriented Object Detection
Nov 11, 2025Modern oriented object detectors typically predict a set of bounding boxes and select the top-ranked ones based on estimated localization quality. Achieving high detection performance requires that the estimated quality closely aligns with the actual localization accuracy. To this end, existing approaches predict the Intersection over Union (IoU) between the predicted and ground-truth (GT) boxes as a proxy for localization quality. However, box-level IoU prediction suffers from a structural coupling issue: since the predicted box is derived from the detector's internal estimation of the GT box, the predicted IoU--based on their similarity--can be overestimated for poorly localized boxes. To overcome this limitation, we propose a novel Pixel-level Quality Assessment (PQA) framework, which replaces box-level IoU prediction with the integration of pixel-level spatial consistency. PQA measures the alignment between each pixel's relative position to the predicted box and its corresponding position to the GT box. By operating at the pixel level, PQA avoids directly comparing the predicted box with the estimated GT box, thereby eliminating the inherent similarity bias in box-level IoU prediction. Furthermore, we introduce a new integration metric that aggregates pixel-level spatial consistency into a unified quality score, yielding a more accurate approximation of the actual localization quality. Extensive experiments on HRSC2016 and DOTA demonstrate that PQA can be seamlessly integrated into various oriented object detectors, consistently improving performance (e.g., +5.96% AP$_{50:95}$ on Rotated RetinaNet and +2.32% on STD).
Robust X-ray Sparse-view Phase Tomography via Hierarchical Synthesis Convolutional Neural Networks
Jan 30, 2019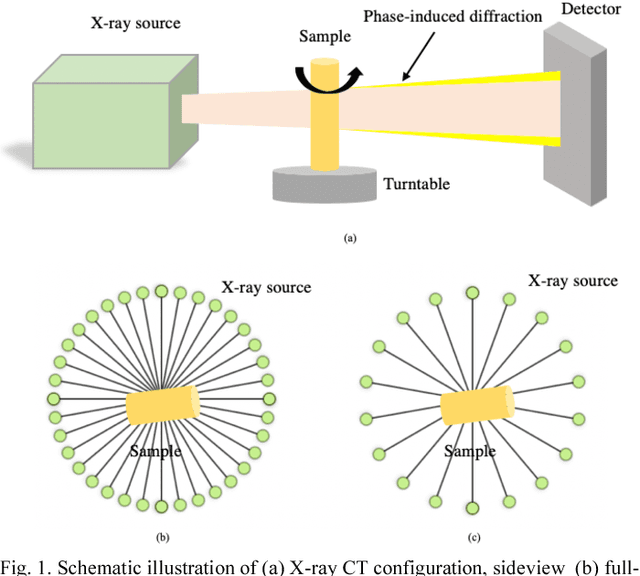
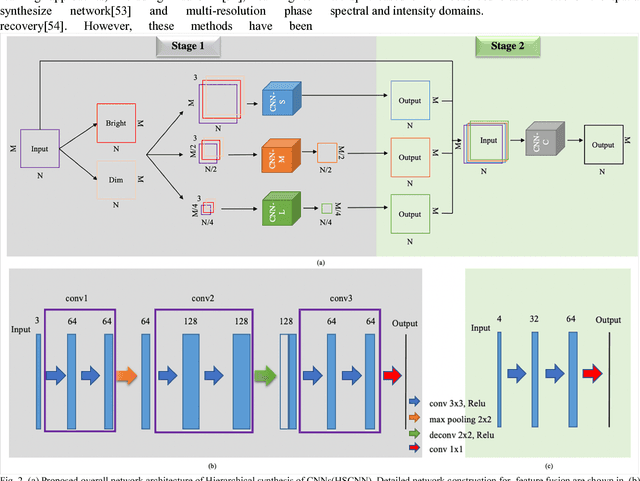


Convolutional Neural Networks (CNN) based image reconstruction methods have been intensely used for X-ray computed tomography (CT) reconstruction applications. Despite great success, good performance of this data-based approach critically relies on a representative big training data set and a dense convoluted deep network. The indiscriminating convolution connections over all dense layers could be prone to over-fitting, where sampling biases are wrongly integrated as features for the reconstruction. In this paper, we report a robust hierarchical synthesis reconstruction approach, where training data is pre-processed to separate the information on the domains where sampling biases are suspected. These split bands are then trained separately and combined successively through a hierarchical synthesis network. We apply the hierarchical synthesis reconstruction for two important and classical tomography reconstruction scenarios: the spares-view reconstruction and the phase reconstruction. Our simulated and experimental results show that comparable or improved performances are achieved with a dramatic reduction of network complexity and computational cost. This method can be generalized to a wide range of applications including material characterization, in-vivo monitoring and dynamic 4D imaging.