 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrior Knowledge about Attributes: Learning a More Effective Potential Space for Zero-Shot Recognition
Sep 14, 2020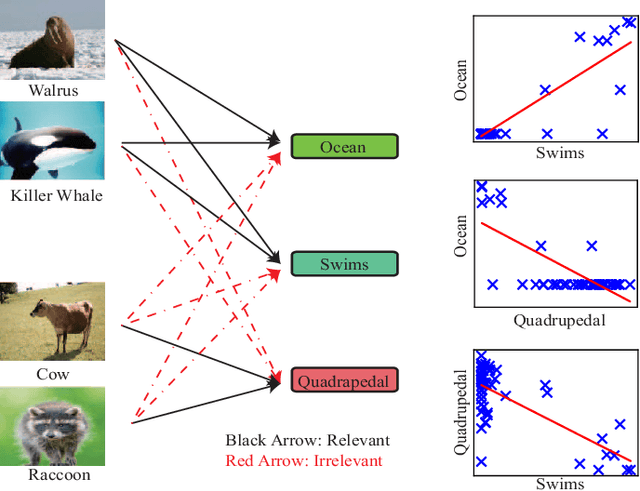
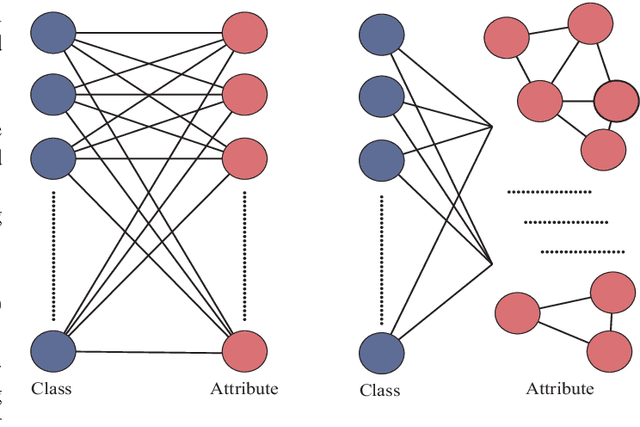
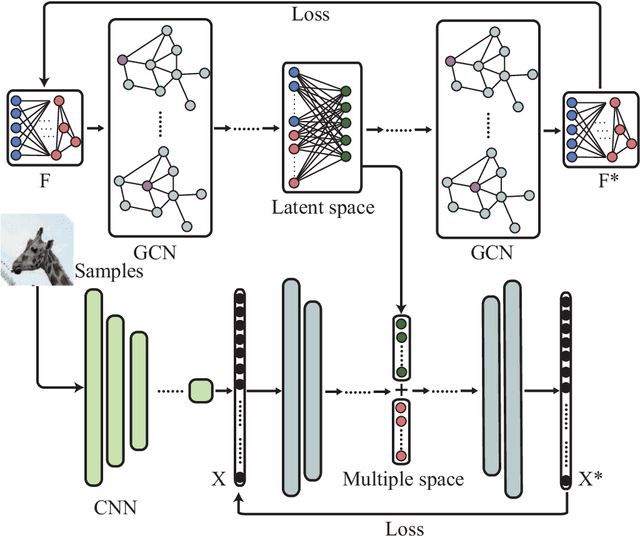
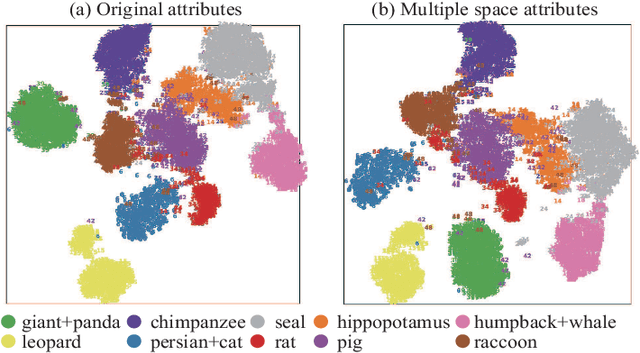
Zero-shot learning (ZSL) aims to recognize unseen classes accurately by learning seen classes and known attributes, but correlations in attributes were ignored by previous study which lead to classification results confused. To solve this problem, we build an Attribute Correlation Potential Space Generation (ACPSG) model which uses a graph convolution network and attribute correlation to generate a more discriminating potential space. Combining potential discrimination space and user-defined attribute space, we can better classify unseen classes. Our approach outperforms some existing state-of-the-art methods on several benchmark datasets, whether it is conventional ZSL or generalized ZSL.
Cascade Network for Self-Supervised Monocular Depth Estimation
Sep 14, 2020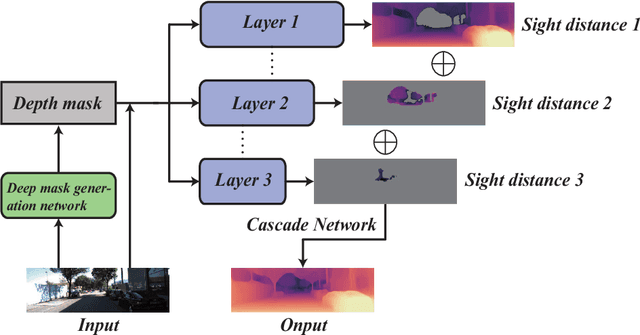
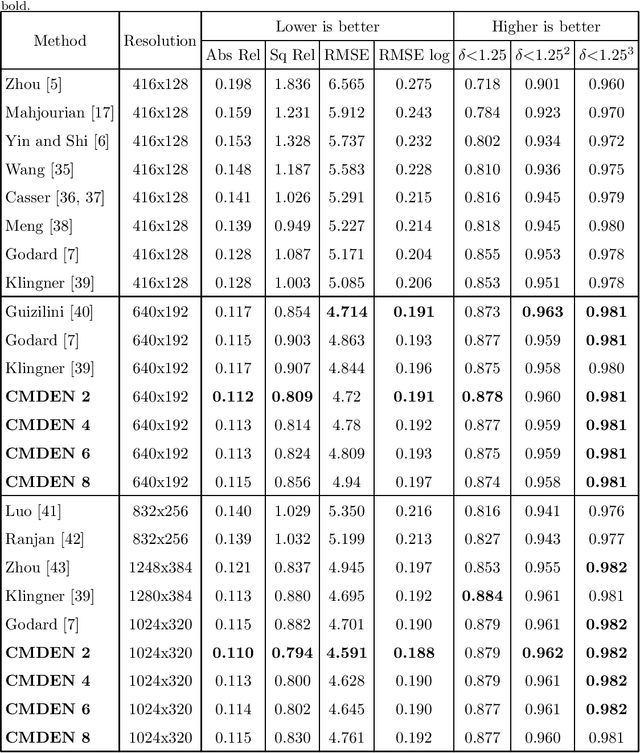
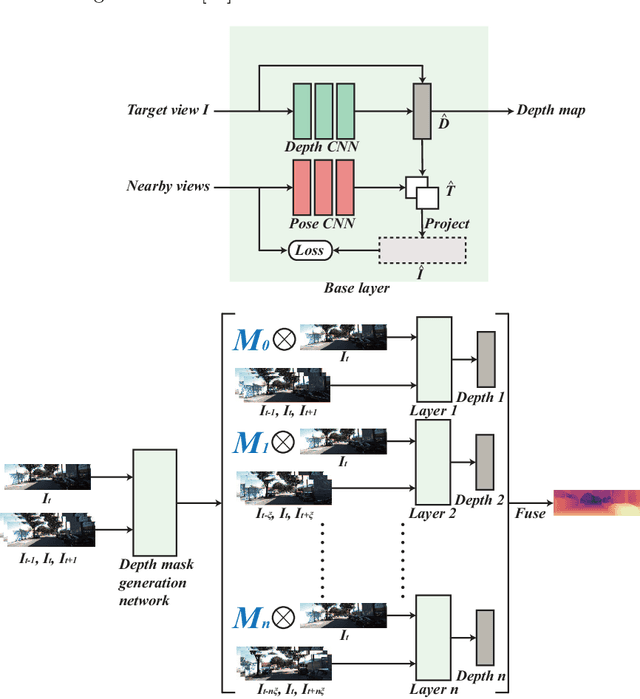
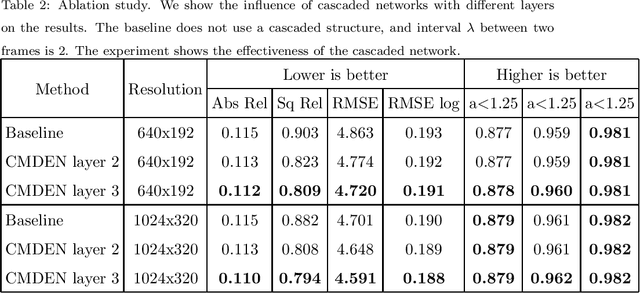
It is a classical compute vision problem to obtain real scene depth maps by using a monocular camera, which has been widely concerned in recent years. However, training this model usually requires a large number of artificially labeled samples. To solve this problem, some researchers use a self-supervised learning model to overcome this problem and reduce the dependence on manually labeled data. Nevertheless, the accuracy and reliability of these methods have not reached the expected standard. In this paper, we propose a new self-supervised learning method based on cascade networks. Compared with the previous self-supervised methods, our method has improved accuracy and reliability, and we have proved this by experiments. We show a cascaded neural network that divides the target scene into parts of different sight distances and trains them separately to generate a better depth map. Our approach is divided into the following four steps. In the first step, we use the self-supervised model to estimate the depth of the scene roughly. In the second step, the depth of the scene generated in the first step is used as a label to divide the scene into different depth parts. The third step is to use models with different parameters to generate depth maps of different depth parts in the target scene, and the fourth step is to fuse the depth map. Through the ablation study, we demonstrated the effectiveness of each component individually and showed high-quality, state-of-the-art results in the KITTI benchmark.