 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Probabilistic Models in Text Classification via Active Learning
Feb 05, 2022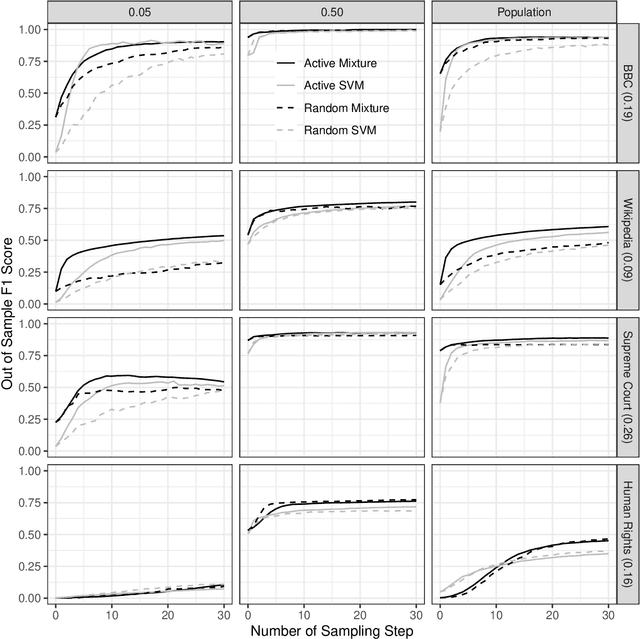
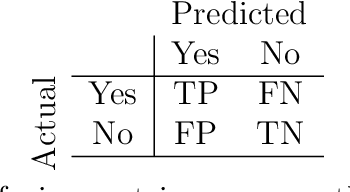
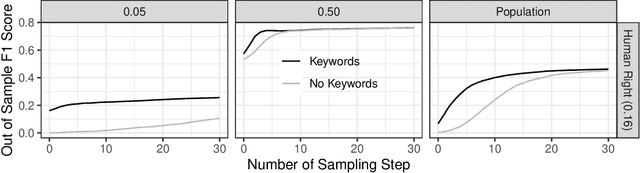
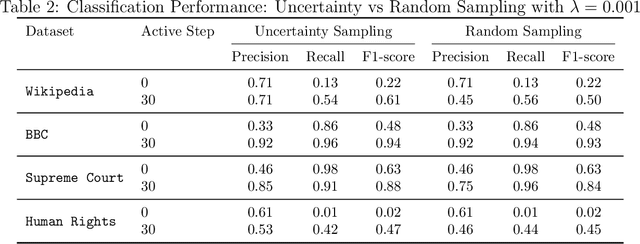
When using text data, social scientists often classify documents in order to use the resulting document labels as an outcome or predictor. Since it is prohibitively costly to label a large number of documents manually, automated text classification has become a standard tool. However, current approaches for text classification do not take advantage of all the data at one's disposal. We propose a fast new model for text classification that combines information from both labeled and unlabeled data with an active learning component, where a human iteratively labels documents that the algorithm is least certain about. Using text data from Wikipedia discussion pages, BBC News articles, historical US Supreme Court opinions, and human rights abuse allegations, we show that by introducing information about the structure of unlabeled data and iteratively labeling uncertain documents, our model improves performance relative to classifiers that (a) only use information from labeled data and (b) randomly decide which documents to label at the cost of manually labelling a small number of documents.
Large-scale text processing pipeline with Apache Spark
Dec 02, 2019
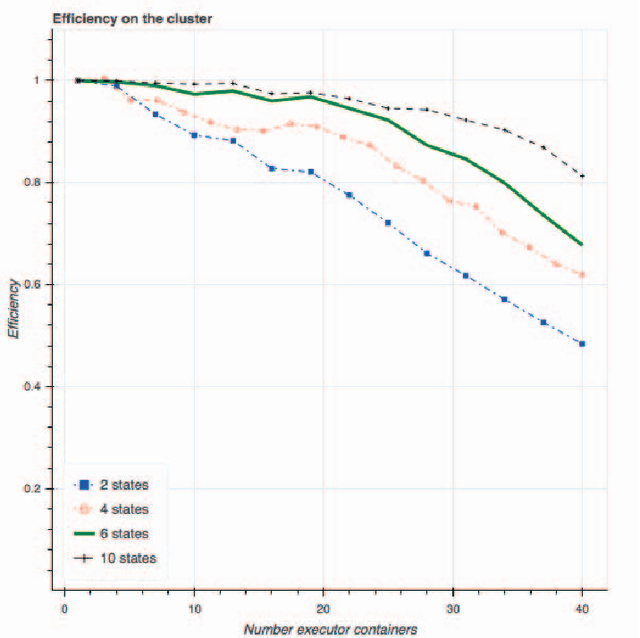
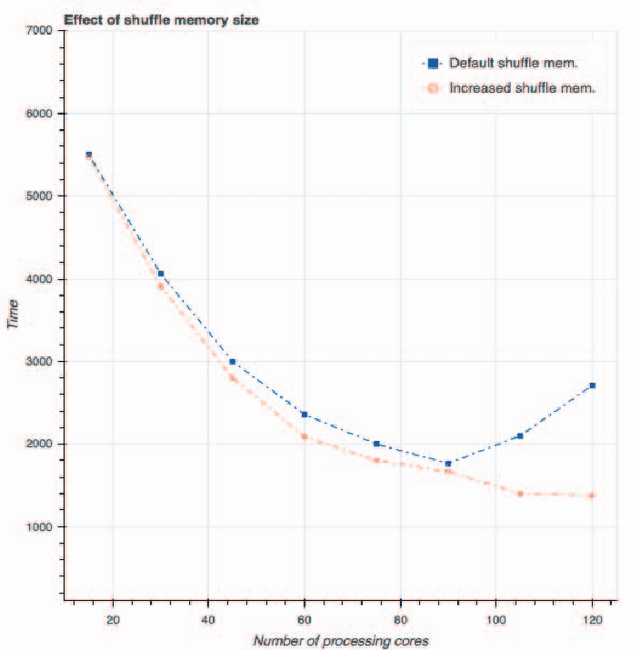
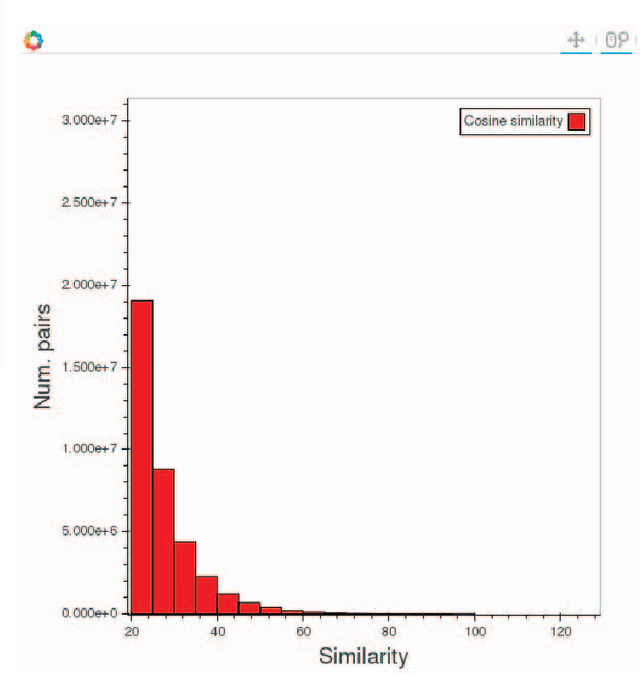
In this paper, we evaluate Apache Spark for a data-intensive machine learning problem. Our use case focuses on policy diffusion detection across the state legislatures in the United States over time. Previous work on policy diffusion has been unable to make an all-pairs comparison between bills due to computational intensity. As a substitute, scholars have studied single topic areas. We provide an implementation of this analysis workflow as a distributed text processing pipeline with Spark dataframes and Scala application programming interface. We discuss the challenges and strategies of unstructured data processing, data formats for storage and efficient access, and graph processing at scale.