 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel Modulation: A Parameter-Efficient Method for Training Convolutional Neural Networks
Mar 29, 2022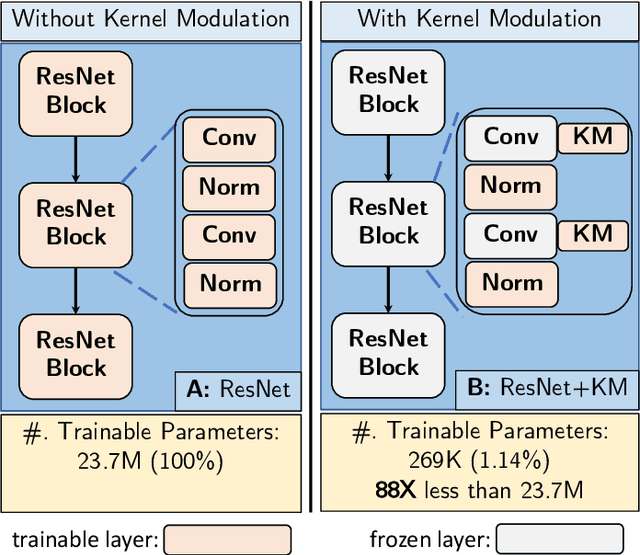
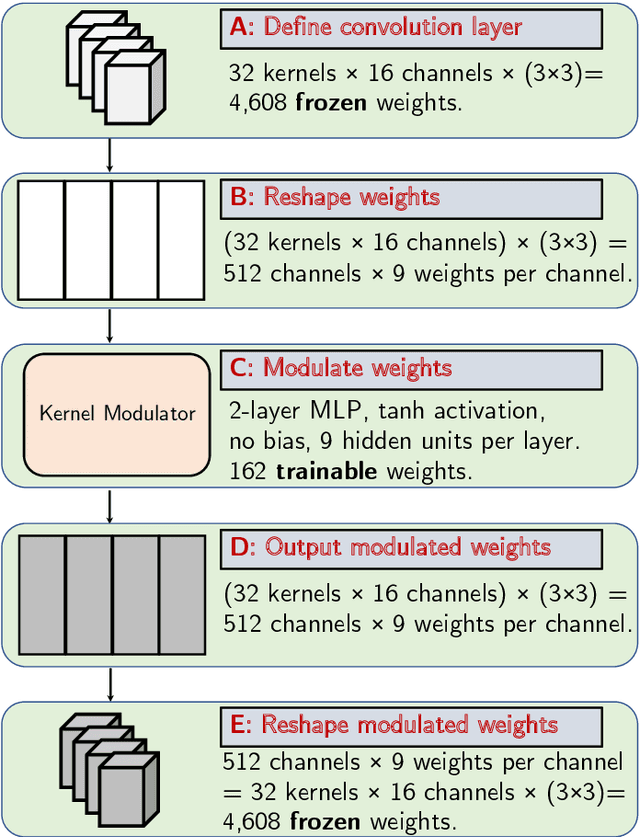
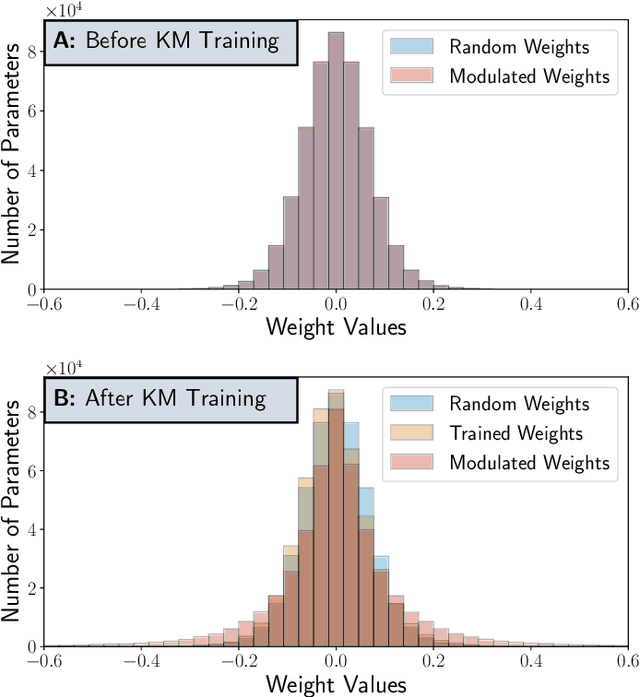
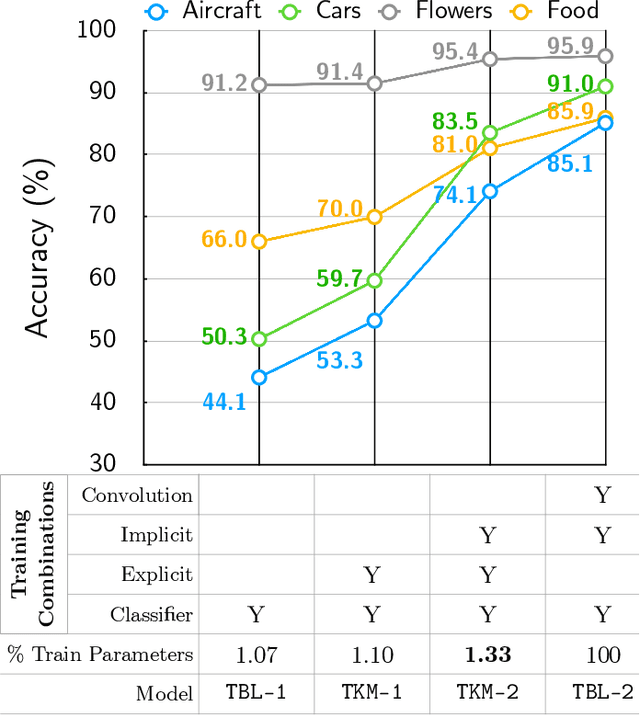
Deep Neural Networks, particularly Convolutional Neural Networks (ConvNets), have achieved incredible success in many vision tasks, but they usually require millions of parameters for good accuracy performance. With increasing applications that use ConvNets, updating hundreds of networks for multiple tasks on an embedded device can be costly in terms of memory, bandwidth, and energy. Approaches to reduce this cost include model compression and parameter-efficient models that adapt a subset of network layers for each new task. This work proposes a novel parameter-efficient kernel modulation (KM) method that adapts all parameters of a base network instead of a subset of layers. KM uses lightweight task-specialized kernel modulators that require only an additional 1.4% of the base network parameters. With multiple tasks, only the task-specialized KM weights are communicated and stored on the end-user device. We applied this method in training ConvNets for Transfer Learning and Meta-Learning scenarios. Our results show that KM delivers up to 9% higher accuracy than other parameter-efficient methods on the Transfer Learning benchmark.
Exploiting Spatial Sparsity for Event Cameras with Visual Transformers
Feb 10, 2022



Event cameras report local changes of brightness through an asynchronous stream of output events. Events are spatially sparse at pixel locations with little brightness variation. We propose using a visual transformer (ViT) architecture to leverage its ability to process a variable-length input. The input to the ViT consists of events that are accumulated into time bins and spatially separated into non-overlapping sub-regions called patches. Patches are selected when the number of nonzero pixel locations within a sub-region is above a threshold. We show that by fine-tuning a ViT model on the selected active patches, we can reduce the average number of patches fed into the backbone during the inference by at least 50% with only a minor drop (0.34%) of the classification accuracy on the N-Caltech101 dataset. This reduction translates into a decrease of 51% in Multiply-Accumulate (MAC) operations and an increase of 46% in the inference speed using a server CPU.
T-NGA: Temporal Network Grafting Algorithm for Learning to Process Spiking Audio Sensor Events
Feb 07, 2022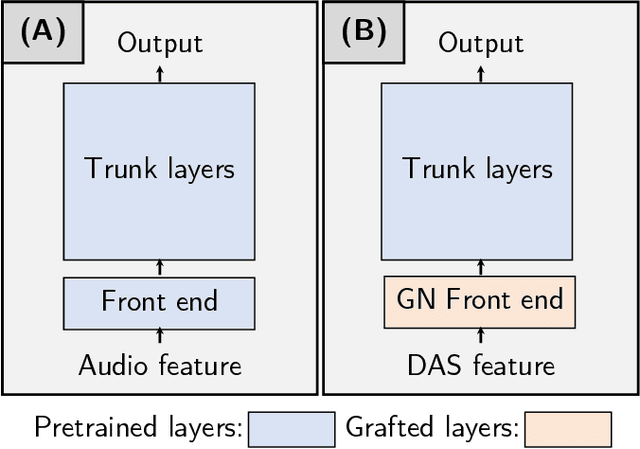
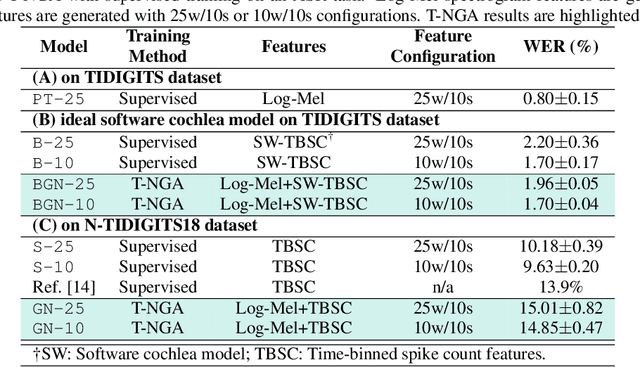
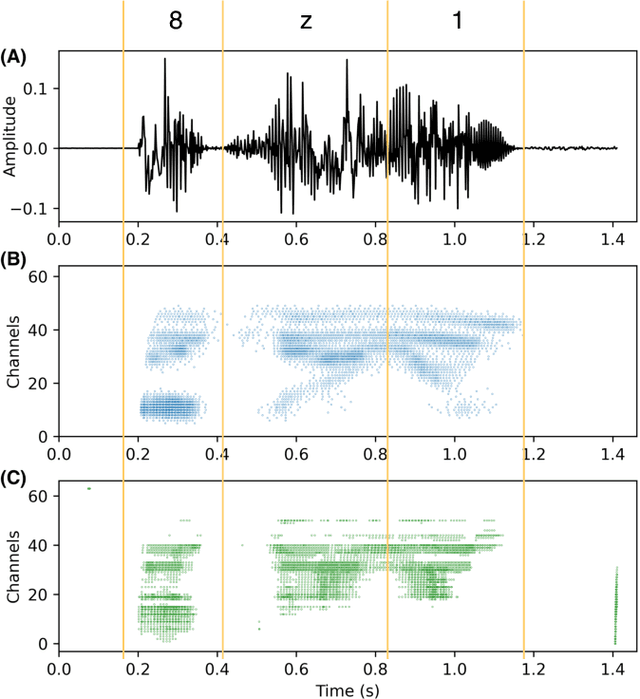

Spiking silicon cochlea sensors encode sound as an asynchronous stream of spikes from different frequency channels. The lack of labeled training datasets for spiking cochleas makes it difficult to train deep neural networks on the outputs of these sensors. This work proposes a self-supervised method called Temporal Network Grafting Algorithm (T-NGA), which grafts a recurrent network pretrained on spectrogram features so that the network works with the cochlea event features. T-NGA training requires only temporally aligned audio spectrograms and event features. Our experiments show that the accuracy of the grafted network was similar to the accuracy of a supervised network trained from scratch on a speech recognition task using events from a software spiking cochlea model. Despite the circuit non-idealities of the spiking silicon cochlea, the grafted network accuracy on the silicon cochlea spike recordings was only about 5% lower than the supervised network accuracy using the N-TIDIGITS18 dataset. T-NGA can train networks to process spiking audio sensor events in the absence of large labeled spike datasets.
V2E: From video frames to realistic DVS event camera streams
Jun 13, 2020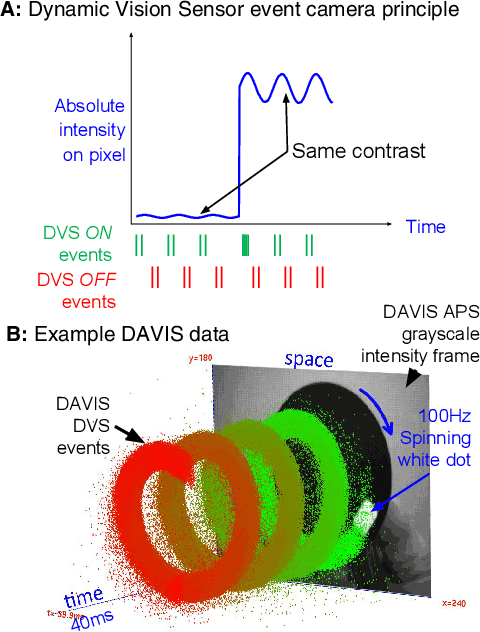
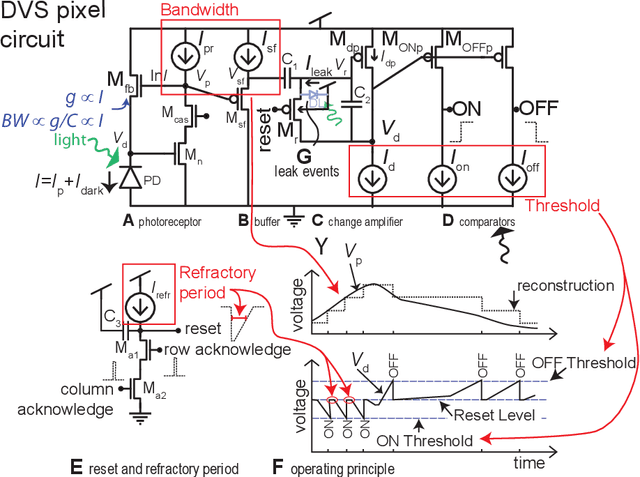
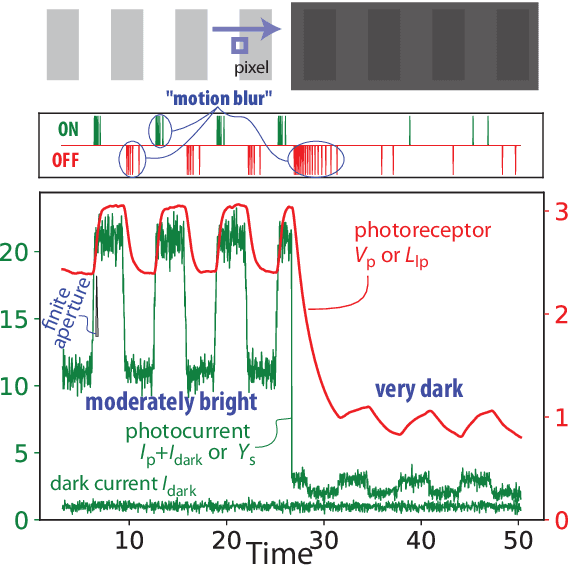
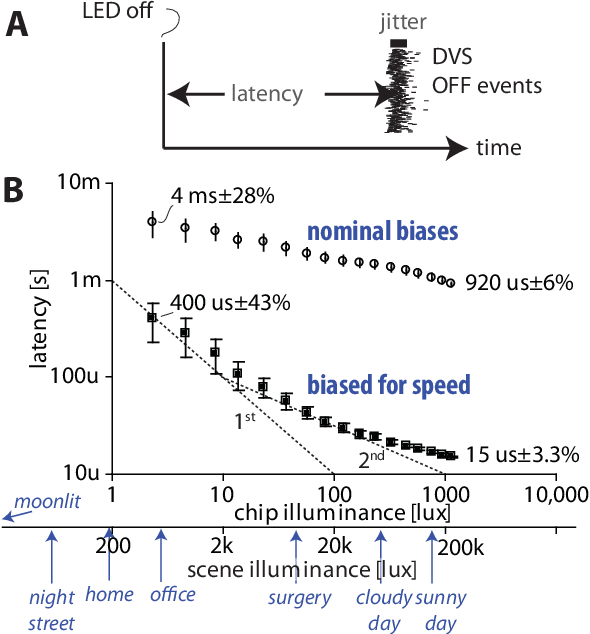
To help meet the increasing need for dynamic vision sensor (DVS) event camera data, we developed the v2e toolbox, which generates synthetic DVS event streams from intensity frame videos. Videos can be of any type, either real or synthetic. v2e optionally uses synthetic slow motion to upsample the video frame rate and then generates DVS events from these frames using a realistic pixel model that includes event threshold mismatch, finite illumination-dependent bandwidth, and several types of noise. v2e includes an algorithm that determines the DVS thresholds and bandwidth so that the synthetic event stream statistics match a given reference DVS recording. v2e is the first toolbox that can synthesize realistic low light DVS data. This paper also clarifies misleading claims about DVS characteristics in some of the computer vision literature. The v2e website is https://sites.google.com/view/video2events/home and code is hosted at https://github.com/SensorsINI/v2e.
DDD20 End-to-End Event Camera Driving Dataset: Fusing Frames and Events with Deep Learning for Improved Steering Prediction
May 18, 2020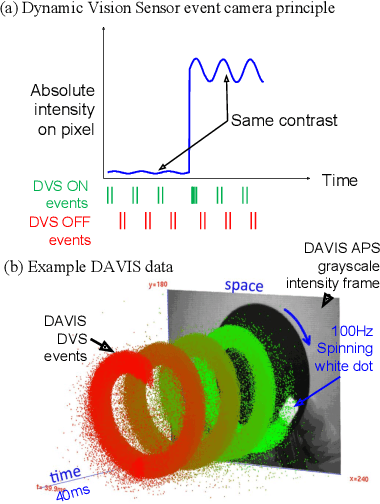


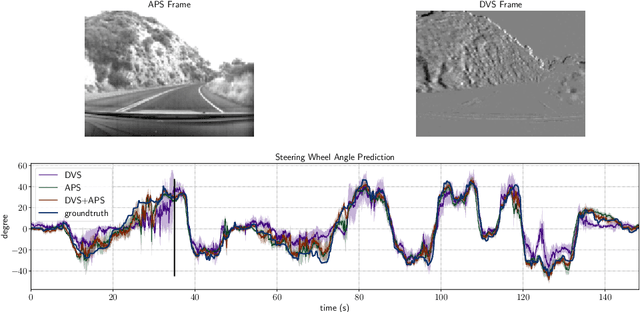
Neuromorphic event cameras are useful for dynamic vision problems under difficult lighting conditions. To enable studies of using event cameras in automobile driving applications, this paper reports a new end-to-end driving dataset called DDD20. The dataset was captured with a DAVIS camera that concurrently streams both dynamic vision sensor (DVS) brightness change events and active pixel sensor (APS) intensity frames. DDD20 is the longest event camera end-to-end driving dataset to date with 51h of DAVIS event+frame camera and vehicle human control data collected from 4000km of highway and urban driving under a variety of lighting conditions. Using DDD20, we report the first study of fusing brightness change events and intensity frame data using a deep learning approach to predict the instantaneous human steering wheel angle. Over all day and night conditions, the explained variance for human steering prediction from a Resnet-32 is significantly better from the fused DVS+APS frames (0.88) than using either DVS (0.67) or APS (0.77) data alone.
Character-Level Translation with Self-attention
Apr 30, 2020



We explore the suitability of self-attention models for character-level neural machine translation. We test the standard transformer model, as well as a novel variant in which the encoder block combines information from nearby characters using convolutions. We perform extensive experiments on WMT and UN datasets, testing both bilingual and multilingual translation to English using up to three input languages (French, Spanish, and Chinese). Our transformer variant consistently outperforms the standard transformer at the character-level and converges faster while learning more robust character-level alignments.
Exploiting Event Cameras by Using a Network Grafting Algorithm
Mar 24, 2020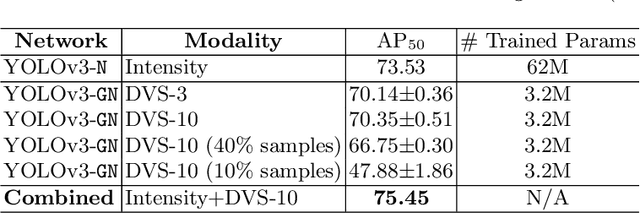
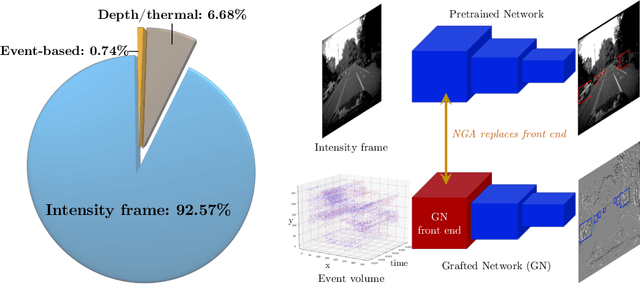
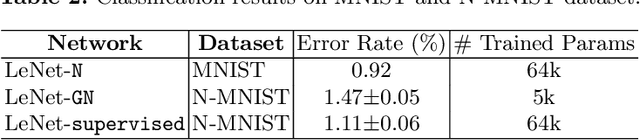
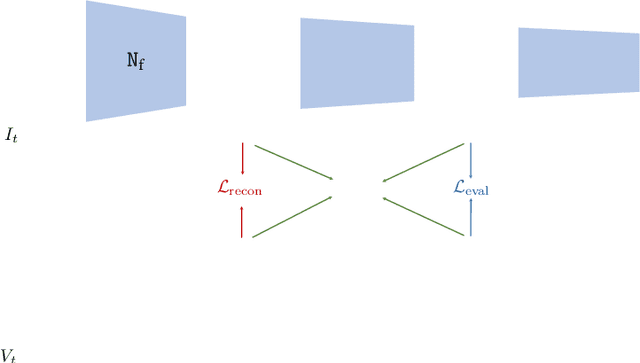
Novel vision sensors such as event cameras provide information that is not available from conventional intensity cameras. An obstacle to using these sensors with current powerful deep neural networks is the lack of large labeled training datasets. This paper proposes a Network Grafting Algorithm (NGA), where a new front end network driven by unconventional visual inputs replaces the front end network of a pretrained deep network that processes intensity frames. The self-supervised training uses only synchronously-recorded intensity frames and novel sensor data to maximize feature similarity between the pretrained network and the grafted network. We show that the enhanced grafted network reaches comparable average precision (AP$_{50}$) scores to the pretrained network on an object detection task using an event camera dataset, with no increase in inference costs. The grafted front end has only 5--8% of the total parameters and can be trained in a few hours on a single GPU equivalent to 5% of the time that would be needed to train the entire object detector from labeled data. NGA allows these new vision sensors to capitalize on previously pretrained powerful deep models, saving on training cost.
Character-level Chinese-English Translation through ASCII Encoding
Aug 27, 2018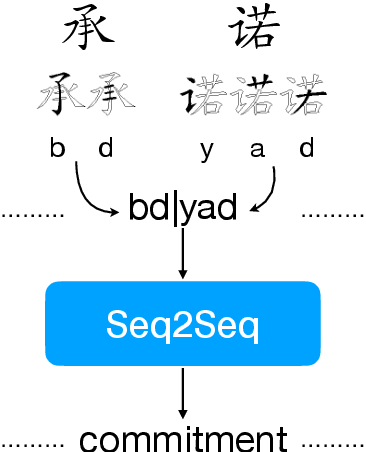
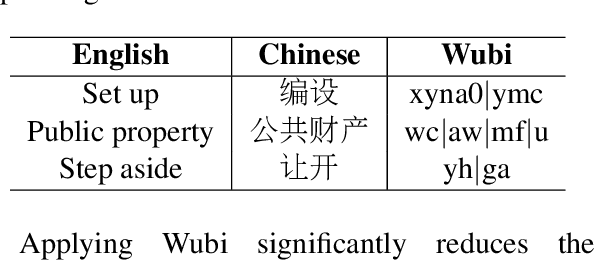
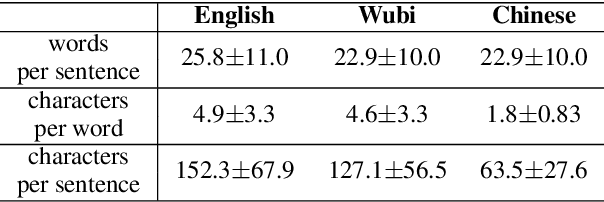
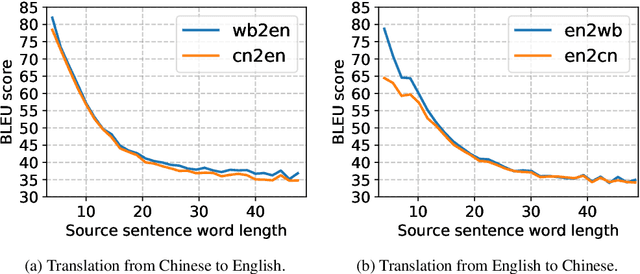
Character-level Neural Machine Translation (NMT) models have recently achieved impressive results on many language pairs. They mainly do well for Indo-European language pairs, where the languages share the same writing system. However, for translating between Chinese and English, the gap between the two different writing systems poses a major challenge because of a lack of systematic correspondence between the individual linguistic units. In this paper, we enable character-level NMT for Chinese, by breaking down Chinese characters into linguistic units similar to that of Indo-European languages. We use the Wubi encoding scheme, which preserves the original shape and semantic information of the characters, while also being reversible. We show promising results from training Wubi-based models on the character- and subword-level with recurrent as well as convolutional models.
Overcoming the vanishing gradient problem in plain recurrent networks
May 25, 2018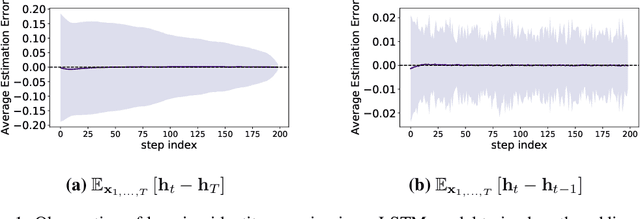
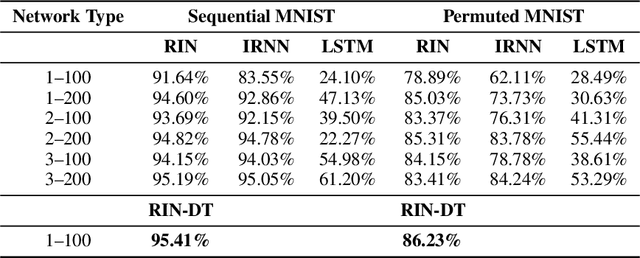
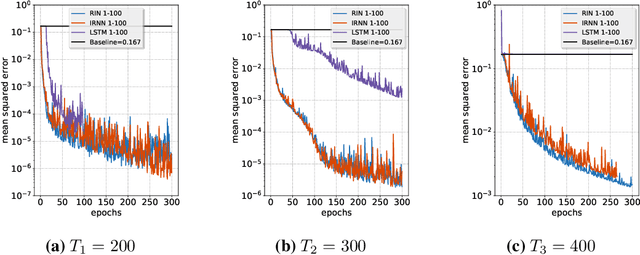

Plain recurrent networks greatly suffer from the vanishing gradient problem while Gated Neural Networks (GNNs) such as Long-short Term Memory (LSTM) and Gated Recurrent Unit (GRU) deliver promising results in many sequence learning tasks through sophisticated network designs. This paper shows how we can address this problem in a plain recurrent network by analyzing the gating mechanisms in GNNs. We propose a novel network called the Recurrent Identity Network (RIN) which allows a plain recurrent network to overcome the vanishing gradient problem while training very deep models without the use of gates. We compare this model with IRNNs and LSTMs on multiple sequence modeling benchmarks. The RINs demonstrate competitive performance and converge faster in all tasks. Notably, small RIN models produce 12%--67% higher accuracy on the Sequential and Permuted MNIST datasets and reach state-of-the-art performance on the bAbI question answering dataset.
Theory and Tools for the Conversion of Analog to Spiking Convolutional Neural Networks
Dec 13, 2016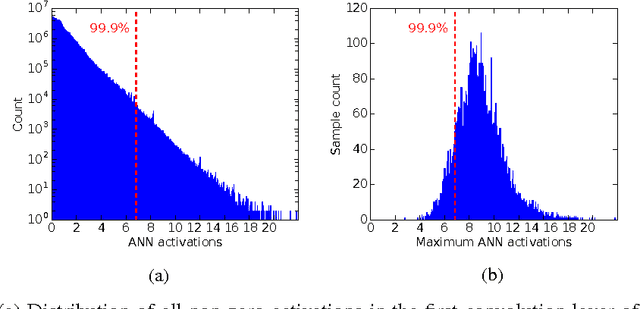

Deep convolutional neural networks (CNNs) have shown great potential for numerous real-world machine learning applications, but performing inference in large CNNs in real-time remains a challenge. We have previously demonstrated that traditional CNNs can be converted into deep spiking neural networks (SNNs), which exhibit similar accuracy while reducing both latency and computational load as a consequence of their data-driven, event-based style of computing. Here we provide a novel theory that explains why this conversion is successful, and derive from it several new tools to convert a larger and more powerful class of deep networks into SNNs. We identify the main sources of approximation errors in previous conversion methods, and propose simple mechanisms to fix these issues. Furthermore, we develop spiking implementations of common CNN operations such as max-pooling, softmax, and batch-normalization, which allow almost loss-less conversion of arbitrary CNN architectures into the spiking domain. Empirical evaluation of different network architectures on the MNIST and CIFAR10 benchmarks leads to the best SNN results reported to date.