 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteraction-Limited Safe Continuous-Time RL for Dynamical Medical Treatment
May 31, 2026Dynamic medical treatment requires deciding treatment intensity and intervention timing, while patient states evolve continuously and adverse events may occur between clinical interactions. Most existing treatment learning methods assume fixed schedules or enforce safety only at discrete decision points. We propose Interaction-Limited Safe Continuous-Time Reinforcement Learning, a framework that jointly optimizes treatment administration and clinical interaction timing under trajectory-level safety constraints. Our key idea is to reformulate the continuous time treatment problem as an option-based semi-Markov decision process, where each option specifies a continuous-time treatment policy and its duration. We develop a safety-tightening mechanism showing that suitably constructed constraints at interaction times guarantee safety over the full continuous-time trajectory with high probability. We further establish finite-sample guarantees for policy learning from logged treatment trajectories and introduce a practical data-driven conservative surrogate. Experiments show that the proposed adaptive interaction-timing mechanism improves both safety and treatment effectiveness over equidistant interaction schemes across different safe policy optimization methods.
MedGym:A Unified Continuous-Time Benchmark for Dynamic Medical Treatment Reinforcement Learning
May 31, 2026Medical treatment recommendation poses several challenges to reinforcement learning (RL): patient physiology evolves in continuous time, measurements and interventions are performed at irregular intervals, and treatment effects vary substantially across individuals. Existing RL formulations and simulated environments, however, are based on discrete-time MDP or POMDP abstractions with fixed or pre-specified decision intervals. Thus, it remains difficult to evaluate whether RL methods can handle time-interval-dependent disease progression, personalized treatment response, and safety between consecutive measurement points. To address this gap, we introduce MedGym, a benchmark environment for dynamic treatment recommendation. MedGym models longitudinal patient evolution in a continuous-time framework and constructs a configurable medical RL benchmark from clinical data by using Physics-Informed Neural Networks. The resulting benchmark supports both offline and online RL, and enables direct comparison between discrete-time and continuous-time methods under irregular treatment timing and patient-specific dynamics. Besides, MedGym supports evaluation from clinically important perspectives, including personalization, trajectory-level safety, and the performance gap between model-based offline learning and online deployment. By providing a standardized and configurable benchmark for continuous-time dynamic treatment, MedGym aims to facilitate more realistic and informative evaluation of medical RL methods.
FlexSQL: Flexible Exploration and Execution Make Better Text-to-SQL Agents
May 04, 2026Text-to-SQL over large analytical databases requires navigating complex schemas, resolving ambiguous queries, and grounding decisions in actual data. Most current systems follow a fixed pipeline where schema elements are retrieved once upfront and the database is only revisited for post-hoc repair, limiting recovery from early mistakes. We present FlexSQL, a text-to-SQL agent whose core design principle is flexible database interaction: the agent can explore schema structure, inspect data values, and run verification queries at any point during reasoning. FlexSQL generates diverse execution plans to cover multiple query interpretations, implements each plan in either SQL or Python depending on the task, and uses a two-tiered repair mechanism that can backtrack from code-level errors to plan-level revisions. On Spider2-Snow, using gpt-oss-120b, FlexSQL achieves a 65.4\% score, outperforming strong open-source baselines that use stronger, larger models such as gpt-o3 and DeepSeek-R1. When integrated into a general-purpose coding agent (as skills in Claude Code), our approach yields over 10\% relative improvement on Spider2-Snow. Further analysis shows that flexible exploration and flexible execution jointly contribute to the effectiveness of our approach, highlighting flexibility as a key design principle. Our code is available at: https://github.com/StringNLPLAB/FlexSQL
SpotIt+: Verification-based Text-to-SQL Evaluation with Database Constraints
Mar 04, 2026We present SpotIt+, an open-source tool for evaluating Text-to-SQL systems via bounded equivalence verification. Given a generated SQL query and the ground truth, SpotIt+ actively searches for database instances that differentiate the two queries. To ensure that the generated counterexamples reflect practically relevant discrepancies, we introduce a constraint-mining pipeline that combines rule-based specification mining over example databases with LLM-based validation. Experimental results on the BIRD dataset show that the mined constraints enable SpotIt+ to generate more realistic differentiating databases, while preserving its ability to efficiently uncover numerous discrepancies between generated and gold SQL queries that are missed by standard test-based evaluation.
Polygon: Symbolic Reasoning for SQL using Conflict-Driven Under-Approximation Search
Apr 09, 2025



We present a novel symbolic reasoning engine for SQL which can efficiently generate an input $I$ for $n$ queries $P_1, \cdots, P_n$, such that their outputs on $I$ satisfy a given property (expressed in SMT). This is useful in different contexts, such as disproving equivalence of two SQL queries and disambiguating a set of queries. Our first idea is to reason about an under-approximation of each $P_i$ -- that is, a subset of $P_i$'s input-output behaviors. While it makes our approach both semantics-aware and lightweight, this idea alone is incomplete (as a fixed under-approximation might miss some behaviors of interest). Therefore, our second idea is to perform search over an expressive family of under-approximations (which collectively cover all program behaviors of interest), thereby making our approach complete. We have implemented these ideas in a tool, Polygon, and evaluated it on over 30,000 benchmarks across two tasks (namely, SQL equivalence refutation and query disambiguation). Our evaluation results show that Polygon significantly outperforms all prior techniques.
Active operator inference for learning low-dimensional dynamical-system models from noisy data
Jul 26, 2021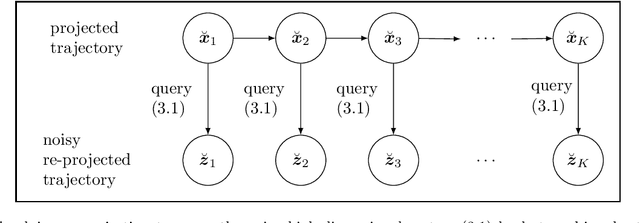

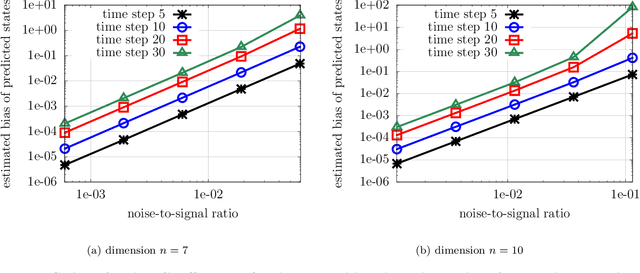
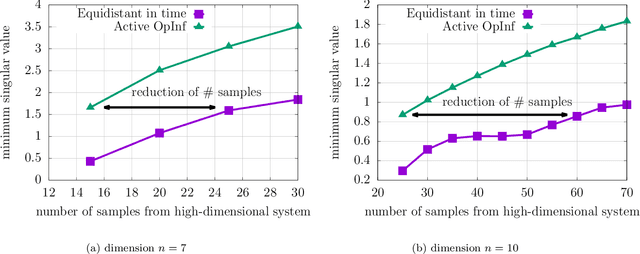
Noise poses a challenge for learning dynamical-system models because already small variations can distort the dynamics described by trajectory data. This work builds on operator inference from scientific machine learning to infer low-dimensional models from high-dimensional state trajectories polluted with noise. The presented analysis shows that, under certain conditions, the inferred operators are unbiased estimators of the well-studied projection-based reduced operators from traditional model reduction. Furthermore, the connection between operator inference and projection-based model reduction enables bounding the mean-squared errors of predictions made with the learned models with respect to traditional reduced models. The analysis also motivates an active operator inference approach that judiciously samples high-dimensional trajectories with the aim of achieving a low mean-squared error by reducing the effect of noise. Numerical experiments with high-dimensional linear and nonlinear state dynamics demonstrate that predictions obtained with active operator inference have orders of magnitude lower mean-squared errors than operator inference with traditional, equidistantly sampled trajectory data.