 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Detection: Multi-Scale Hidden-Code for Natural Image Deepfake Recovery and Factual Retrieval
Feb 26, 2026Recent advances in image authenticity have primarily focused on deepfake detection and localization, leaving recovery of tampered contents for factual retrieval relatively underexplored. We propose a unified hidden-code recovery framework that enables both retrieval and restoration from post-hoc and in-generation watermarking paradigms. Our method encodes semantic and perceptual information into a compact hidden-code representation, refined through multi-scale vector quantization, and enhances contextual reasoning via conditional Transformer modules. To enable systematic evaluation for natural images, we construct ImageNet-S, a benchmark that provides paired image-label factual retrieval tasks. Extensive experiments on ImageNet-S demonstrate that our method exhibits promising retrieval and reconstruction performance while remaining fully compatible with diverse watermarking pipelines. This framework establishes a foundation for general-purpose image recovery beyond detection and localization.
Adversarial Masked Autoencoder Purifier with Defense Transferability
Jan 28, 2025
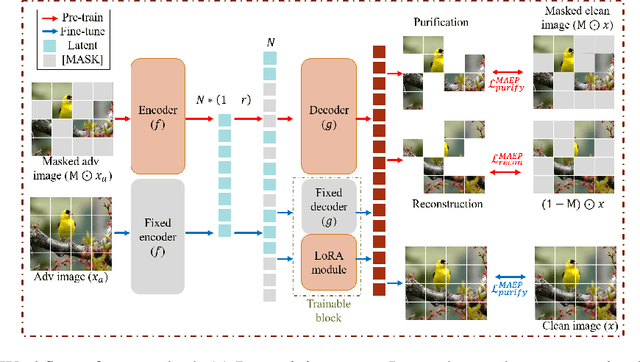
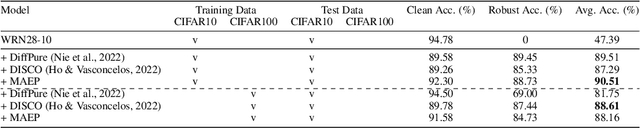
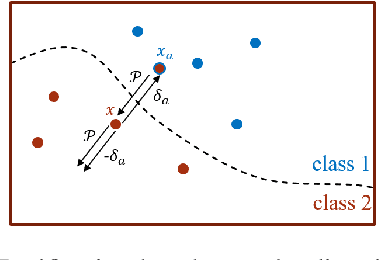
The study of adversarial defense still struggles to combat with advanced adversarial attacks. In contrast to most prior studies that rely on the diffusion model for test-time defense to remarkably increase the inference time, we propose Masked AutoEncoder Purifier (MAEP), which integrates Masked AutoEncoder (MAE) into an adversarial purifier framework for test-time purification. While MAEP achieves promising adversarial robustness, it particularly features model defense transferability and attack generalization without relying on using additional data that is different from the training dataset. To our knowledge, MAEP is the first study of adversarial purifier based on MAE. Extensive experimental results demonstrate that our method can not only maintain clear accuracy with only a slight drop but also exhibit a close gap between the clean and robust accuracy. Notably, MAEP trained on CIFAR10 achieves state-of-the-art performance even when tested directly on ImageNet, outperforming existing diffusion-based models trained specifically on ImageNet.