 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Scalable Neural Shortlisting-Reranking Approach for Large-Scale Domain Classification in Natural Language Understanding
Apr 22, 2018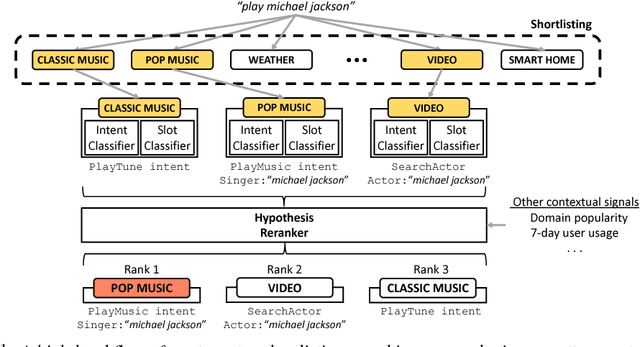
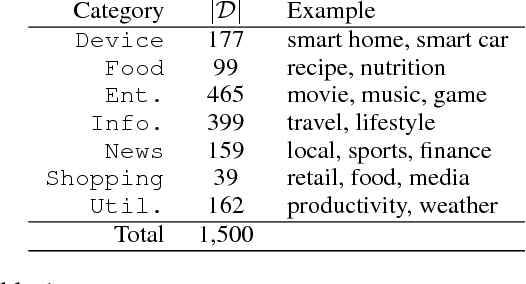
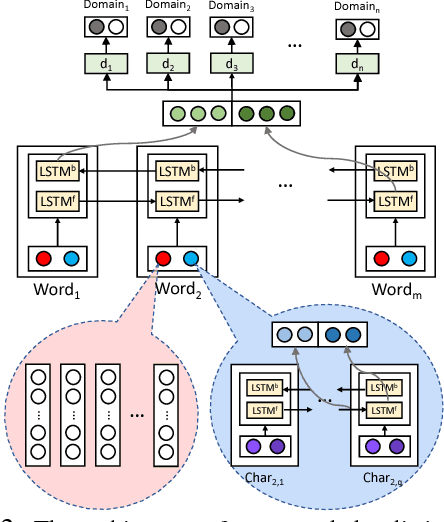
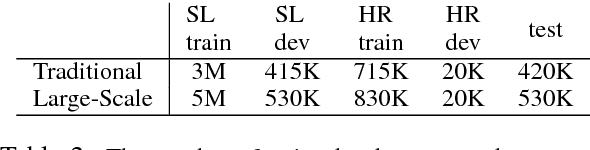
Intelligent personal digital assistants (IPDAs), a popular real-life application with spoken language understanding capabilities, can cover potentially thousands of overlapping domains for natural language understanding, and the task of finding the best domain to handle an utterance becomes a challenging problem on a large scale. In this paper, we propose a set of efficient and scalable neural shortlisting-reranking models for large-scale domain classification in IPDAs. The shortlisting stage focuses on efficiently trimming all domains down to a list of k-best candidate domains, and the reranking stage performs a list-wise reranking of the initial k-best domains with additional contextual information. We show the effectiveness of our approach with extensive experiments on 1,500 IPDA domains.
OneNet: Joint Domain, Intent, Slot Prediction for Spoken Language Understanding
Jan 16, 2018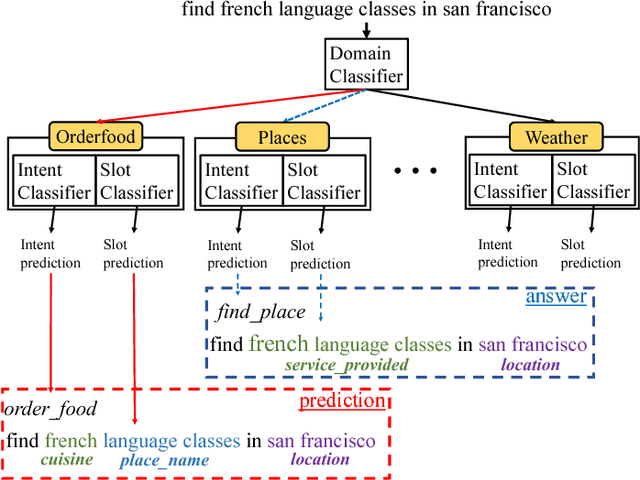

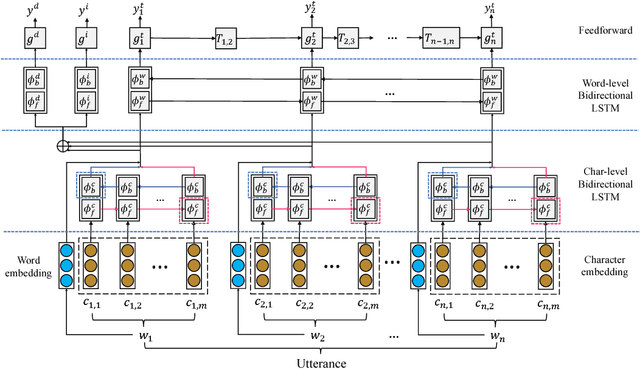

In practice, most spoken language understanding systems process user input in a pipelined manner; first domain is predicted, then intent and semantic slots are inferred according to the semantic frames of the predicted domain. The pipeline approach, however, has some disadvantages: error propagation and lack of information sharing. To address these issues, we present a unified neural network that jointly performs domain, intent, and slot predictions. Our approach adopts a principled architecture for multitask learning to fold in the state-of-the-art models for each task. With a few more ingredients, e.g. orthography-sensitive input encoding and curriculum training, our model delivered significant improvements in all three tasks across all domains over strong baselines, including one using oracle prediction for domain detection, on real user data of a commercial personal assistant.
Speaker-Sensitive Dual Memory Networks for Multi-Turn Slot Tagging
Nov 29, 2017
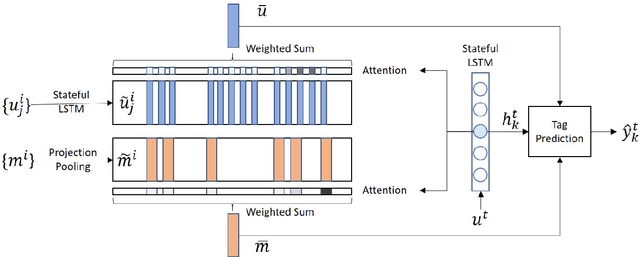
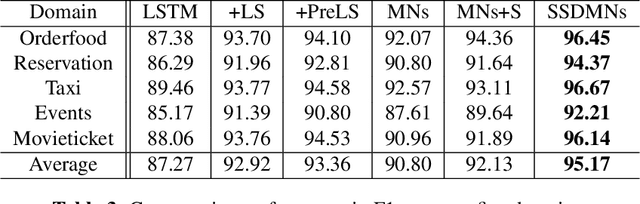
In multi-turn dialogs, natural language understanding models can introduce obvious errors by being blind to contextual information. To incorporate dialog history, we present a neural architecture with Speaker-Sensitive Dual Memory Networks which encode utterances differently depending on the speaker. This addresses the different extents of information available to the system - the system knows only the surface form of user utterances while it has the exact semantics of system output. We performed experiments on real user data from Microsoft Cortana, a commercial personal assistant. The result showed a significant performance improvement over the state-of-the-art slot tagging models using contextual information.