 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance-Specific Test-Time Training for Speech Editing in the Wild
Jun 16, 2025



Speech editing systems aim to naturally modify speech content while preserving acoustic consistency and speaker identity. However, previous studies often struggle to adapt to unseen and diverse acoustic conditions, resulting in degraded editing performance in real-world scenarios. To address this, we propose an instance-specific test-time training method for speech editing in the wild. Our approach employs direct supervision from ground-truth acoustic features in unedited regions, and indirect supervision in edited regions via auxiliary losses based on duration constraints and phoneme prediction. This strategy mitigates the bandwidth discontinuity problem in speech editing, ensuring smooth acoustic transitions between unedited and edited regions. Additionally, it enables precise control over speech rate by adapting the model to target durations via mask length adjustment during test-time training. Experiments on in-the-wild benchmark datasets demonstrate that our method outperforms existing speech editing systems in both objective and subjective evaluations.
Naturalness-Aware Curriculum Learning with Dynamic Temperature for Speech Deepfake Detection
May 20, 2025



Recent advances in speech deepfake detection (SDD) have significantly improved artifacts-based detection in spoofed speech. However, most models overlook speech naturalness, a crucial cue for distinguishing bona fide speech from spoofed speech. This study proposes naturalness-aware curriculum learning, a novel training framework that leverages speech naturalness to enhance the robustness and generalization of SDD. This approach measures sample difficulty using both ground-truth labels and mean opinion scores, and adjusts the training schedule to progressively introduce more challenging samples. To further improve generalization, a dynamic temperature scaling method based on speech naturalness is incorporated into the training process. A 23% relative reduction in the EER was achieved in the experiments on the ASVspoof 2021 DF dataset, without modifying the model architecture. Ablation studies confirmed the effectiveness of naturalness-aware training strategies for SDD tasks.
Period Singer: Integrating Periodic and Aperiodic Variational Autoencoders for Natural-Sounding End-to-End Singing Voice Synthesis
Jun 14, 2024

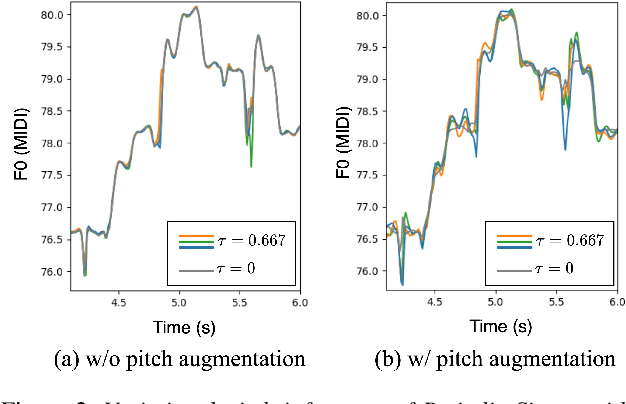

In this paper, we present Period Singer, a novel end-to-end singing voice synthesis (SVS) model that utilizes variational inference for periodic and aperiodic components, aimed at producing natural-sounding waveforms. Recent end-to-end SVS models have demonstrated the capability of synthesizing high-fidelity singing voices. However, owing to deterministic pitch conditioning, they do not fully address the one-to-many problem. To address this problem, we present the Period Singer architecture, which integrates variational autoencoders for the periodic and aperiodic components. Additionally, our methodology eliminates the dependency on an external aligner by estimating the phoneme alignment through a monotonic alignment search within note boundaries. Our empirical evaluations show that Period Singer outperforms existing end-to-end SVS models on Mandarin and Korean datasets. The efficacy of the proposed method was further corroborated by ablation studies.
Distinctive-attribute Extraction for Image Captioning
Jul 25, 2018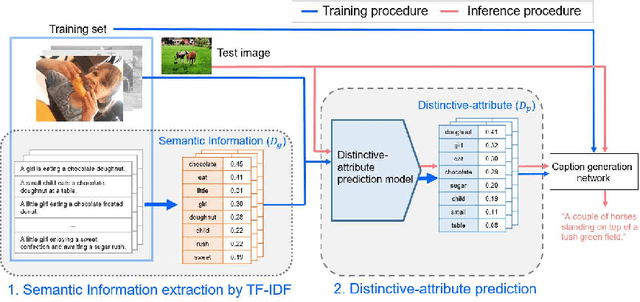
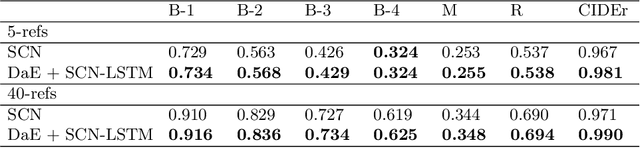

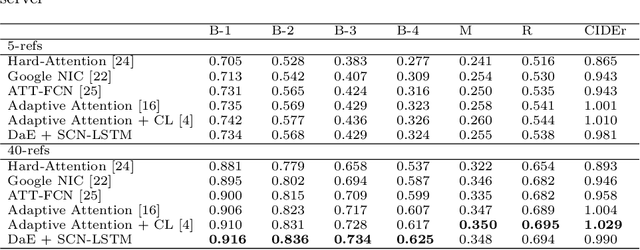
Image captioning, an open research issue, has been evolved with the progress of deep neural networks. Convolutional neural networks (CNNs) and recurrent neural networks (RNNs) are employed to compute image features and generate natural language descriptions in the research. In previous works, a caption involving semantic description can be generated by applying additional information into the RNNs. In this approach, we propose a distinctive-attribute extraction (DaE) which explicitly encourages significant meanings to generate an accurate caption describing the overall meaning of the image with their unique situation. Specifically, the captions of training images are analyzed by term frequency-inverse document frequency (TF-IDF), and the analyzed semantic information is trained to extract distinctive-attributes for inferring captions. The proposed scheme is evaluated on a challenge data, and it improves an objective performance while describing images in more detail.