 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaze-Guided Learning: Avoiding Shortcut Bias in Visual Classification
Apr 08, 2025



Inspired by human visual attention, deep neural networks have widely adopted attention mechanisms to learn locally discriminative attributes for challenging visual classification tasks. However, existing approaches primarily emphasize the representation of such features while neglecting their precise localization, which often leads to misclassification caused by shortcut biases. This limitation becomes even more pronounced when models are evaluated on transfer or out-of-distribution datasets. In contrast, humans are capable of leveraging prior object knowledge to quickly localize and compare fine-grained attributes, a capability that is especially crucial in complex and high-variance classification scenarios. Motivated by this, we introduce Gaze-CIFAR-10, a human gaze time-series dataset, along with a dual-sequence gaze encoder that models the precise sequential localization of human attention on distinct local attributes. In parallel, a Vision Transformer (ViT) is employed to learn the sequential representation of image content. Through cross-modal fusion, our framework integrates human gaze priors with machine-derived visual sequences, effectively correcting inaccurate localization in image feature representations. Extensive qualitative and quantitative experiments demonstrate that gaze-guided cognitive cues significantly enhance classification accuracy.
Learning by Erasing: Conditional Entropy based Transferable Out-Of-Distribution Detection
Apr 23, 2022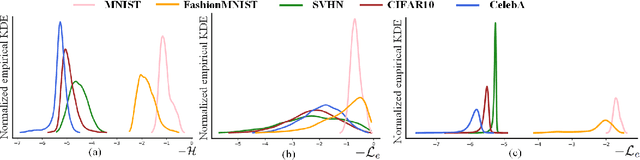

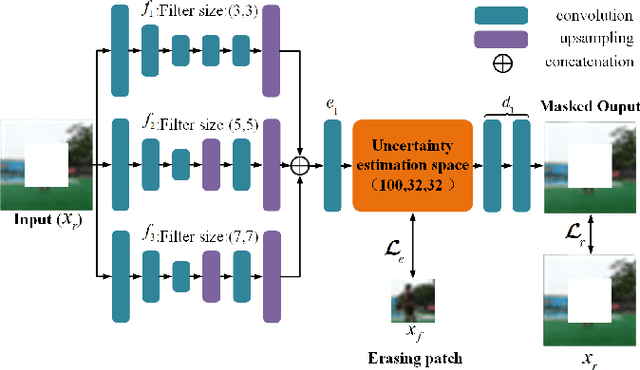
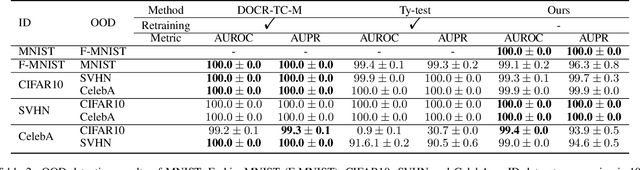
Out-of-distribution (OOD) detection is essential to handle the distribution shifts between training and test scenarios. For a new in-distribution (ID) dataset, existing methods require retraining to capture the dataset-specific feature representation or data distribution. In this paper, we propose a deep generative models (DGM) based transferable OOD detection method, which is unnecessary to retrain on a new ID dataset. We design an image erasing strategy to equip exclusive conditional entropy distribution for each ID dataset, which determines the discrepancy of DGM's posteriori ucertainty distribution on different ID datasets. Owing to the powerful representation capacity of convolutional neural networks, the proposed model trained on complex dataset can capture the above discrepancy between ID datasets without retraining and thus achieve transferable OOD detection. We validate the proposed method on five datasets and verity that ours achieves comparable performance to the state-of-the-art group based OOD detection methods that need to be retrained to deploy on new ID datasets. Our code is available at https://github.com/oOHCIOo/CETOOD.