 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Retrieval for Stable and Predictable Ad Recommendations
May 21, 2026Traditional ads recommendation systems have primarily focused on optimizing for prediction accuracy of click or conversion events using canonical metrics such as recall or normalized discounted cumulative gain (NDCG). With the hyper-growth of ads inventory and liquidity with generative AI technologies, the prediction stability and predictability is becoming increasingly critical. Intuitively, prediction stability and predictability can be defined to quantify system robustness with respect to minor/noisy input (ads, creatives) perturbations, the lack of which could lead to advertiser perceivable problems such as repeatability, cold start and under-exploration. In this paper, we introduce a new evaluation framework for quantifying stability and predictability of an ads recommender system, and present an online validated semantic candidate generation framework powered by fine-tuned Large Language Models (LLMs) that showed significant improvement along these metrics by fundamentally improving the semantic-awareness of the system. The approach extracts hierarchical semantic attributes from ad creatives to obtain LLM representations, which serve as the foundation for graph-based expansion, ensuring the retrieved candidates encapsulate semantic variants of an ad, guaranteeing that small creative variants from the advertiser yield consistent and explainable delivery results to the user. We tested this LLM ads retrieval framework in a large-scale industrial ads recommendation system, demonstrating significant improvements across offline and online A/B experiments, showcasing gains in both predictability and traditional performance metrics. Although evaluated in the ads stack, this is a general framework that can be applied broadly to any large-scale recommendation and retrieval systems facing similar scaling and predictability challenges.
Learning to Charge More: A Theoretical Study of Collusion by Q-Learning Agents
May 28, 2025There is growing experimental evidence that $Q$-learning agents may learn to charge supracompetitive prices. We provide the first theoretical explanation for this behavior in infinite repeated games. Firms update their pricing policies based solely on observed profits, without computing equilibrium strategies. We show that when the game admits both a one-stage Nash equilibrium price and a collusive-enabling price, and when the $Q$-function satisfies certain inequalities at the end of experimentation, firms learn to consistently charge supracompetitive prices. We introduce a new class of one-memory subgame perfect equilibria (SPEs) and provide conditions under which learned behavior is supported by naive collusion, grim trigger policies, or increasing strategies. Naive collusion does not constitute an SPE unless the collusive-enabling price is a one-stage Nash equilibrium, whereas grim trigger policies can.
Artificial Intelligence and Algorithmic Price Collusion in Two-sided Markets
Jul 04, 2024



Algorithmic price collusion facilitated by artificial intelligence (AI) algorithms raises significant concerns. We examine how AI agents using Q-learning engage in tacit collusion in two-sided markets. Our experiments reveal that AI-driven platforms achieve higher collusion levels compared to Bertrand competition. Increased network externalities significantly enhance collusion, suggesting AI algorithms exploit them to maximize profits. Higher user heterogeneity or greater utility from outside options generally reduce collusion, while higher discount rates increase it. Tacit collusion remains feasible even at low discount rates. To mitigate collusive behavior and inform potential regulatory measures, we propose incorporating a penalty term in the Q-learning algorithm.
The effect of Leaky ReLUs on the training and generalization of overparameterized networks
Feb 25, 2024



We investigate the training and generalization errors of overparameterized neural networks (NNs) with a wide class of leaky rectified linear unit (ReLU) functions. More specifically, we carefully upper bound both the convergence rate of the training error and the generalization error of such NNs and investigate the dependence of these bounds on the Leaky ReLU parameter, $\alpha$. We show that $\alpha =-1$, which corresponds to the absolute value activation function, is optimal for the training error bound. Furthermore, in special settings, it is also optimal for the generalization error bound. Numerical experiments empirically support the practical choices guided by the theory.
An Unpooling Layer for Graph Generation
Jun 04, 2022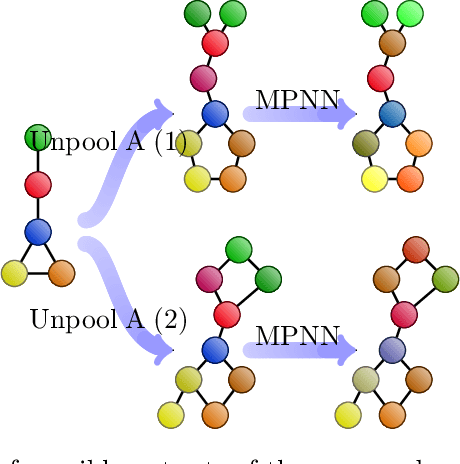
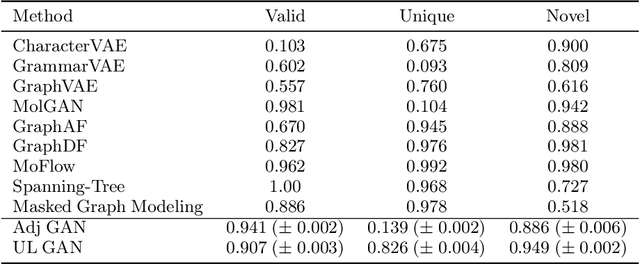
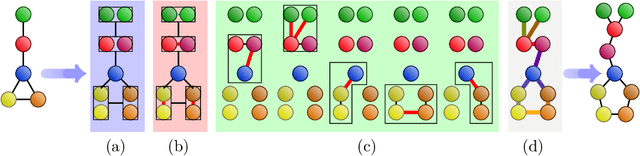
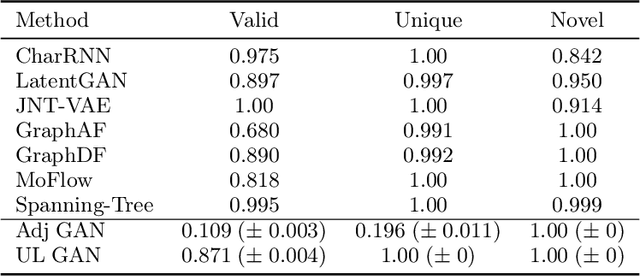
We propose a novel and trainable graph unpooling layer for effective graph generation. Given a graph with features, the unpooling layer enlarges this graph and learns its desired new structure and features. Since this unpooling layer is trainable, it can be applied to graph generation either in the decoder of a variational autoencoder or in the generator of a generative adversarial network (GAN). We prove that the unpooled graph remains connected and any connected graph can be sequentially unpooled from a 3-nodes graph. We apply the unpooling layer within the GAN generator. Since the most studied instance of graph generation is molecular generation, we test our ideas in this context. Using the QM9 and ZINC datasets, we demonstrate the improvement obtained by using the unpooling layer instead of an adjacency-matrix-based approach.