 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStarting with data: advancing spatial data science by building and sharing high-quality datasets
Jul 16, 2020Spatial data science has emerged in recent years as an interdisciplinary field. This position paper discusses the importance of building and sharing high-quality datasets for spatial data science.
Are We There Yet? Evaluating State-of-the-Art Neural Network based Geoparsers Using EUPEG as a Benchmarking Platform
Jul 15, 2020
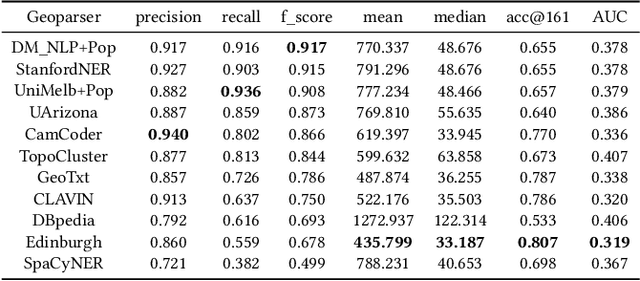
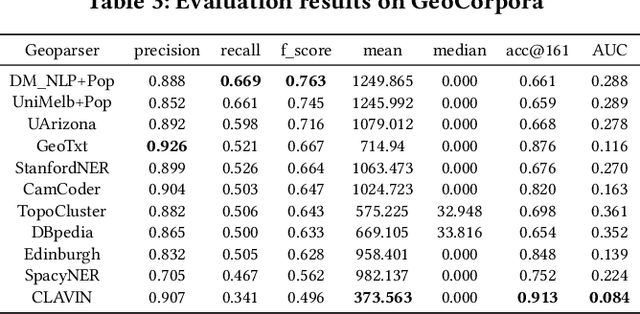
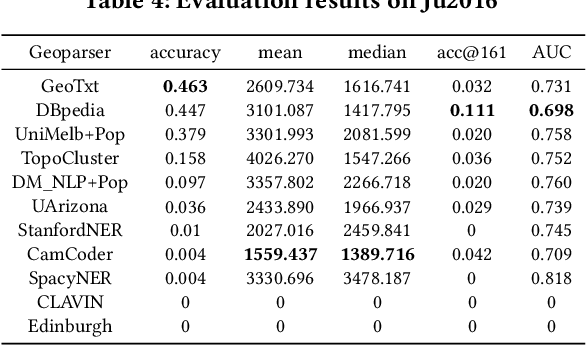
Geoparsing is an important task in geographic information retrieval. A geoparsing system, known as a geoparser, takes some texts as the input and outputs the recognized place mentions and their location coordinates. In June 2019, a geoparsing competition, Toponym Resolution in Scientific Papers, was held as one of the SemEval 2019 tasks. The winning teams developed neural network based geoparsers that achieved outstanding performances (over 90% precision, recall, and F1 score for toponym recognition). This exciting result brings the question "are we there yet?", namely have we achieved high enough performances to possibly consider the problem of geoparsing as solved? One limitation of this competition is that the developed geoparsers were tested on only one dataset which has 45 research articles collected from the particular domain of Bio-medicine. It is known that the same geoparser can have very different performances on different datasets. Thus, this work performs a systematic evaluation of these state-of-the-art geoparsers using our recently developed benchmarking platform EUPEG that has eight annotated datasets, nine baseline geoparsers, and eight performance metrics. The evaluation result suggests that these new geoparsers indeed improve the performances of geoparsing on multiple datasets although some challenges remain.
Artificial Intelligence Approaches
Aug 27, 2019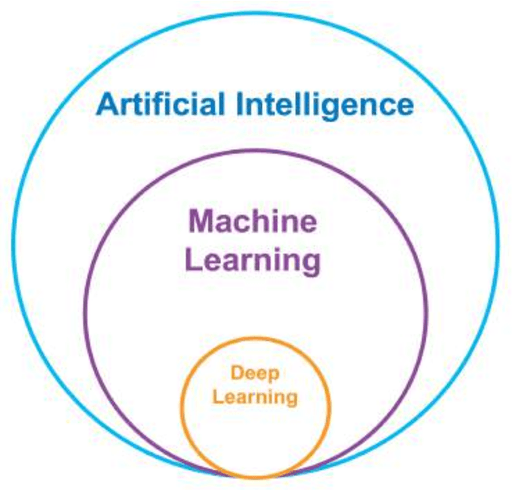

Artificial Intelligence (AI) has received tremendous attention from academia, industry, and the general public in recent years. The integration of geography and AI, or GeoAI, provides novel approaches for addressing a variety of problems in the natural environment and our human society. This entry briefly reviews the recent development of AI with a focus on machine learning and deep learning approaches. We discuss the integration of AI with geography and particularly geographic information science, and present a number of GeoAI applications and possible future directions.
* 12 pages, 5 figures
Geo-Text Data and Data-Driven Geospatial Semantics
Sep 15, 2018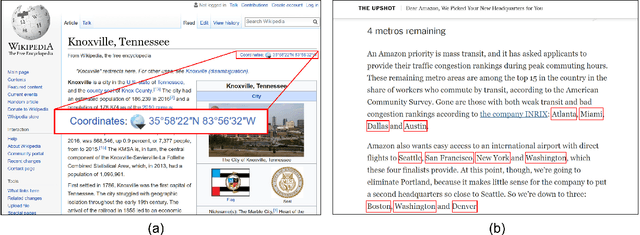
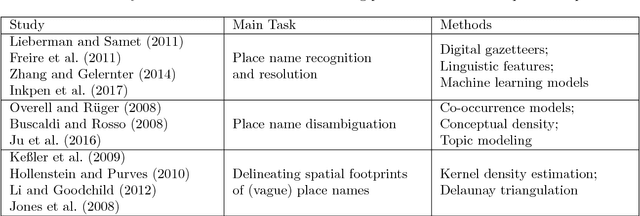

Many datasets nowadays contain links between geographic locations and natural language texts. These links can be geotags, such as geotagged tweets or geotagged Wikipedia pages, in which location coordinates are explicitly attached to texts. These links can also be place mentions, such as those in news articles, travel blogs, or historical archives, in which texts are implicitly connected to the mentioned places. This kind of data is referred to as geo-text data. The availability of large amounts of geo-text data brings both challenges and opportunities. On the one hand, it is challenging to automatically process this kind of data due to the unstructured texts and the complex spatial footprints of some places. On the other hand, geo-text data offers unique research opportunities through the rich information contained in texts and the special links between texts and geography. As a result, geo-text data facilitates various studies especially those in data-driven geospatial semantics. This paper discusses geo-text data and related concepts. With a focus on data-driven research, this paper systematically reviews a large number of studies that have discovered multiple types of knowledge from geo-text data. Based on the literature review, a generalized workflow is extracted and key challenges for future work are discussed.
Extracting and Analyzing Semantic Relatedness between Cities Using News Articles
Sep 08, 2018
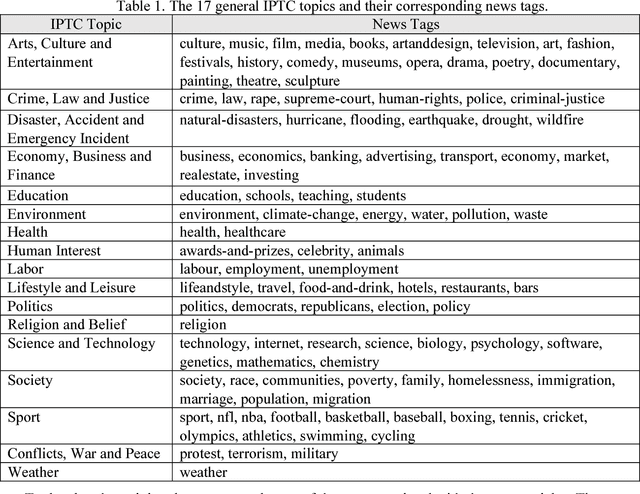
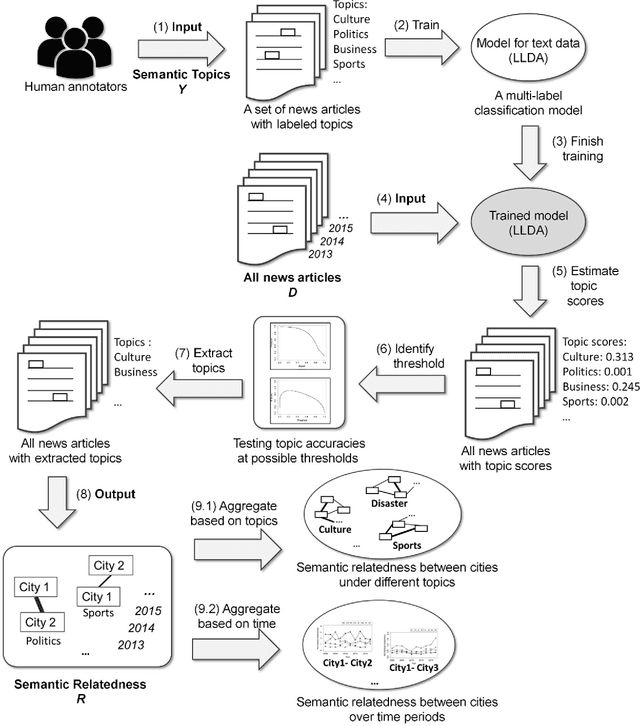
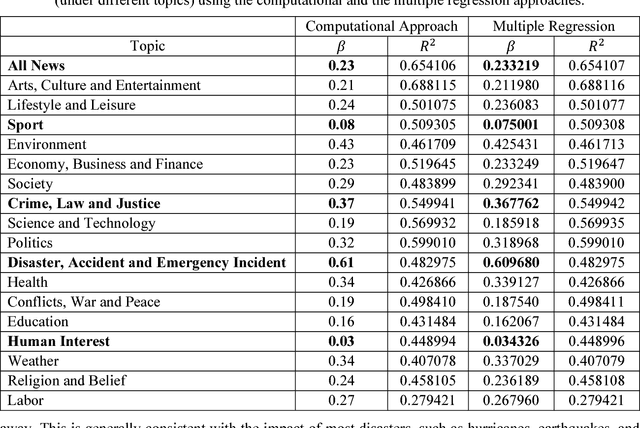
News articles capture a variety of topics about our society. They reflect not only the socioeconomic activities that happened in our physical world, but also some of the cultures, human interests, and public concerns that exist only in the perceptions of people. Cities are frequently mentioned in news articles, and two or more cities may co-occur in the same article. Such co-occurrence often suggests certain relatedness between the mentioned cities, and the relatedness may be under different topics depending on the contents of the news articles. We consider the relatedness under different topics as semantic relatedness. By reading news articles, one can grasp the general semantic relatedness between cities, yet, given hundreds of thousands of news articles, it is very difficult, if not impossible, for anyone to manually read them. This paper proposes a computational framework which can "read" a large number of news articles and extract the semantic relatedness between cities. This framework is based on a natural language processing model and employs a machine learning process to identify the main topics of news articles. We describe the overall structure of this framework and its individual modules, and then apply it to an experimental dataset with more than 500,000 news articles covering the top 100 U.S. cities spanning a 10-year period. We perform exploratory visualization of the extracted semantic relatedness under different topics and over multiple years. We also analyze the impact of geographic distance on semantic relatedness and find varied distance decay effects. The proposed framework can be used to support large-scale content analysis in city network research.
An empirical study on the names of points of interest and their changes with geographic distance
Jun 21, 2018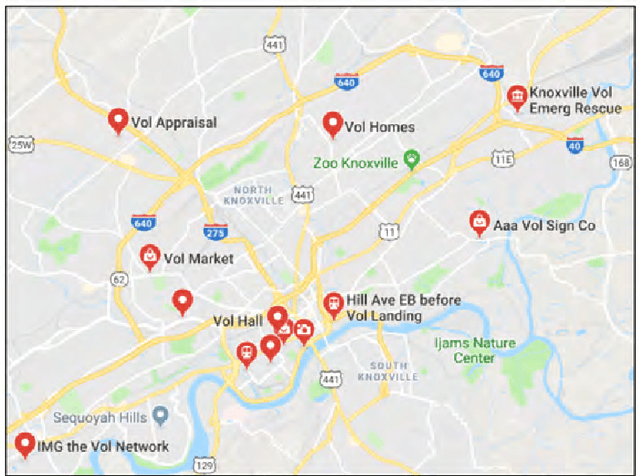
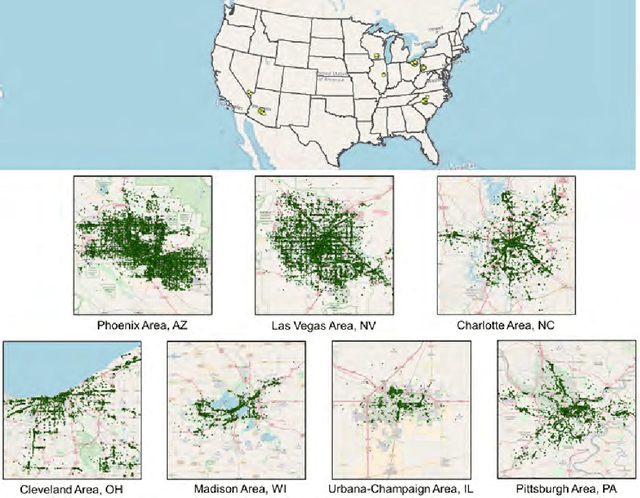
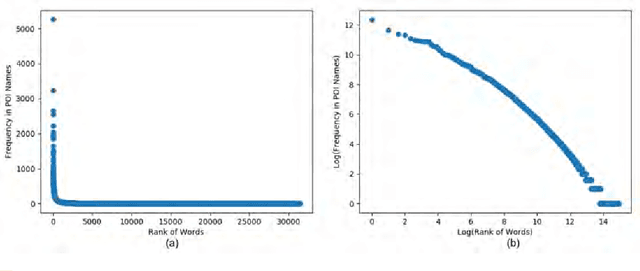

While Points Of Interest (POIs), such as restaurants, hotels, and barber shops, are part of urban areas irrespective of their specific locations, the names of these POIs often reveal valuable information related to local culture, landmarks, influential families, figures, events, and so on. Place names have long been studied by geographers, e.g., to understand their origins and relations to family names. However, there is a lack of large-scale empirical studies that examine the localness of place names and their changes with geographic distance. In addition to enhancing our understanding of the coherence of geographic regions, such empirical studies are also significant for geographic information retrieval where they can inform computational models and improve the accuracy of place name disambiguation. In this work, we conduct an empirical study based on 112,071 POIs in seven US metropolitan areas extracted from an open Yelp dataset. We propose to adopt term frequency and inverse document frequency in geographic contexts to identify local terms used in POI names and to analyze their usages across different POI types. Our results show an uneven usage of local terms across POI types, which is highly consistent among different geographic regions. We also examine the decaying effect of POI name similarity with the increase of distance among POIs. While our analysis focuses on urban POI names, the presented methods can be generalized to other place types as well, such as mountain peaks and streets.
Geospatial Semantics
Aug 10, 2017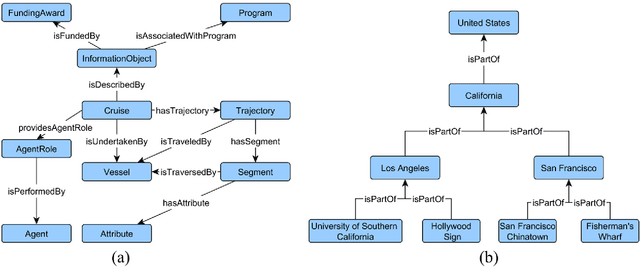
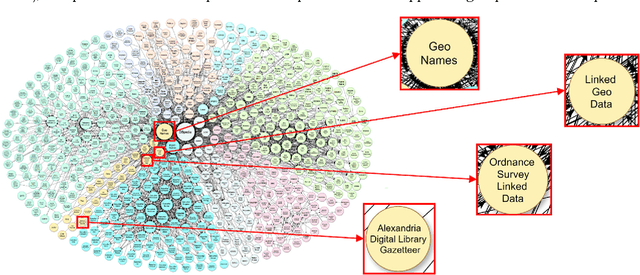

Geospatial semantics is a broad field that involves a variety of research areas. The term semantics refers to the meaning of things, and is in contrast with the term syntactics. Accordingly, studies on geospatial semantics usually focus on understanding the meaning of geographic entities as well as their counterparts in the cognitive and digital world, such as cognitive geographic concepts and digital gazetteers. Geospatial semantics can also facilitate the design of geographic information systems (GIS) by enhancing the interoperability of distributed systems and developing more intelligent interfaces for user interactions. During the past years, a lot of research has been conducted, approaching geospatial semantics from different perspectives, using a variety of methods, and targeting different problems. Meanwhile, the arrival of big geo data, especially the large amount of unstructured text data on the Web, and the fast development of natural language processing methods enable new research directions in geospatial semantics. This chapter, therefore, provides a systematic review on the existing geospatial semantic research. Six major research areas are identified and discussed, including semantic interoperability, digital gazetteers, geographic information retrieval, geospatial Semantic Web, place semantics, and cognitive geographic concepts.