 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Context, Not Parameters: Training a Compact 7B Language Model for Efficient Long-Context Processing
May 13, 2025We present MegaBeam-Mistral-7B, a language model that supports 512K-token context length. Our work addresses practical limitations in long-context training, supporting real-world tasks such as compliance monitoring and verification. Evaluated on three long-context benchmarks, our 7B-parameter model demonstrates superior in-context learning performance on HELMET and robust retrieval and tracing capability on RULER. It is currently the only open model to achieve competitive long-range reasoning on BABILong at 512K context length without RAG or targeted fine-tuning. Released as fully open source under the Apache 2.0 license, the model has been downloaded over 100,000 times on Hugging Face. Model available at: https://huggingface.co/aws-prototyping/MegaBeam-Mistral-7B-512k
Learning from Drivers to Tackle the Amazon Last Mile Routing Research Challenge
May 10, 2022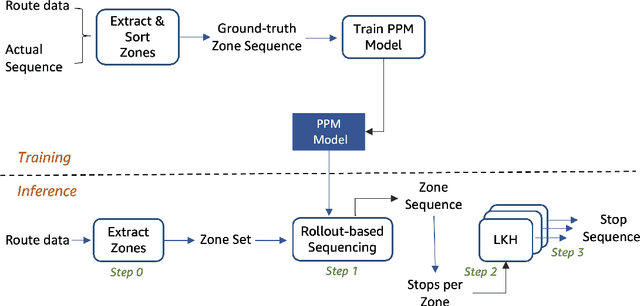
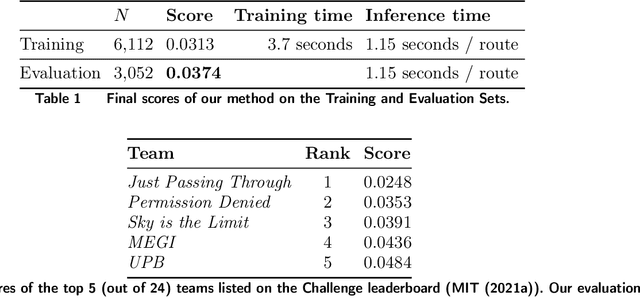
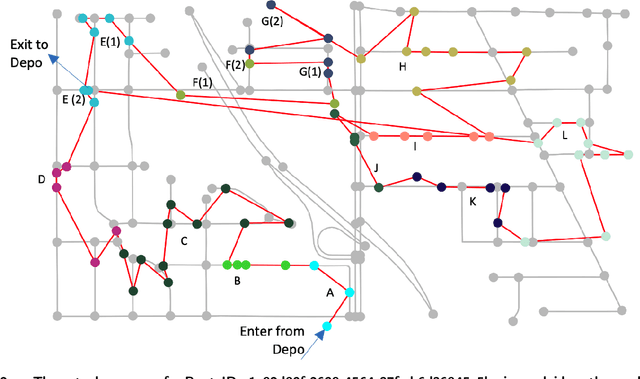
The goal of the Amazon Last Mile Routing Research Challenge is to integrate the real-life experience of Amazon drivers into the solution of optimal route planning and optimization. This paper presents our method that tackles this challenge by hierarchically combining machine learning and conventional Traveling Salesperson Problem (TSP) solvers. Our method reaps the benefits from both worlds. On the one hand, our method encodes driver know-how by learning a sequential probability model from historical routes at the zone level, where each zone contains a few parcel stops. It then uses a single step policy iteration method, known as the Rollout algorithm, to generate plausible zone sequences sampled from the learned probability model. On the other hand, our method utilizes proven methods developed in the rich TSP literature to sequence stops within each zone efficiently. The outcome of such a combination appeared to be promising. Our method obtained an evaluation score of $0.0374$, which is comparable to what the top three teams have achieved on the official Challenge leaderboard. Moreover, our learning-based method is applicable to driving routes that may exhibit distinct sequential patterns beyond the scope of this Challenge. The source code of our method is publicly available at https://github.com/aws-samples/amazon-sagemaker-amazon-routing-challenge-sol
Learning Hidden Structures with Relational Models by Adequately Involving Rich Information in A Network
Oct 06, 2013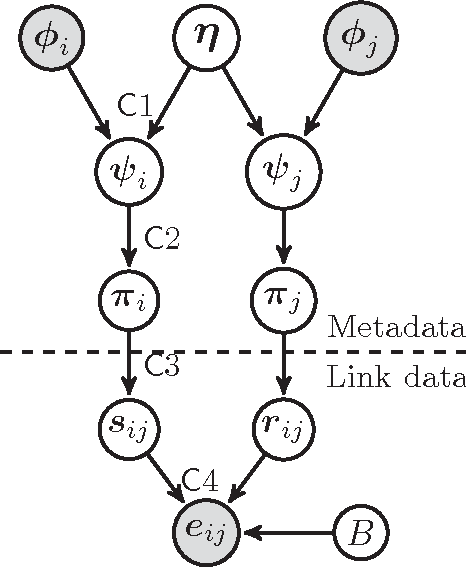
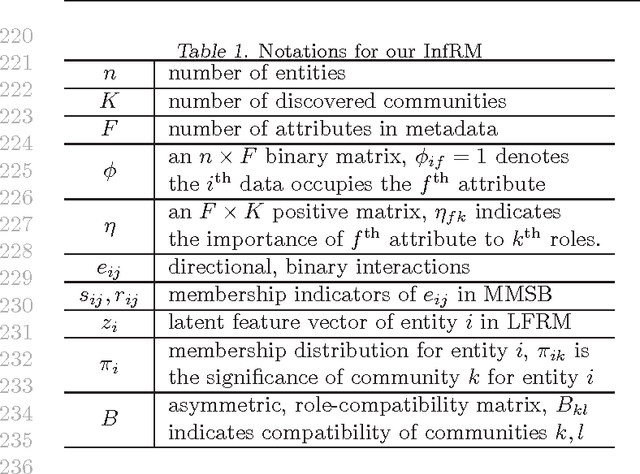

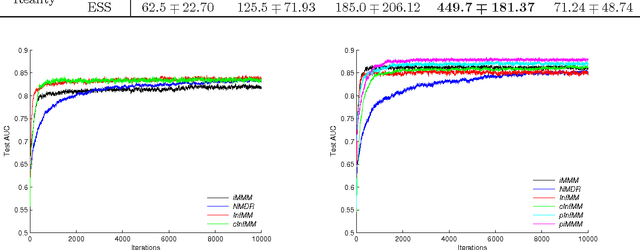
Effectively modelling hidden structures in a network is very practical but theoretically challenging. Existing relational models only involve very limited information, namely the binary directional link data, embedded in a network to learn hidden networking structures. There is other rich and meaningful information (e.g., various attributes of entities and more granular information than binary elements such as "like" or "dislike") missed, which play a critical role in forming and understanding relations in a network. In this work, we propose an informative relational model (InfRM) framework to adequately involve rich information and its granularity in a network, including metadata information about each entity and various forms of link data. Firstly, an effective metadata information incorporation method is employed on the prior information from relational models MMSB and LFRM. This is to encourage the entities with similar metadata information to have similar hidden structures. Secondly, we propose various solutions to cater for alternative forms of link data. Substantial efforts have been made towards modelling appropriateness and efficiency, for example, using conjugate priors. We evaluate our framework and its inference algorithms in different datasets, which shows the generality and effectiveness of our models in capturing implicit structures in networks.
Characterizing A Database of Sequential Behaviors with Latent Dirichlet Hidden Markov Models
May 24, 2013



This paper proposes a generative model, the latent Dirichlet hidden Markov models (LDHMM), for characterizing a database of sequential behaviors (sequences). LDHMMs posit that each sequence is generated by an underlying Markov chain process, which are controlled by the corresponding parameters (i.e., the initial state vector, transition matrix and the emission matrix). These sequence-level latent parameters for each sequence are modeled as latent Dirichlet random variables and parameterized by a set of deterministic database-level hyper-parameters. Through this way, we expect to model the sequence in two levels: the database level by deterministic hyper-parameters and the sequence-level by latent parameters. To learn the deterministic hyper-parameters and approximate posteriors of parameters in LDHMMs, we propose an iterative algorithm under the variational EM framework, which consists of E and M steps. We examine two different schemes, the fully-factorized and partially-factorized forms, for the framework, based on different assumptions. We present empirical results of behavior modeling and sequence classification on three real-world data sets, and compare them to other related models. The experimental results prove that the proposed LDHMMs produce better generalization performance in terms of log-likelihood and deliver competitive results on the sequence classification problem.