 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-iterative recomputation of dense layers for performance improvement of DCNN
Sep 14, 2018


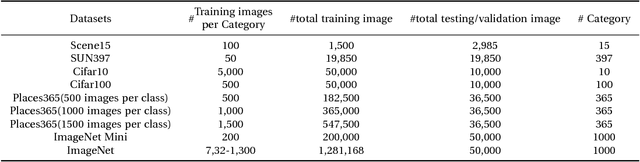
An iterative method of learning has become a paradigm for training deep convolutional neural networks (DCNN). However, utilizing a non-iterative learning strategy can accelerate the training process of the DCNN and surprisingly such approach has been rarely explored by the deep learning (DL) community. It motivates this paper to introduce a non-iterative learning strategy that eliminates the backpropagation (BP) at the top dense or fully connected (FC) layers of DCNN, resulting in, lower training time and higher performance. The proposed method exploits the Moore-Penrose Inverse to pull back the current residual error to each FC layer, generating well-generalized features. Then using the recomputed features, i.e., the new generalized features the weights of each FC layer is computed according to the Moore-Penrose Inverse. We evaluate the proposed approach on six widely accepted object recognition benchmark datasets: Scene-15, CIFAR-10, CIFAR-100, SUN-397, Places365, and ImageNet. The experimental results show that the proposed method obtains significant improvements over 30 state-of-the-art methods. Interestingly, it also indicates that any DCNN with the proposed method can provide better performance than the same network with its original training based on BP.
Pulling back error to the hidden-node parameter technology: Single-hidden-layer feedforward network without output weight
May 06, 2014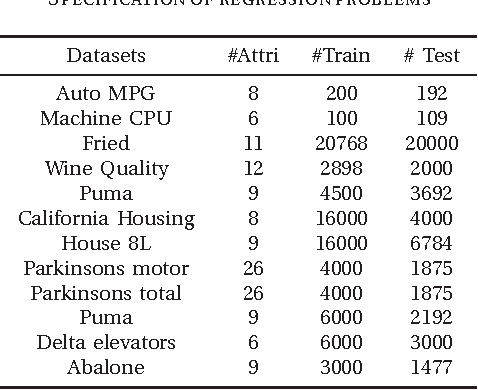
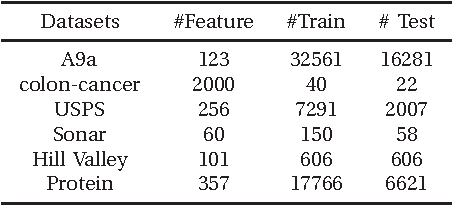
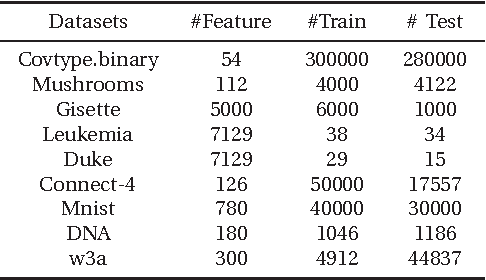
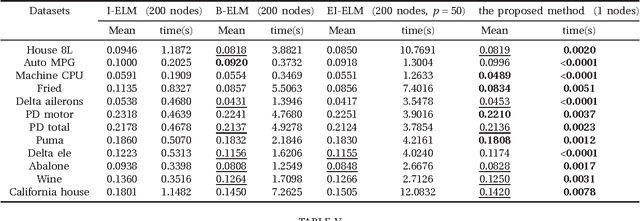
According to conventional neural network theories, the feature of single-hidden-layer feedforward neural networks(SLFNs) resorts to parameters of the weighted connections and hidden nodes. SLFNs are universal approximators when at least the parameters of the networks including hidden-node parameter and output weight are exist. Unlike above neural network theories, this paper indicates that in order to let SLFNs work as universal approximators, one may simply calculate the hidden node parameter only and the output weight is not needed at all. In other words, this proposed neural network architecture can be considered as a standard SLFNs with fixing output weight equal to an unit vector. Further more, this paper presents experiments which show that the proposed learning method tends to extremely reduce network output error to a very small number with only 1 hidden node. Simulation results demonstrate that the proposed method can provide several to thousands of times faster than other learning algorithm including BP, SVM/SVR and other ELM methods.