 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLASPA: Latent Spatial Alignment for Fast Training-free Single Image Editing
Mar 19, 2024We present a novel, training-free approach for textual editing of real images using diffusion models. Unlike prior methods that rely on computationally expensive finetuning, our approach leverages LAtent SPatial Alignment (LASPA) to efficiently preserve image details. We demonstrate how the diffusion process is amenable to spatial guidance using a reference image, leading to semantically coherent edits. This eliminates the need for complex optimization and costly model finetuning, resulting in significantly faster editing compared to previous methods. Additionally, our method avoids the storage requirements associated with large finetuned models. These advantages make our approach particularly well-suited for editing on mobile devices and applications demanding rapid response times. While simple and fast, our method achieves 62-71\% preference in a user-study and significantly better model-based editing strength and image preservation scores.
Disentangled Image Generation Through Structured Noise Injection
May 05, 2020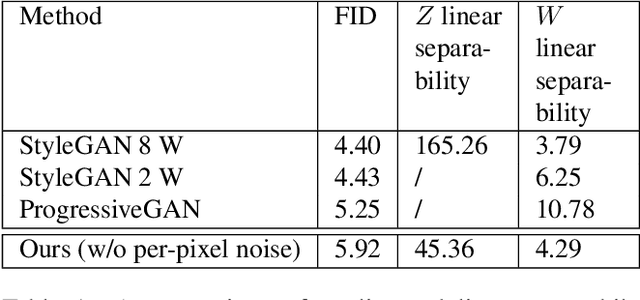
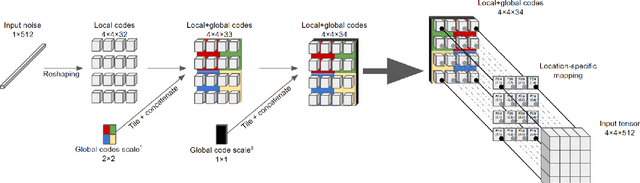
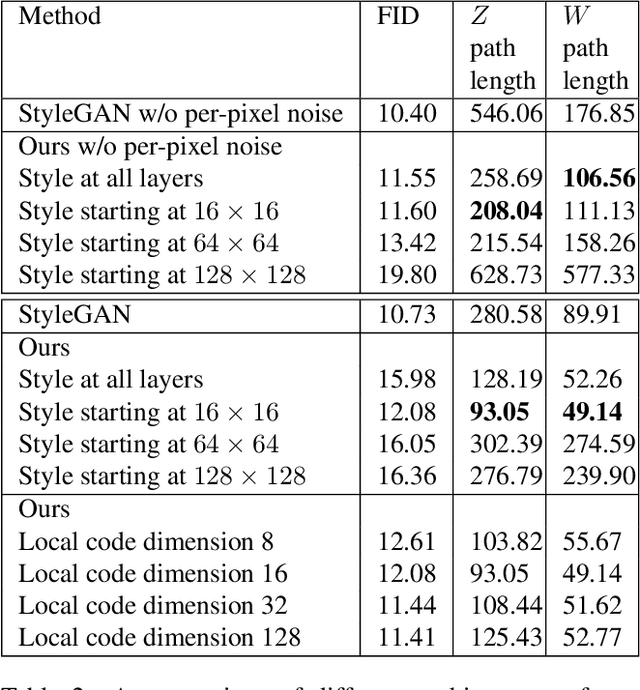
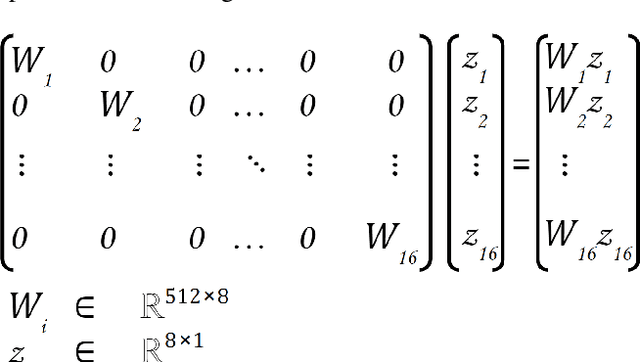
We explore different design choices for injecting noise into generative adversarial networks (GANs) with the goal of disentangling the latent space. Instead of traditional approaches, we propose feeding multiple noise codes through separate fully-connected layers respectively. The aim is restricting the influence of each noise code to specific parts of the generated image. We show that disentanglement in the first layer of the generator network leads to disentanglement in the generated image. Through a grid-based structure, we achieve several aspects of disentanglement without complicating the network architecture and without requiring labels. We achieve spatial disentanglement, scale-space disentanglement, and disentanglement of the foreground object from the background style allowing fine-grained control over the generated images. Examples include changing facial expressions in face images, changing beak length in bird images, and changing car dimensions in car images. This empirically leads to better disentanglement scores than state-of-the-art methods on the FFHQ dataset.
Latent Filter Scaling for Multimodal Unsupervised Image-to-Image Translation
Dec 24, 2018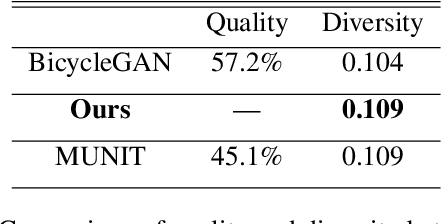
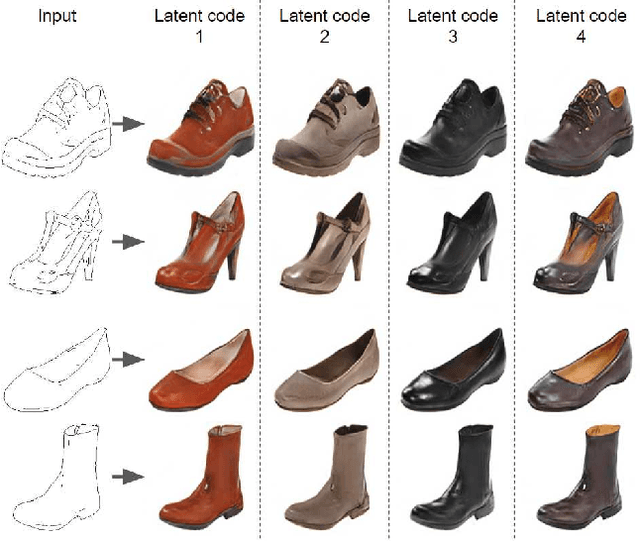


In multimodal unsupervised image-to-image translation tasks, the goal is to translate an image from the source domain to many images in the target domain. We present a simple method that produces higher quality images than current state-of-the-art while maintaining the same amount of multimodal diversity. Previous methods follow the unconditional approach of trying to map the latent code directly to a full-size image. This leads to complicated network architectures with several introduced hyperparameters to tune. By treating the latent code as a modifier of the convolutional filters, we produce multimodal output while maintaining the traditional Generative Adversarial Network (GAN) loss and without additional hyperparameters. The only tuning required by our method controls the tradeoff between variability and quality of generated images. Furthermore, we achieve disentanglement between source domain content and target domain style for free as a by-product of our formulation. We perform qualitative and quantitative experiments showing the advantages of our method compared with the state-of-the art on multiple benchmark image-to-image translation datasets.