 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Layout Representation Learning Across Inconsistently Annotated Datasets via Agentic Harmonization
Apr 13, 2026Fine-tuning object detection (OD) models on combined datasets assumes annotation compatibility, yet datasets often encode conflicting spatial definitions for semantically equivalent categories. We propose an agentic label harmonization workflow that uses a vision-language model to reconcile both category semantics and bounding box granularity across heterogeneous sources before training. We evaluate on document layout detection as a challenging case study, where annotation standards vary widely across corpora. Without harmonization, naïve mixed-dataset fine-tuning degrades a pretrained RT-DETRv2 detector: on SCORE-Bench, which measures how accurately the full document conversion pipeline reproduces ground-truth structure, table TEDS drops from 0.800 to 0.750. Applied to two corpora whose 16 and 10 category taxonomies share only 8 direct correspondences, harmonization yields consistent gains across content fidelity, table structure, and spatial consistency: detection F-score improves from 0.860 to 0.883, table TEDS improves to 0.814, and mean bounding box overlap drops from 0.043 to 0.016. Representation analysis further shows that harmonized training produces more compact and separable post-decoder embeddings, confirming that annotation inconsistency distorts the learned feature space and that resolving it before training restores representation structure.
Financial Report Chunking for Effective Retrieval Augmented Generation
Feb 10, 2024



Chunking information is a key step in Retrieval Augmented Generation (RAG). Current research primarily centers on paragraph-level chunking. This approach treats all texts as equal and neglects the information contained in the structure of documents. We propose an expanded approach to chunk documents by moving beyond mere paragraph-level chunking to chunk primary by structural element components of documents. Dissecting documents into these constituent elements creates a new way to chunk documents that yields the best chunk size without tuning. We introduce a novel framework that evaluates how chunking based on element types annotated by document understanding models contributes to the overall context and accuracy of the information retrieved. We also demonstrate how this approach impacts RAG assisted Question & Answer task performance. Our research includes a comprehensive analysis of various element types, their role in effective information retrieval, and the impact they have on the quality of RAG outputs. Findings support that element type based chunking largely improve RAG results on financial reporting. Through this research, we are also able to answer how to uncover highly accurate RAG.
BabyBear: Cheap inference triage for expensive language models
May 24, 2022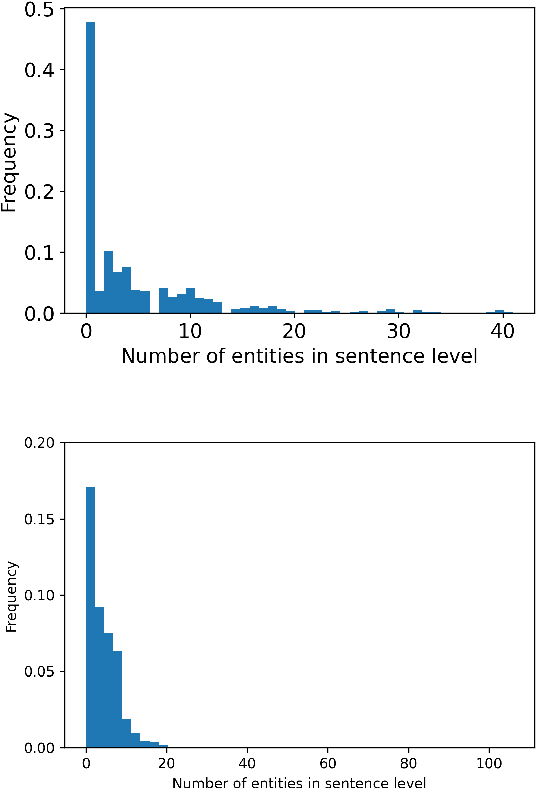
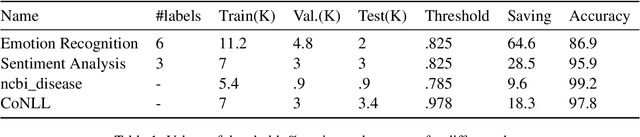
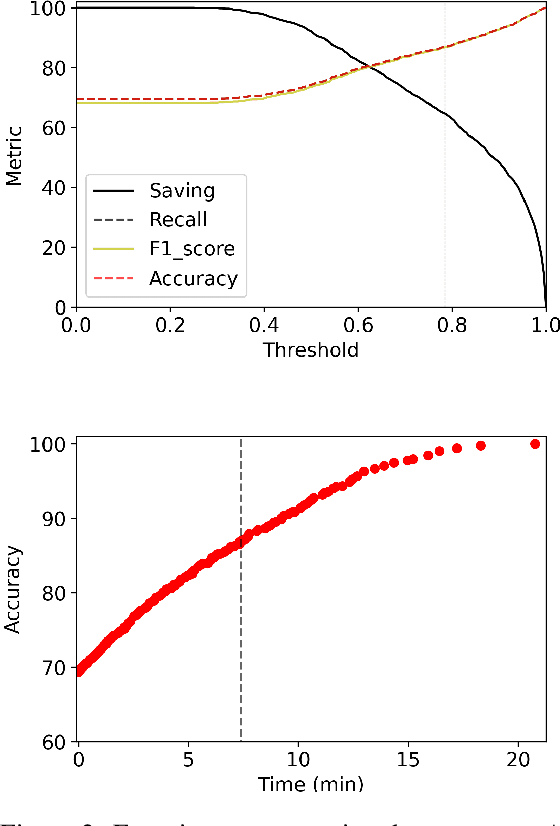
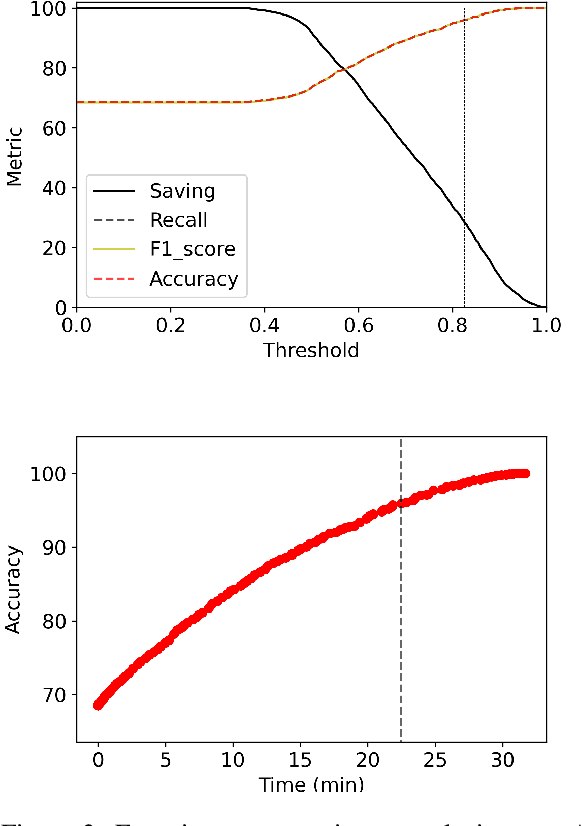
Transformer language models provide superior accuracy over previous models but they are computationally and environmentally expensive. Borrowing the concept of model cascading from computer vision, we introduce BabyBear, a framework for cascading models for natural language processing (NLP) tasks to minimize cost. The core strategy is inference triage, exiting early when the least expensive model in the cascade achieves a sufficiently high-confidence prediction. We test BabyBear on several open source data sets related to document classification and entity recognition. We find that for common NLP tasks a high proportion of the inference load can be accomplished with cheap, fast models that have learned by observing a deep learning model. This allows us to reduce the compute cost of large-scale classification jobs by more than 50% while retaining overall accuracy. For named entity recognition, we save 33% of the deep learning compute while maintaining an F1 score higher than 95% on the CoNLL benchmark.