 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Detection and Location of English Puns
Aug 31, 2019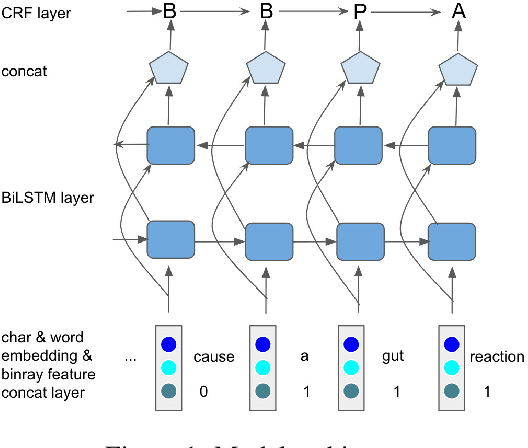
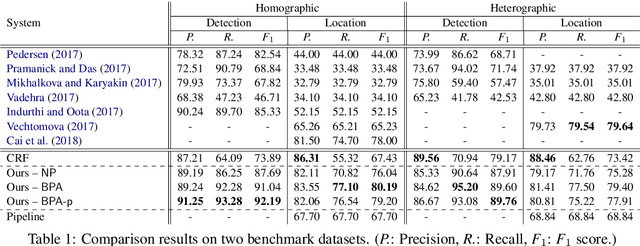
A pun is a form of wordplay for an intended humorous or rhetorical effect, where a word suggests two or more meanings by exploiting polysemy (homographic pun) or phonological similarity to another word (heterographic pun). This paper presents an approach that addresses pun detection and pun location jointly from a sequence labeling perspective. We employ a new tagging scheme such that the model is capable of performing such a joint task, where useful structural information can be properly captured. We show that our proposed model is effective in handling both homographic and heterographic puns. Empirical results on the benchmark datasets demonstrate that our approach can achieve new state-of-the-art results.
Learning Cross-lingual Distributed Logical Representations for Semantic Parsing
Jun 14, 2018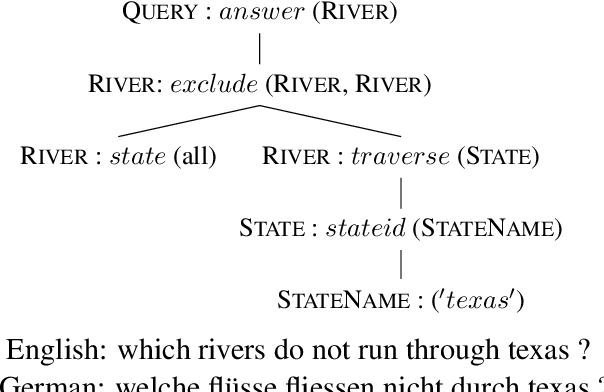
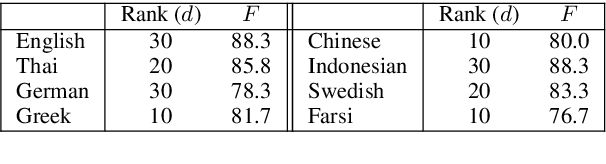
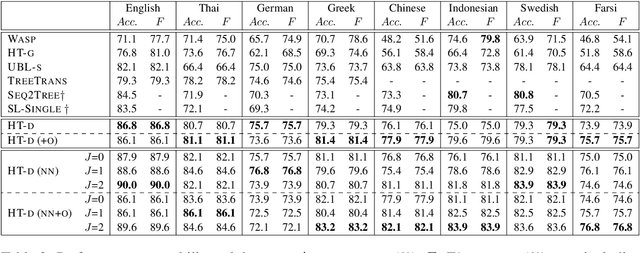
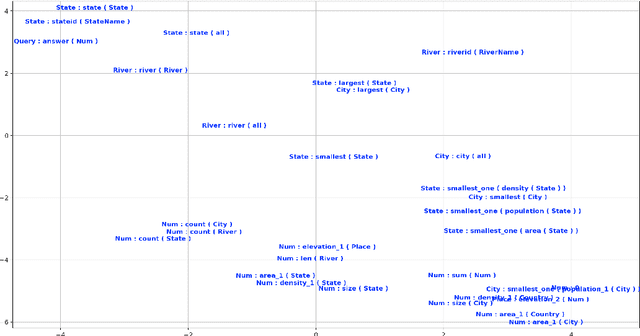
With the development of several multilingual datasets used for semantic parsing, recent research efforts have looked into the problem of learning semantic parsers in a multilingual setup. However, how to improve the performance of a monolingual semantic parser for a specific language by leveraging data annotated in different languages remains a research question that is under-explored. In this work, we present a study to show how learning distributed representations of the logical forms from data annotated in different languages can be used for improving the performance of a monolingual semantic parser. We extend two existing monolingual semantic parsers to incorporate such cross-lingual distributed logical representations as features. Experiments show that our proposed approach is able to yield improved semantic parsing results on the standard multilingual GeoQuery dataset.