 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFitting New Speakers Based on a Short Untranscribed Sample
Feb 20, 2018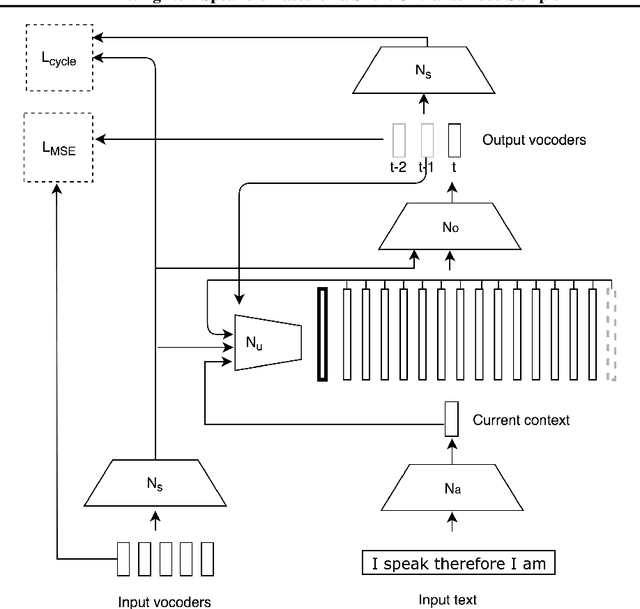


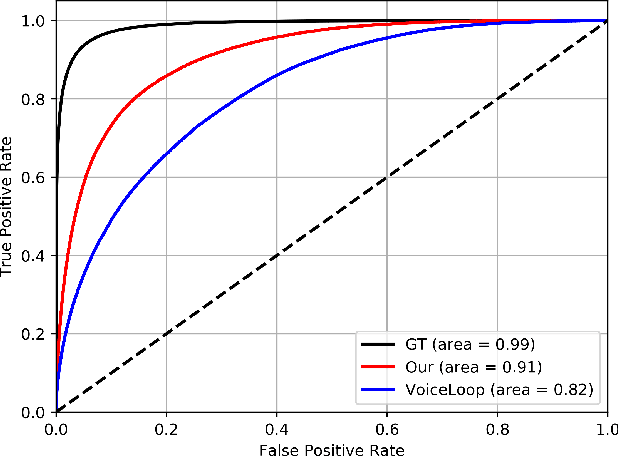
Learning-based Text To Speech systems have the potential to generalize from one speaker to the next and thus require a relatively short sample of any new voice. However, this promise is currently largely unrealized. We present a method that is designed to capture a new speaker from a short untranscribed audio sample. This is done by employing an additional network that given an audio sample, places the speaker in the embedding space. This network is trained as part of the speech synthesis system using various consistency losses. Our results demonstrate a greatly improved performance on both the dataset speakers, and, more importantly, when fitting new voices, even from very short samples.
VoiceLoop: Voice Fitting and Synthesis via a Phonological Loop
Feb 01, 2018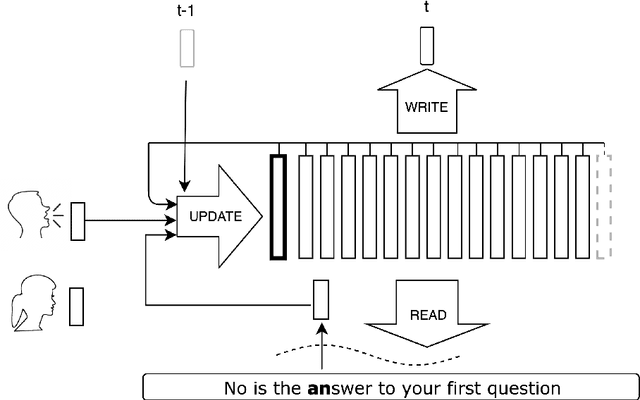
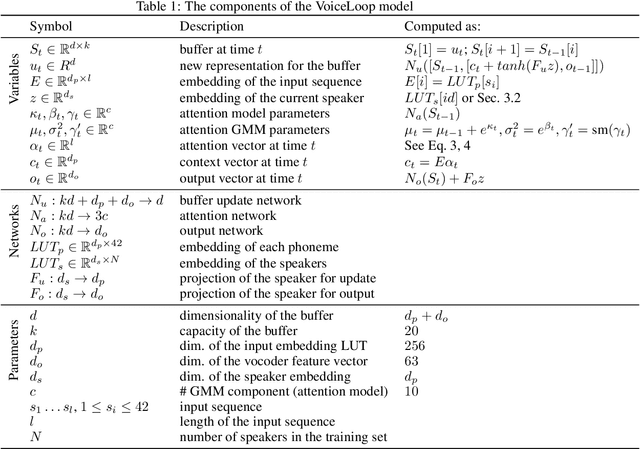
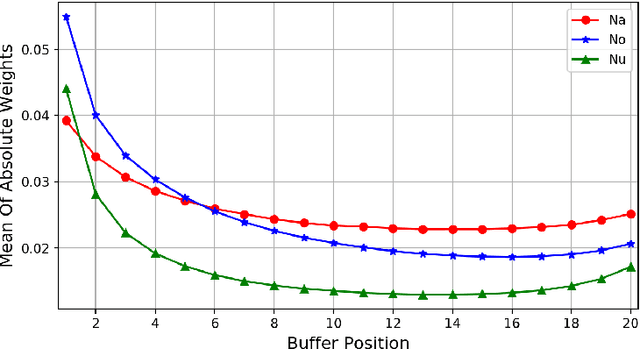
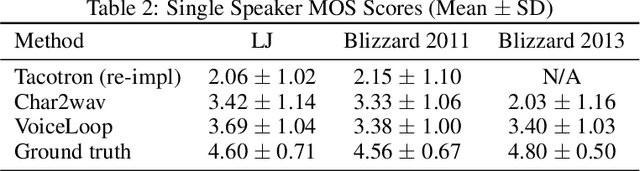
We present a new neural text to speech (TTS) method that is able to transform text to speech in voices that are sampled in the wild. Unlike other systems, our solution is able to deal with unconstrained voice samples and without requiring aligned phonemes or linguistic features. The network architecture is simpler than those in the existing literature and is based on a novel shifting buffer working memory. The same buffer is used for estimating the attention, computing the output audio, and for updating the buffer itself. The input sentence is encoded using a context-free lookup table that contains one entry per character or phoneme. The speakers are similarly represented by a short vector that can also be fitted to new identities, even with only a few samples. Variability in the generated speech is achieved by priming the buffer prior to generating the audio. Experimental results on several datasets demonstrate convincing capabilities, making TTS accessible to a wider range of applications. In order to promote reproducibility, we release our source code and models.
Unsupervised Creation of Parameterized Avatars
Jul 09, 2017
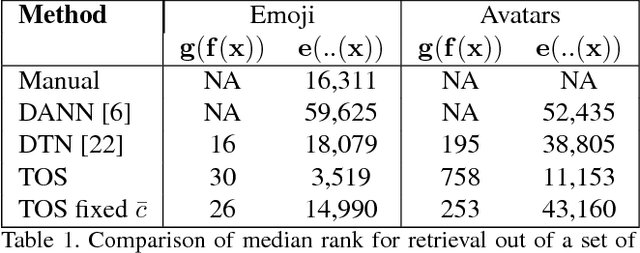


We study the problem of mapping an input image to a tied pair consisting of a vector of parameters and an image that is created using a graphical engine from the vector of parameters. The mapping's objective is to have the output image as similar as possible to the input image. During training, no supervision is given in the form of matching inputs and outputs. This learning problem extends two literature problems: unsupervised domain adaptation and cross domain transfer. We define a generalization bound that is based on discrepancy, and employ a GAN to implement a network solution that corresponds to this bound. Experimentally, our method is shown to solve the problem of automatically creating avatars.
Unsupervised Cross-Domain Image Generation
Nov 07, 2016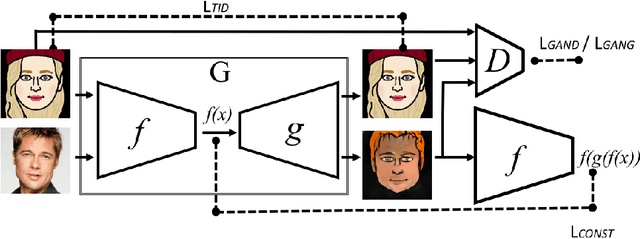
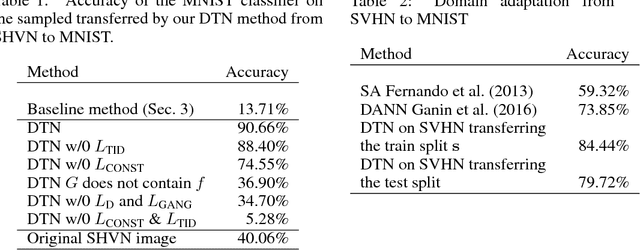


We study the problem of transferring a sample in one domain to an analog sample in another domain. Given two related domains, S and T, we would like to learn a generative function G that maps an input sample from S to the domain T, such that the output of a given function f, which accepts inputs in either domains, would remain unchanged. Other than the function f, the training data is unsupervised and consist of a set of samples from each domain. The Domain Transfer Network (DTN) we present employs a compound loss function that includes a multiclass GAN loss, an f-constancy component, and a regularizing component that encourages G to map samples from T to themselves. We apply our method to visual domains including digits and face images and demonstrate its ability to generate convincing novel images of previously unseen entities, while preserving their identity.
Web-Scale Training for Face Identification
Apr 18, 2015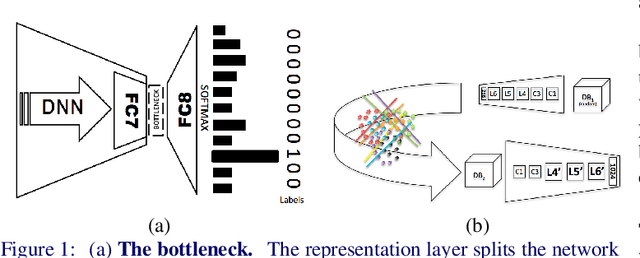
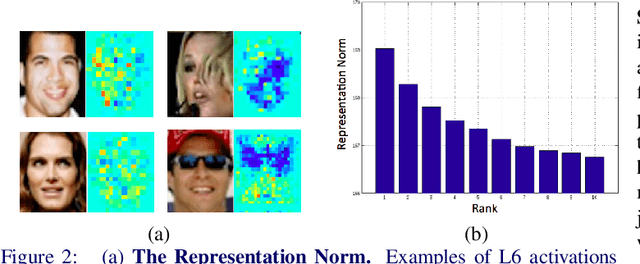
Scaling machine learning methods to very large datasets has attracted considerable attention in recent years, thanks to easy access to ubiquitous sensing and data from the web. We study face recognition and show that three distinct properties have surprising effects on the transferability of deep convolutional networks (CNN): (1) The bottleneck of the network serves as an important transfer learning regularizer, and (2) in contrast to the common wisdom, performance saturation may exist in CNN's (as the number of training samples grows); we propose a solution for alleviating this by replacing the naive random subsampling of the training set with a bootstrapping process. Moreover, (3) we find a link between the representation norm and the ability to discriminate in a target domain, which sheds lights on how such networks represent faces. Based on these discoveries, we are able to improve face recognition accuracy on the widely used LFW benchmark, both in the verification (1:1) and identification (1:N) protocols, and directly compare, for the first time, with the state of the art Commercially-Off-The-Shelf system and show a sizable leap in performance.
Beyond Frontal Faces: Improving Person Recognition Using Multiple Cues
Jan 30, 2015
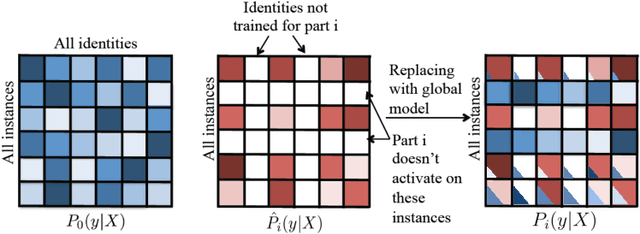
We explore the task of recognizing peoples' identities in photo albums in an unconstrained setting. To facilitate this, we introduce the new People In Photo Albums (PIPA) dataset, consisting of over 60000 instances of 2000 individuals collected from public Flickr photo albums. With only about half of the person images containing a frontal face, the recognition task is very challenging due to the large variations in pose, clothing, camera viewpoint, image resolution and illumination. We propose the Pose Invariant PErson Recognition (PIPER) method, which accumulates the cues of poselet-level person recognizers trained by deep convolutional networks to discount for the pose variations, combined with a face recognizer and a global recognizer. Experiments on three different settings confirm that in our unconstrained setup PIPER significantly improves on the performance of DeepFace, which is one of the best face recognizers as measured on the LFW dataset.
Multi-GPU Training of ConvNets
Feb 18, 2014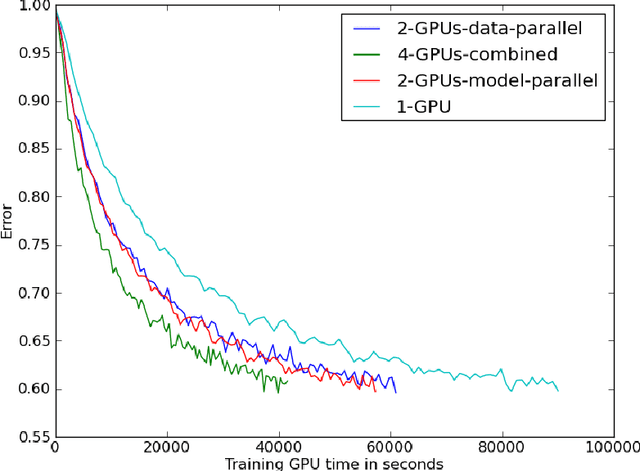
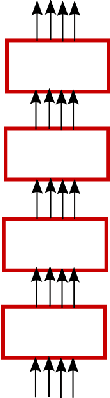
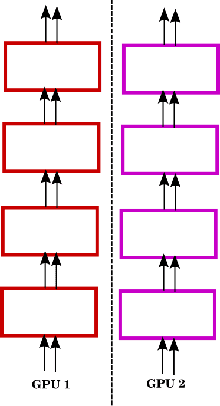
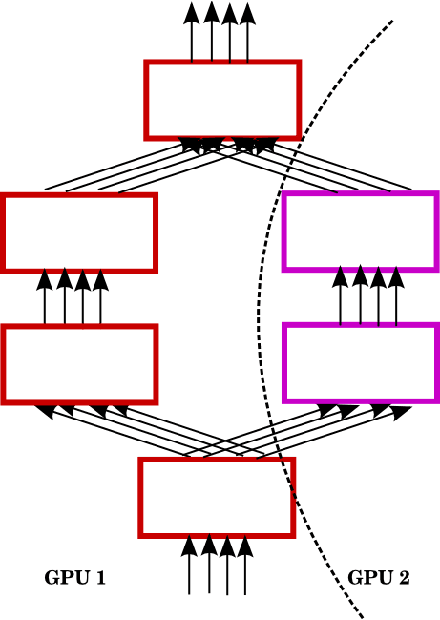
In this work we evaluate different approaches to parallelize computation of convolutional neural networks across several GPUs.
Leveraging Billions of Faces to Overcome Performance Barriers in Unconstrained Face Recognition
Aug 04, 2011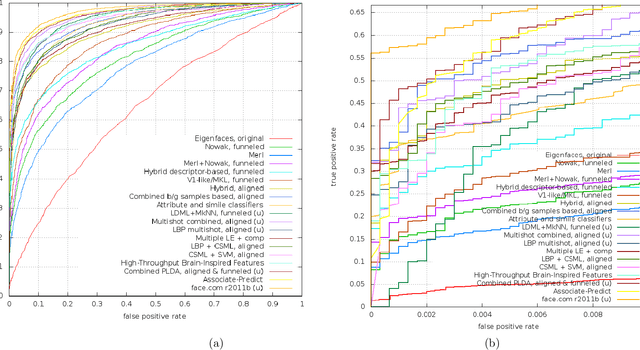

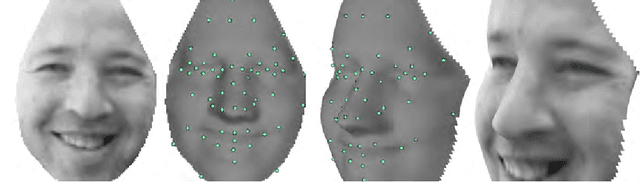

We employ the face recognition technology developed in house at face.com to a well accepted benchmark and show that without any tuning we are able to considerably surpass state of the art results. Much of the improvement is concentrated in the high-valued performance point of zero false positive matches, where the obtained recall rate almost doubles the best reported result to date. We discuss the various components and innovations of our system that enable this significant performance gap. These components include extensive utilization of an accurate 3D reconstructed shape model dealing with challenges arising from pose and illumination. In addition, discriminative models based on billions of faces are used in order to overcome aging and facial expression as well as low light and overexposure. Finally, we identify a challenging set of identification queries that might provide useful focus for future research.