 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Learning System for Domain-specific speech Recognition
Mar 18, 2023As human-machine voice interfaces provide easy access to increasingly intelligent machines, many state-of-the-art automatic speech recognition (ASR) systems are proposed. However, commercial ASR systems usually have poor performance on domain-specific speech especially under low-resource settings. The author works with pre-trained DeepSpeech2 and Wav2Vec2 acoustic models to develop benefit-specific ASR systems. The domain-specific data are collected using proposed semi-supervised learning annotation with little human intervention. The best performance comes from a fine-tuned Wav2Vec2-Large-LV60 acoustic model with an external KenLM, which surpasses the Google and AWS ASR systems on benefit-specific speech. The viability of using error prone ASR transcriptions as part of spoken language understanding (SLU) is also investigated. Results of a benefit-specific natural language understanding (NLU) task show that the domain-specific fine-tuned ASR system can outperform the commercial ASR systems even when its transcriptions have higher word error rate (WER), and the results between fine-tuned ASR and human transcriptions are similar.
A Deep Learning System for Sentiment Analysis of Service Calls
Apr 21, 2020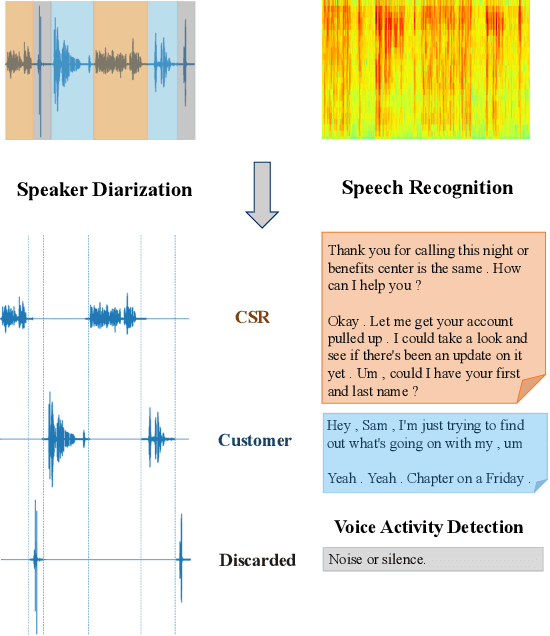
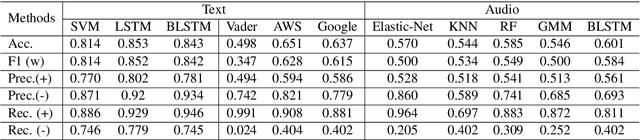
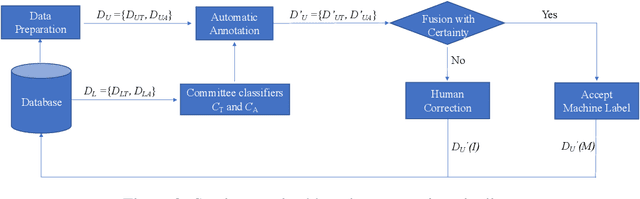
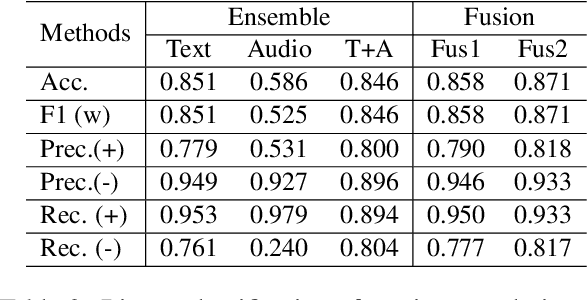
Sentiment analysis is crucial for the advancement of artificial intelligence (AI). Sentiment understanding can help AI to replicate human language and discourse. Studying the formation and response of sentiment state from well-trained Customer Service Representatives (CSRs) can help make the interaction between humans and AI more intelligent. In this paper, a sentiment analysis pipeline is first carried out with respect to real-world multi-party conversations - that is, service calls. Based on the acoustic and linguistic features extracted from the source information, a novel aggregated method for voice sentiment recognition framework is built. Each party's sentiment pattern during the communication is investigated along with the interaction sentiment pattern between all parties.