 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLAB Reporter: Automated journalism covering the Blue Amazon
Oct 08, 2022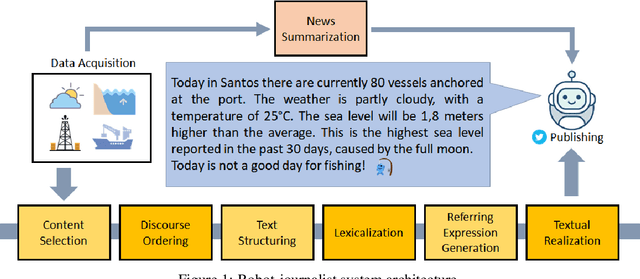
This demo paper introduces the BLAB Reporter, a robot-journalist covering the Brazilian Blue Amazon. The Reporter is based on a pipeline architecture for Natural Language Generation; it offers daily reports, news summaries and curious facts in Brazilian Portuguese. By collecting, storing and analysing structured data from publicly available sources, the robot-journalist uses domain knowledge to generate and publish texts in Twitter. Code and corpus are publicly available
Comparing Computational Architectures for Automated Journalism
Oct 08, 2022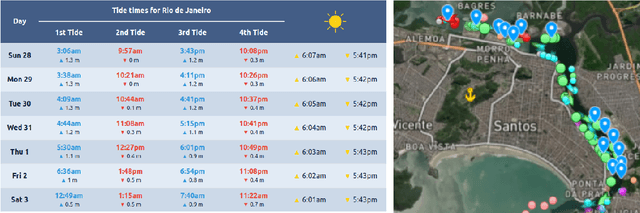
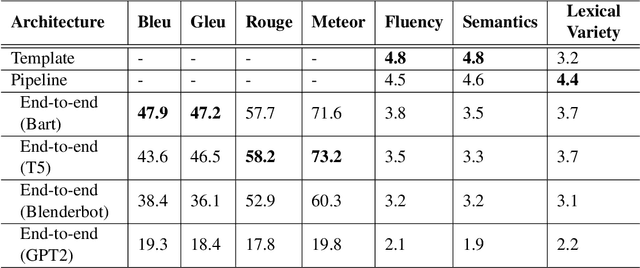
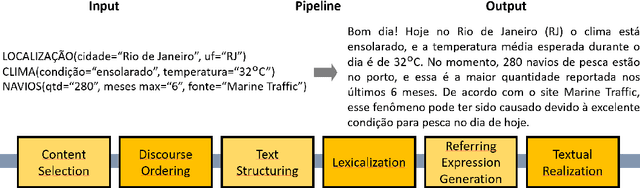
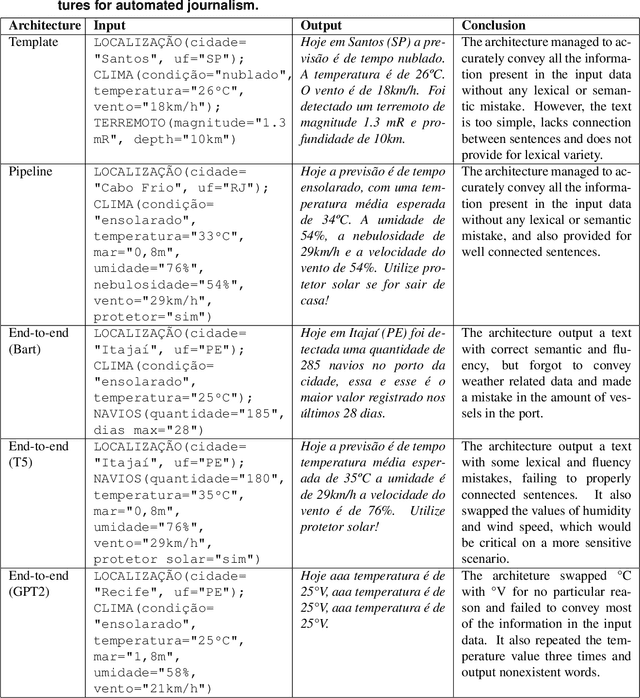
The majority of NLG systems have been designed following either a template-based or a pipeline-based architecture. Recent neural models for data-to-text generation have been proposed with an end-to-end deep learning flavor, which handles non-linguistic input in natural language without explicit intermediary representations. This study compares the most often employed methods for generating Brazilian Portuguese texts from structured data. Results suggest that explicit intermediate steps in the generation process produce better texts than the ones generated by neural end-to-end architectures, avoiding data hallucination while better generalizing to unseen inputs. Code and corpus are publicly available.
The BLue Amazon Brain : A Modular Architecture of Services about the Brazilian Maritime Territory
Sep 06, 2022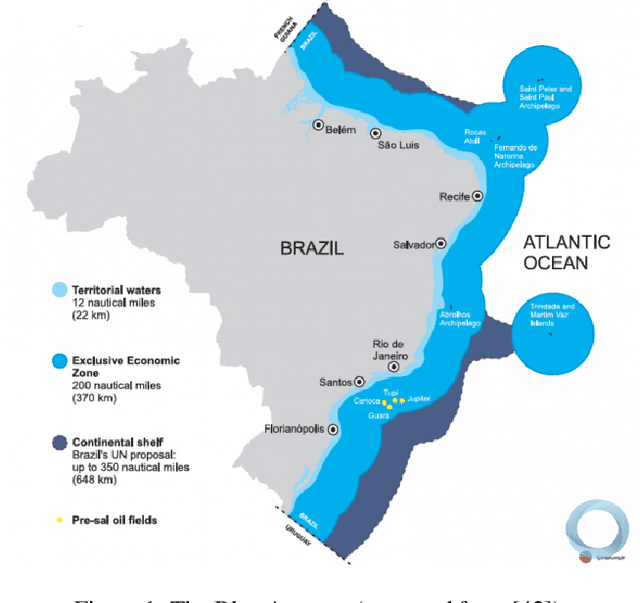
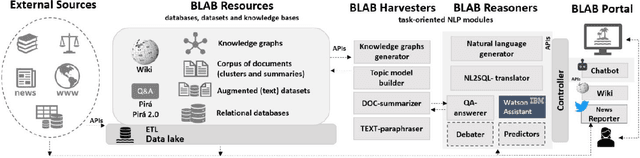
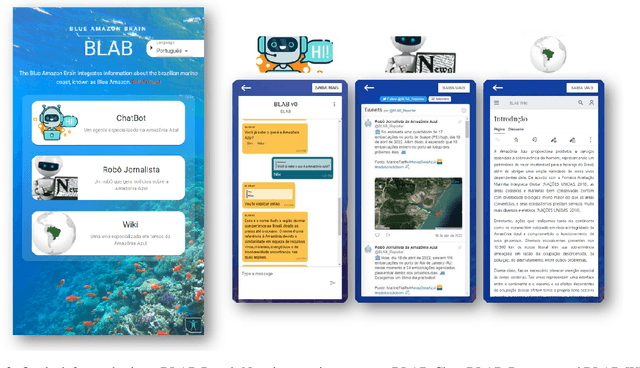
We describe the first steps in the development of an artificial agent focused on the Brazilian maritime territory, a large region within the South Atlantic also known as the Blue Amazon. The "BLue Amazon Brain" (BLAB) integrates a number of services aimed at disseminating information about this region and its importance, functioning as a tool for environmental awareness. The main service provided by BLAB is a conversational facility that deals with complex questions about the Blue Amazon, called BLAB-Chat; its central component is a controller that manages several task-oriented natural language processing modules (e.g., question answering and summarizer systems). These modules have access to an internal data lake as well as to third-party databases. A news reporter (BLAB-Reporter) and a purposely-developed wiki (BLAB-Wiki) are also part of the BLAB service architecture. In this paper, we describe our current version of BLAB's architecture (interface, backend, web services, NLP modules, and resources) and comment on the challenges we have faced so far, such as the lack of training data and the scattered state of domain information. Solving these issues presents a considerable challenge in the development of artificial intelligence for technical domains.