 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Avoid Debate: Scalable AI Safety via Doubly-Efficient Interactive Proofs
Jul 03, 2026As AI models continue to develop powerful capabilities, it becomes critical that we are able to verify that their output is aligned with our intentions. A recent line of work focuses on verification via debate, a model of interactive proofs where two competing powerful provers, or AI models, debate each other to convince a weak verifier, or a human, of the correctness of their claim. However, debate assumes that the two AI models possess equal abilities and that one of them is truthful, which may not be realistic. In this work, we show \emph{how to avoid debate}: we initiate the study of \emph{single-prover} interactive proofs for AI safety. Prior results in single-prover interactive proofs do not immediately carry over to the AI safety setting: for example, they do not work when the computation has access to an oracle, such as to human judgment or an external database such as the web. We present doubly-efficient single-prover interactive proofs and arguments for oracle-aided computations (also known as relativizing proofs), in the settings where (1) the computation is robust, in the sense that the output does not change if at most a small fraction of the answers to oracle queries are incorrect, or (2) the oracle is a low-degree polynomial. These results suggest that interactive verification is possible even without debate, under structured or noise-tolerant oracle access.
Consensus Sampling for Safer Generative AI
Nov 12, 2025Many approaches to AI safety rely on inspecting model outputs or activations, yet certain risks are inherently undetectable by inspection alone. We propose a complementary, architecture-agnostic approach that enhances safety through the aggregation of multiple generative models, with the aggregated model inheriting its safety from the safest subset of a given size among them. Specifically, we present a consensus sampling algorithm that, given $k$ models and a prompt, achieves risk competitive with the average risk of the safest $s$ of the $k$ models, where $s$ is a chosen parameter, while abstaining when there is insufficient agreement between them. The approach leverages the models' ability to compute output probabilities, and we bound the probability of abstention when sufficiently many models are safe and exhibit adequate agreement. The algorithm is inspired by the provable copyright protection algorithm of Vyas et al. (2023). It requires some overlap among safe models, offers no protection when all models are unsafe, and may accumulate risk over repeated use. Nonetheless, our results provide a new, model-agnostic approach for AI safety by amplifying safety guarantees from an unknown subset of models within a collection to that of a single reliable model.
Beyond Perturbations: Learning Guarantees with Arbitrary Adversarial Test Examples
Jul 10, 2020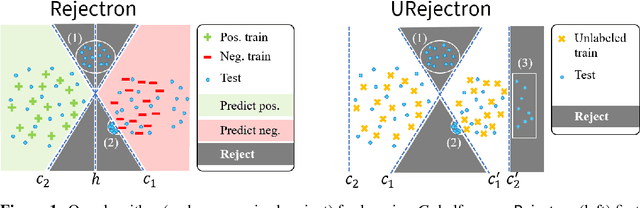
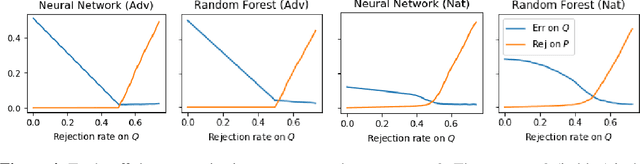
We present a transductive learning algorithm that takes as input training examples from a distribution $P$ and arbitrary (unlabeled) test examples, possibly chosen by an adversary. This is unlike prior work that assumes that test examples are small perturbations of $P$. Our algorithm outputs a selective classifier, which abstains from predicting on some examples. By considering selective transductive learning, we give the first nontrivial guarantees for learning classes of bounded VC dimension with arbitrary train and test distributions---no prior guarantees were known even for simple classes of functions such as intervals on the line. In particular, for any function in a class $C$ of bounded VC dimension, we guarantee a low test error rate and a low rejection rate with respect to $P$. Our algorithm is efficient given an Empirical Risk Minimizer (ERM) for $C$. Our guarantees hold even for test examples chosen by an unbounded white-box adversary. We also give guarantees for generalization, agnostic, and unsupervised settings.