 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-supervised Dictionary Learning
Feb 05, 2018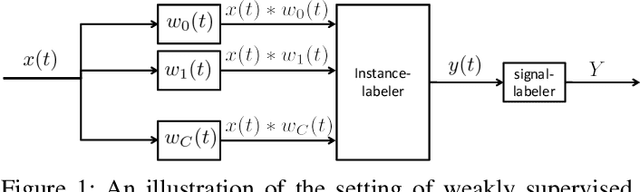

We present a probabilistic modeling and inference framework for discriminative analysis dictionary learning under a weak supervision setting. Dictionary learning approaches have been widely used for tasks such as low-level signal denoising and restoration as well as high-level classification tasks, which can be applied to audio and image analysis. Synthesis dictionary learning aims at jointly learning a dictionary and corresponding sparse coefficients to provide accurate data representation. This approach is useful for denoising and signal restoration, but may lead to sub-optimal classification performance. By contrast, analysis dictionary learning provides a transform that maps data to a sparse discriminative representation suitable for classification. We consider the problem of analysis dictionary learning for time-series data under a weak supervision setting in which signals are assigned with a global label instead of an instantaneous label signal. We propose a discriminative probabilistic model that incorporates both label information and sparsity constraints on the underlying latent instantaneous label signal using cardinality control. We present the expectation maximization (EM) procedure for maximum likelihood estimation (MLE) of the proposed model. To facilitate a computationally efficient E-step, we propose both a chain and a novel tree graph reformulation of the graphical model. The performance of the proposed model is demonstrated on both synthetic and real-world data.
Confidence-Constrained Maximum Entropy Framework for Learning from Multi-Instance Data
Mar 07, 2016

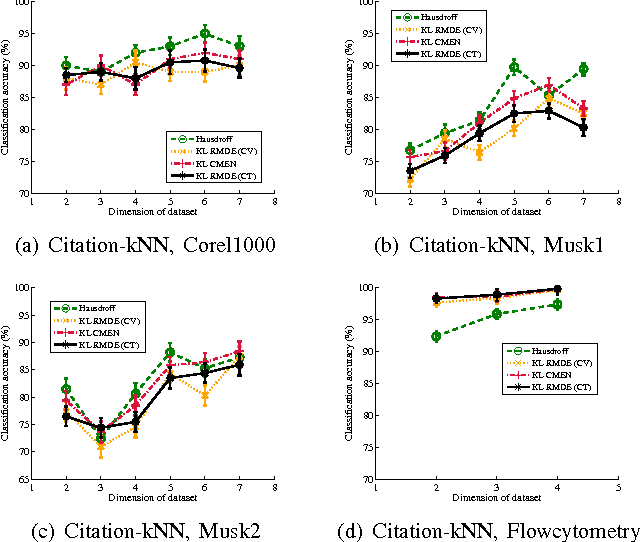

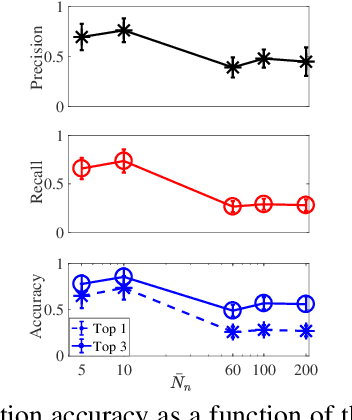
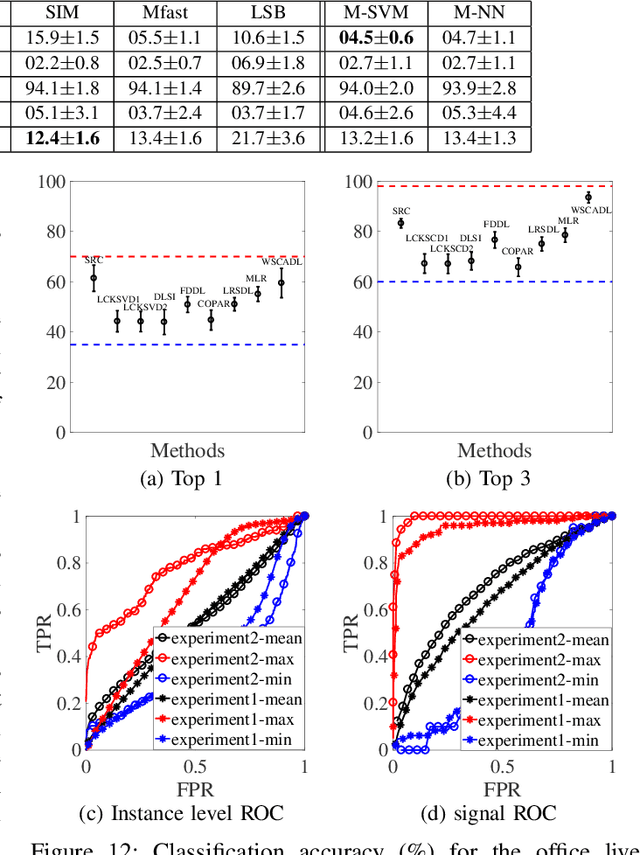
Multi-instance data, in which each object (bag) contains a collection of instances, are widespread in machine learning, computer vision, bioinformatics, signal processing, and social sciences. We present a maximum entropy (ME) framework for learning from multi-instance data. In this approach each bag is represented as a distribution using the principle of ME. We introduce the concept of confidence-constrained ME (CME) to simultaneously learn the structure of distribution space and infer each distribution. The shared structure underlying each density is used to learn from instances inside each bag. The proposed CME is free of tuning parameters. We devise a fast optimization algorithm capable of handling large scale multi-instance data. In the experimental section, we evaluate the performance of the proposed approach in terms of exact rank recovery in the space of distributions and compare it with the regularized ME approach. Moreover, we compare the performance of CME with Multi-Instance Learning (MIL) state-of-the-art algorithms and show a comparable performance in terms of accuracy with reduced computational complexity.
Discriminative Clustering with Relative Constraints
Dec 30, 2014
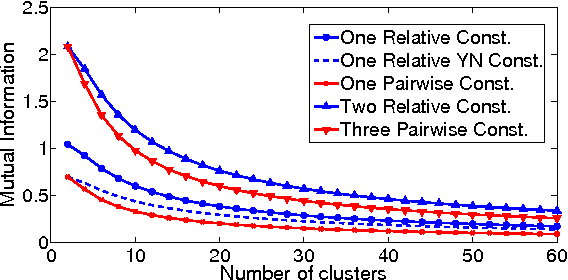
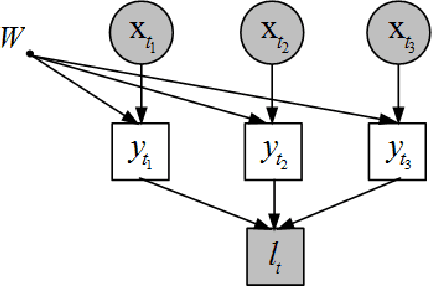
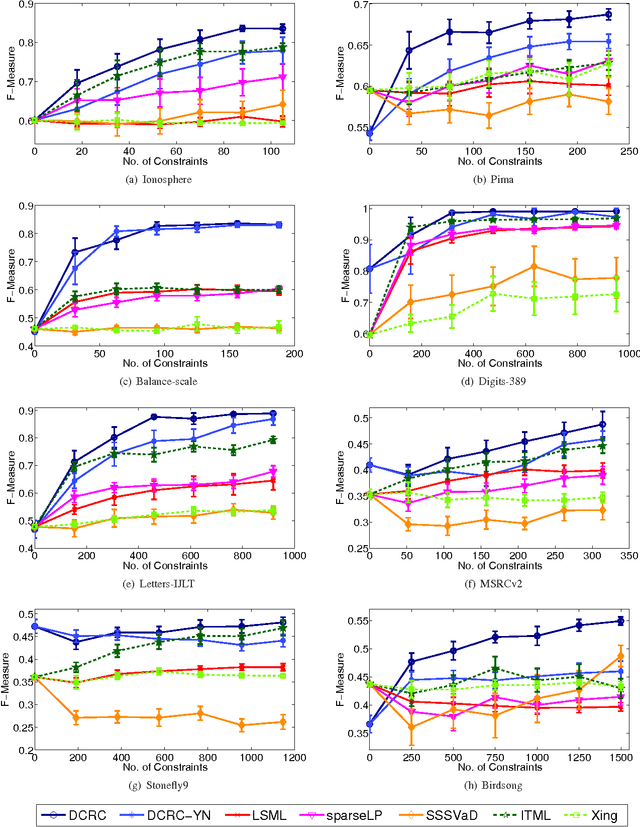
We study the problem of clustering with relative constraints, where each constraint specifies relative similarities among instances. In particular, each constraint $(x_i, x_j, x_k)$ is acquired by posing a query: is instance $x_i$ more similar to $x_j$ than to $x_k$? We consider the scenario where answers to such queries are based on an underlying (but unknown) class concept, which we aim to discover via clustering. Different from most existing methods that only consider constraints derived from yes and no answers, we also incorporate don't know responses. We introduce a Discriminative Clustering method with Relative Constraints (DCRC) which assumes a natural probabilistic relationship between instances, their underlying cluster memberships, and the observed constraints. The objective is to maximize the model likelihood given the constraints, and in the meantime enforce cluster separation and cluster balance by also making use of the unlabeled instances. We evaluated the proposed method using constraints generated from ground-truth class labels, and from (noisy) human judgments from a user study. Experimental results demonstrate: 1) the usefulness of relative constraints, in particular when don't know answers are considered; 2) the improved performance of the proposed method over state-of-the-art methods that utilize either relative or pairwise constraints; and 3) the robustness of our method in the presence of noisy constraints, such as those provided by human judgement.
Dynamic Programming for Instance Annotation in Multi-instance Multi-label Learning
Nov 14, 2014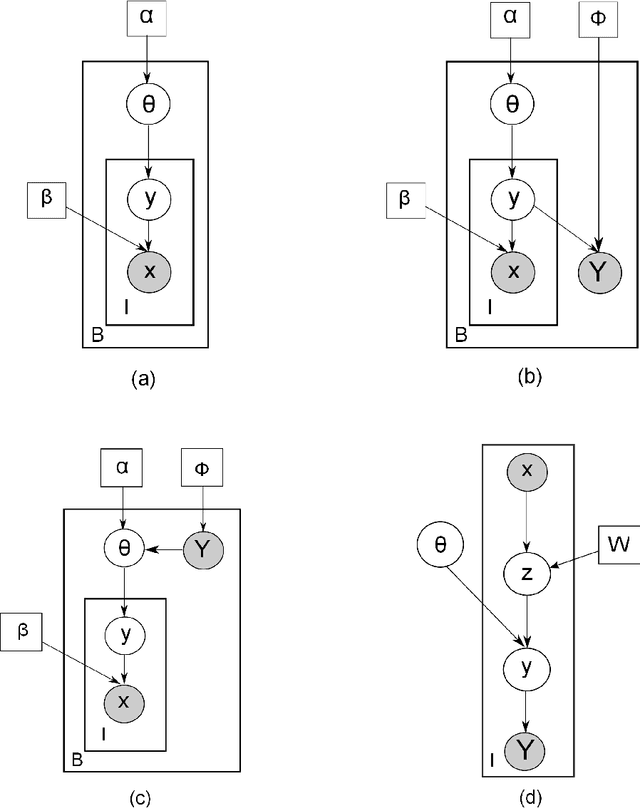

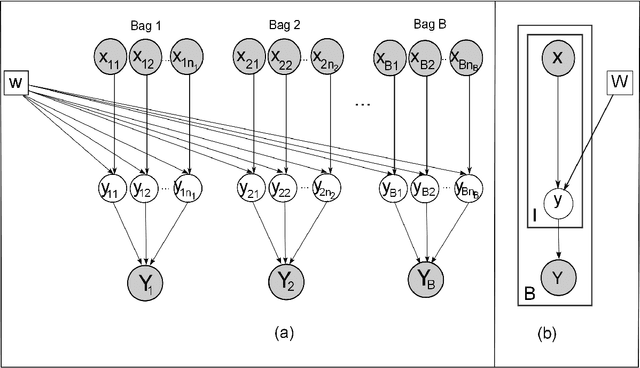
Labeling data for classification requires significant human effort. To reduce labeling cost, instead of labeling every instance, a group of instances (bag) is labeled by a single bag label. Computer algorithms are then used to infer the label for each instance in a bag, a process referred to as instance annotation. This task is challenging due to the ambiguity regarding the instance labels. We propose a discriminative probabilistic model for the instance annotation problem and introduce an expectation maximization framework for inference, based on the maximum likelihood approach. For many probabilistic approaches, brute-force computation of the instance label posterior probability given its bag label is exponential in the number of instances in the bag. Our key contribution is a dynamic programming method for computing the posterior that is linear in the number of instances. We evaluate our methods using both benchmark and real world data sets, in the domain of bird song, image annotation, and activity recognition. In many cases, the proposed framework outperforms, sometimes significantly, the current state-of-the-art MIML learning methods, both in instance label prediction and bag label prediction.
Active Metric Learning from Relative Comparisons
Sep 15, 2014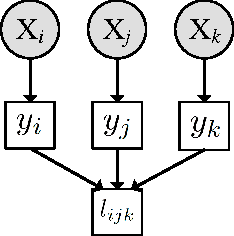
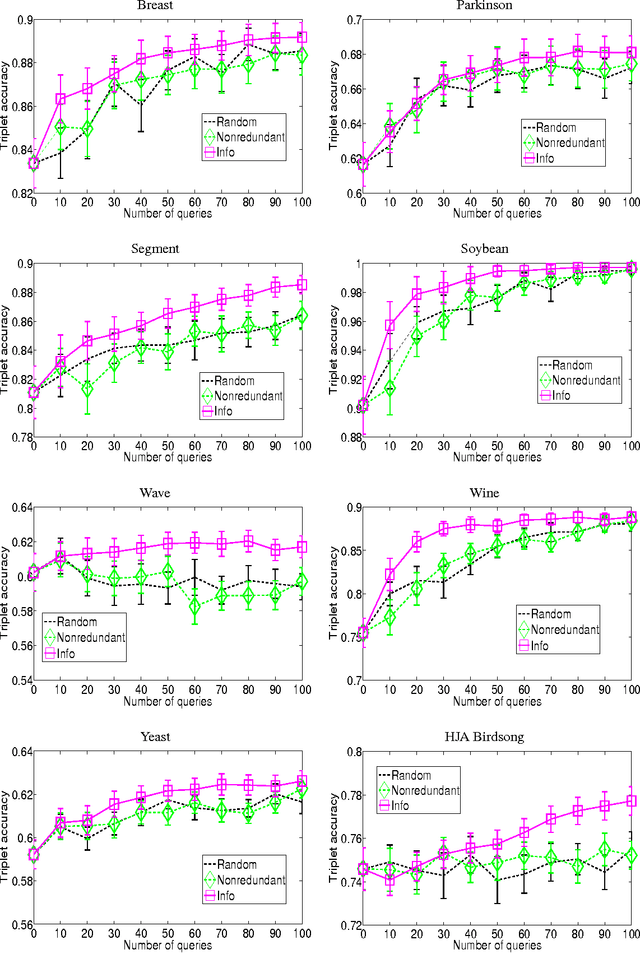
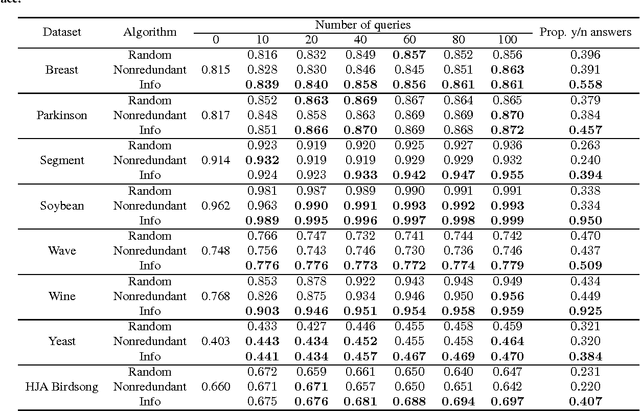
This work focuses on active learning of distance metrics from relative comparison information. A relative comparison specifies, for a data point triplet $(x_i,x_j,x_k)$, that instance $x_i$ is more similar to $x_j$ than to $x_k$. Such constraints, when available, have been shown to be useful toward defining appropriate distance metrics. In real-world applications, acquiring constraints often require considerable human effort. This motivates us to study how to select and query the most useful relative comparisons to achieve effective metric learning with minimum user effort. Given an underlying class concept that is employed by the user to provide such constraints, we present an information-theoretic criterion that selects the triplet whose answer leads to the highest expected gain in information about the classes of a set of examples. Directly applying the proposed criterion requires examining $O(n^3)$ triplets with $n$ instances, which is prohibitive even for datasets of moderate size. We show that a randomized selection strategy can be used to reduce the selection pool from $O(n^3)$ to $O(n)$, allowing us to scale up to larger-size problems. Experiments show that the proposed method consistently outperforms two baseline policies.
Novelty Detection Under Multi-Instance Multi-Label Framework
Nov 25, 2013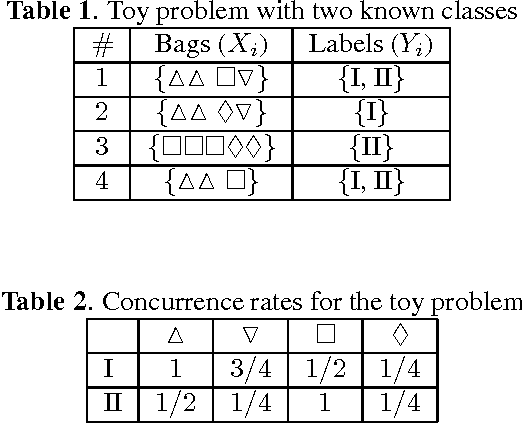
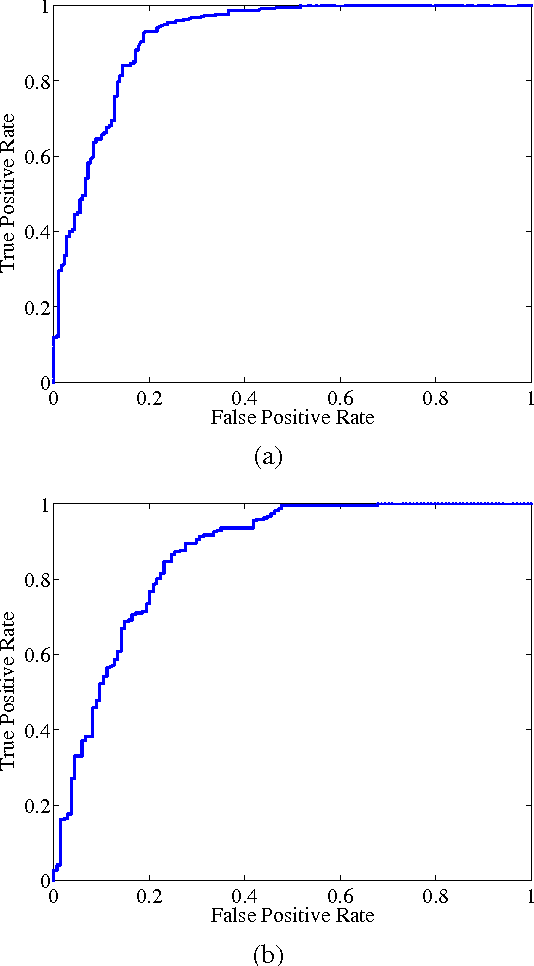

Novelty detection plays an important role in machine learning and signal processing. This paper studies novelty detection in a new setting where the data object is represented as a bag of instances and associated with multiple class labels, referred to as multi-instance multi-label (MIML) learning. Contrary to the common assumption in MIML that each instance in a bag belongs to one of the known classes, in novelty detection, we focus on the scenario where bags may contain novel-class instances. The goal is to determine, for any given instance in a new bag, whether it belongs to a known class or a novel class. Detecting novelty in the MIML setting captures many real-world phenomena and has many potential applications. For example, in a collection of tagged images, the tag may only cover a subset of objects existing in the images. Discovering an object whose class has not been previously tagged can be useful for the purpose of soliciting a label for the new object class. To address this novel problem, we present a discriminative framework for detecting new class instances. Experiments demonstrate the effectiveness of our proposed method, and reveal that the presence of unlabeled novel instances in training bags is helpful to the detection of such instances in testing stage.
Multi-Label Classifier Chains for Bird Sound
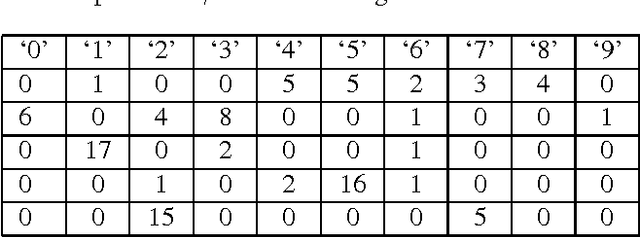
May 29, 2013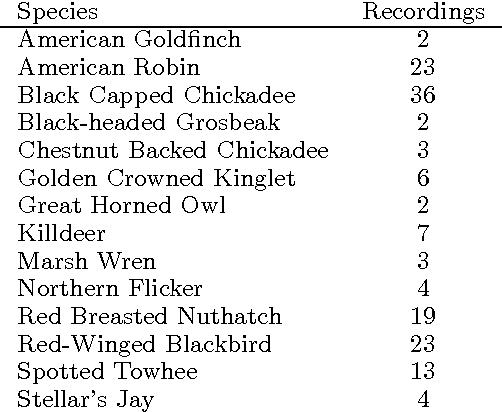


Bird sound data collected with unattended microphones for automatic surveys, or mobile devices for citizen science, typically contain multiple simultaneously vocalizing birds of different species. However, few works have considered the multi-label structure in birdsong. We propose to use an ensemble of classifier chains combined with a histogram-of-segments representation for multi-label classification of birdsong. The proposed method is compared with binary relevance and three multi-instance multi-label learning (MIML) algorithms from prior work (which focus more on structure in the sound, and less on structure in the label sets). Experiments are conducted on two real-world birdsong datasets, and show that the proposed method usually outperforms binary relevance (using the same features and base-classifier), and is better in some cases and worse in others compared to the MIML algorithms.