 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyCrysDiff: Controllable Generation of Three-Dimensional Computable Polycrystalline Material Structures
Mar 12, 2026The three-dimensional (3D) microstructures of polycrystalline materials exert a critical influence on their mechanical and physical properties. Realistic, controllable construction of these microstructures is a key step toward elucidating structure-property relationships, yet remains a formidable challenge. Herein, we propose PolyCrysDiff, a framework based on conditional latent diffusion that enables the end-to-end generation of computable 3D polycrystalline microstructures. Comprehensive qualitative and quantitative evaluations demonstrate that PolyCrysDiff faithfully reproduces target grain morphologies, orientation distributions, and 3D spatial correlations, while achieving an $R^2$ over 0.972 on grain attributes (e.g., size and sphericity) control, thereby outperforming mainstream approaches such as Markov random field (MRF)- and convolutional neural network (CNN)-based methods. The computability and physical validity of the generated microstructures are verified through a series of crystal plasticity finite element method (CPFEM) simulations. Leveraging PolyCrysDiff's controllable generative capability, we systematically elucidate how grain-level microstructural characteristics affect the mechanical properties of polycrystalline materials. This development is expected to pave a key step toward accelerated, data-driven optimization and design of polycrystalline materials.
Small-Footprint Keyword Spotting with Multi-Scale Temporal Convolution
Oct 20, 2020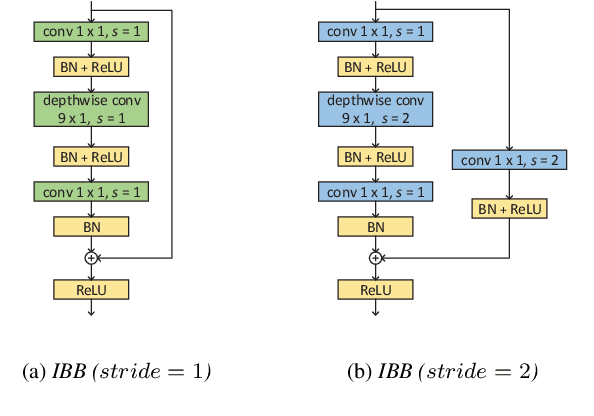
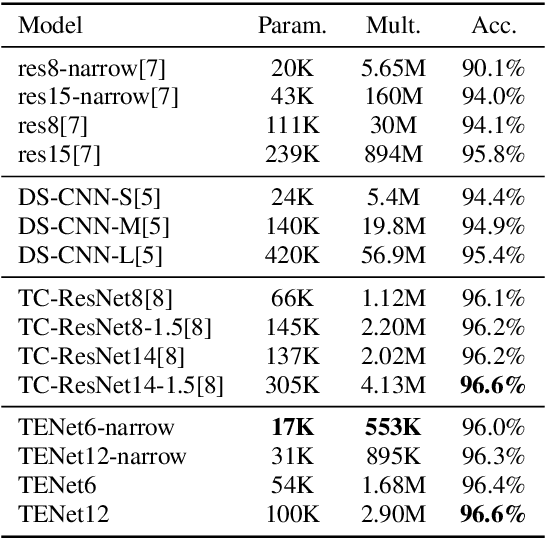
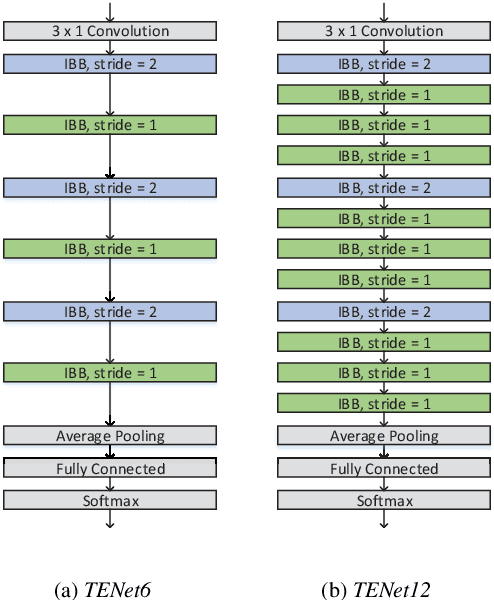
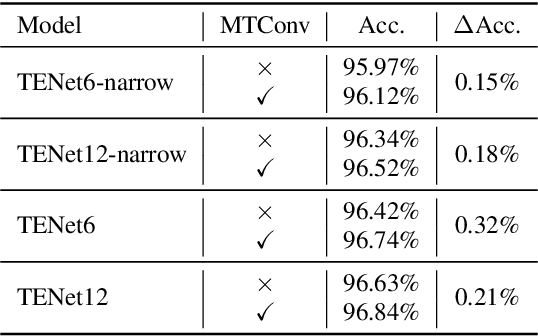
Keyword Spotting (KWS) plays a vital role in human-computer interaction for smart on-device terminals and service robots. It remains challenging to achieve the trade-off between small footprint and high accuracy for KWS task. In this paper, we explore the application of multi-scale temporal modeling to the small-footprint keyword spotting task. We propose a multi-branch temporal convolution module (MTConv), a CNN block consisting of multiple temporal convolution filters with different kernel sizes, which enriches temporal feature space. Besides, taking advantage of temporal and depthwise convolution, a temporal efficient neural network (TENet) is designed for KWS system. Based on the purposed model, we replace standard temporal convolution layers with MTConvs that can be trained for better performance. While at the inference stage, the MTConv can be equivalently converted to the base convolution architecture, so that no extra parameters and computational costs are added compared to the base model. The results on Google Speech Command Dataset show that one of our models trained with MTConv performs the accuracy of 96.8% with only 100K parameters.