Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAFS: A Deep Feature Selection Approach for Precision Medicine
Apr 20, 2017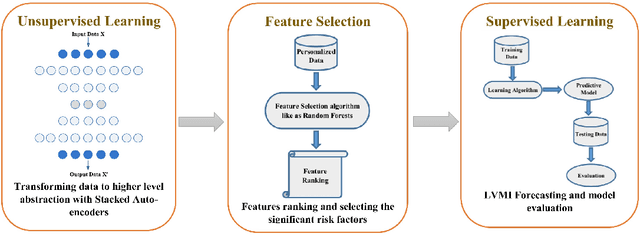
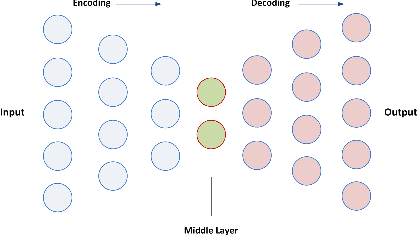
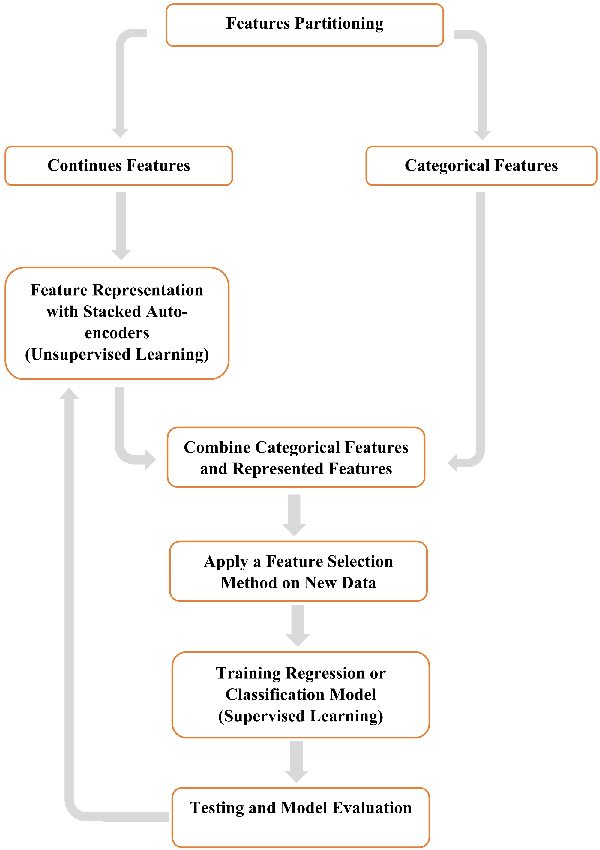
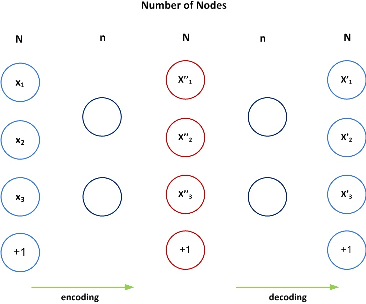
In this paper, we propose a new deep feature selection method based on deep architecture. Our method uses stacked auto-encoders for feature representation in higher-level abstraction. We developed and applied a novel feature learning approach to a specific precision medicine problem, which focuses on assessing and prioritizing risk factors for hypertension (HTN) in a vulnerable demographic subgroup (African-American). Our approach is to use deep learning to identify significant risk factors affecting left ventricular mass indexed to body surface area (LVMI) as an indicator of heart damage risk. The results show that our feature learning and representation approach leads to better results in comparison with others.
Via