 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Framework for Structure-Aware Clustering and Heterogeneous Causal Graph Learning
May 19, 2026In complex multivariate systems, interactions among variables are defined by dependency structures, often encoded as directed acyclic graphs ($\text{DAGs}$). However, dependency structures can vary across subjects, and ignoring this structural heterogeneity introduces bias and obscures subpopulation-specific dependencies. To address this, we propose Directed Acyclic Graph-based Dependency Clustering via Alternating Direction Method of Multipliers (DAG-DC-ADMM), a unified framework built upon Structural Equation Modeling (SEM) that jointly learns cluster assignments and cluster-specific dependency structures. We encode acyclicity via a smooth constraint and integrate a groupwise truncated Lasso fusion penalty (gTLP) to cluster subjects based on their structural similarity. This yields a nonconvex optimization problem that incorporates sparsity, acyclicity, and structural consensus constraints. We address the nonconvexity by using the augmented Lagrangian method and solve it with an adapted version of the Alternating Direction Method of Multipliers (ADMM) for difference-of-convex programs. For certain graph structures, such as upper triangular adjacency matrices, our algorithm is guaranteed to converge to a Karush-Kuhn-Tucker (KKT) point. Experiments demonstrate that our method recovers cluster-specific causal dependency structures with a high true positive rate and a low false discovery rate. This capability enables the robust discovery of heterogeneous dependencies across subjects where the subpopulation label is unknown.
Learning a high-dimensional classification rule using auxiliary outcomes
Nov 11, 2020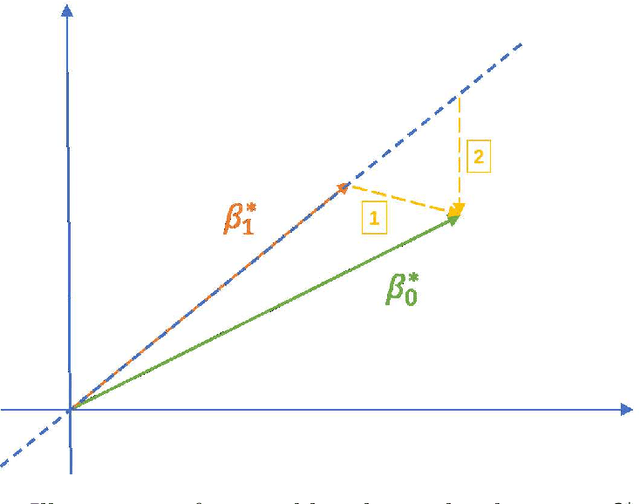
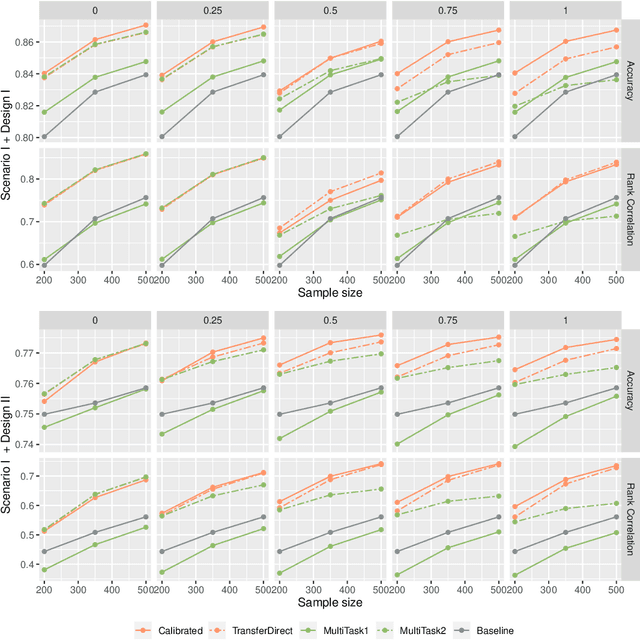
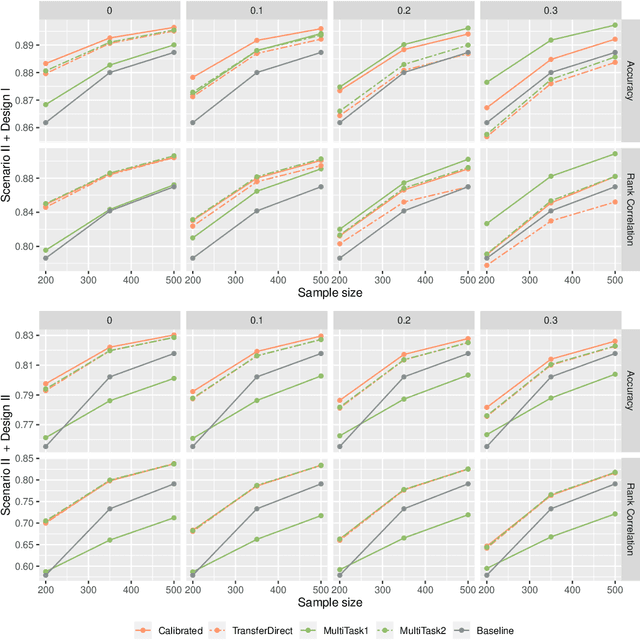
Correlated outcomes are common in many practical problems. Based on a decomposition of estimation bias into two types, within-subspace and against-subspace, we develop a robust approach to estimating the classification rule for the outcome of interest with the presence of auxiliary outcomes in high-dimensional settings. The proposed method includes a pooled estimation step using all outcomes to gain efficiency, and a subsequent calibration step using only the outcome of interest to correct both types of biases. We show that when the pooled estimator has a low estimation error and a sparse against-subspace bias, the calibrated estimator can achieve a lower estimation error than that when using only the single outcome of interest. An inference procedure for the calibrated estimator is also provided. Simulations and a real data analysis are conducted to justify the superiority of the proposed method.