 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePagedEviction: Structured Block-wise KV Cache Pruning for Efficient Large Language Model Inference
Sep 04, 2025



KV caching significantly improves the efficiency of Large Language Model (LLM) inference by storing attention states from previously processed tokens, enabling faster generation of subsequent tokens. However, as sequence length increases, the KV cache quickly becomes a major memory bottleneck. To address this, we propose PagedEviction, a novel fine-grained, structured KV cache pruning strategy that enhances the memory efficiency of vLLM's PagedAttention. Unlike existing approaches that rely on attention-based token importance or evict tokens across different vLLM pages, PagedEviction introduces an efficient block-wise eviction algorithm tailored for paged memory layouts. Our method integrates seamlessly with PagedAttention without requiring any modifications to its CUDA attention kernels. We evaluate PagedEviction across Llama-3.1-8B-Instruct, Llama-3.2-1B-Instruct, and Llama-3.2-3B-Instruct models on the LongBench benchmark suite, demonstrating improved memory usage with better accuracy than baselines on long context tasks.
CADS: Core-Aware Dynamic Scheduler for Multicore Memory Controllers
Jul 17, 2019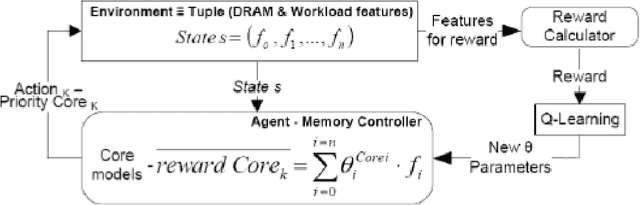
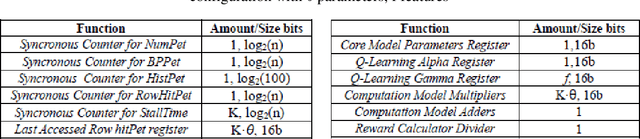

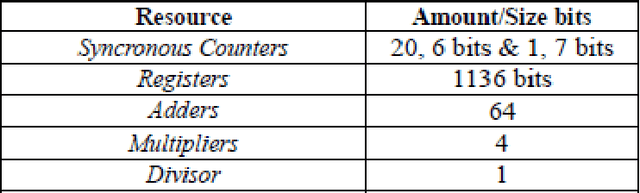
Memory controller scheduling is crucial in multicore processors, where DRAM bandwidth is shared. Since increased number of requests from multiple cores of processors becomes a source of bottleneck, scheduling the requests efficiently is necessary to utilize all the computing power these processors offer. However, current multicore processors are using traditional memory controllers, which are designed for single-core processors. They are unable to adapt to changing characteristics of memory workloads that run simultaneously on multiple cores. Existing schedulers may disrupt locality and bank parallelism among data requests coming from different cores. Hence, novel memory controllers that consider and adapt to the memory access characteristics, and share memory resources efficiently and fairly are necessary. We introduce Core-Aware Dynamic Scheduler (CADS) for multicore memory controller. CADS uses Reinforcement Learning (RL) to alter its scheduling strategy dynamically at runtime. Our scheduler utilizes locality among data requests from multiple cores and exploits parallelism in accessing multiple banks of DRAM. CADS is also able to share the DRAM while guaranteeing fairness to all cores accessing memory. Using CADS policy, we achieve 20% better cycles per instruction (CPI) in running memory intensive and compute intensive PARSEC parallel benchmarks simultaneously, and 16% better CPI with SPEC 2006 benchmarks.