 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjective Mispricing Detection for Shortlisting Undervalued Football Players via Market Dynamics and News Signals
Mar 18, 2026We present a practical, reproducible framework for identifying undervalued football players grounded in objective mispricing. Instead of relying on subjective expert labels, we estimate an expected market value from structured data (historical market dynamics, biographical and contract features, transfer history) and compare it to the observed valuation to define mispricing. We then assess whether news-derived Natural Language Processing (NLP) features (i.e., sentiment statistics and semantic embeddings from football articles) complement market signals for shortlisting undervalued players. Using a chronological (leakage-aware) evaluation, gradient-boosted regression explains a large share of the variance in log-transformed market value. For undervaluation shortlisting, ROC-AUC-based ablations show that market dynamics are the primary signal, while NLP features provide consistent, secondary gains that improve robustness and interpretability. SHAP analyses suggest the dominance of market trends and age, with news-derived volatility cues amplifying signals in high-uncertainty regimes. The proposed pipeline is designed for decision support in scouting workflows, emphasizing ranking/shortlisting over hard classification thresholds, and includes a concise reproducibility and ethics statement.
SemCovNet: Towards Fair and Semantic Coverage-Aware Learning for Underrepresented Visual Concepts
Feb 18, 2026Modern vision models increasingly rely on rich semantic representations that extend beyond class labels to include descriptive concepts and contextual attributes. However, existing datasets exhibit Semantic Coverage Imbalance (SCI), a previously overlooked bias arising from the long-tailed semantic representations. Unlike class imbalance, SCI occurs at the semantic level, affecting how models learn and reason about rare yet meaningful semantics. To mitigate SCI, we propose Semantic Coverage-Aware Network (SemCovNet), a novel model that explicitly learns to correct semantic coverage disparities. SemCovNet integrates a Semantic Descriptor Map (SDM) for learning semantic representations, a Descriptor Attention Modulation (DAM) module that dynamically weights visual and concept features, and a Descriptor-Visual Alignment (DVA) loss that aligns visual features with descriptor semantics. We quantify semantic fairness using a Coverage Disparity Index (CDI), which measures the alignment between coverage and error. Extensive experiments across multiple datasets demonstrate that SemCovNet enhances model reliability and substantially reduces CDI, achieving fairer and more equitable performance. This work establishes SCI as a measurable and correctable bias, providing a foundation for advancing semantic fairness and interpretable vision learning.
Bias in, Bias out: Annotation Bias in Multilingual Large Language Models
Nov 18, 2025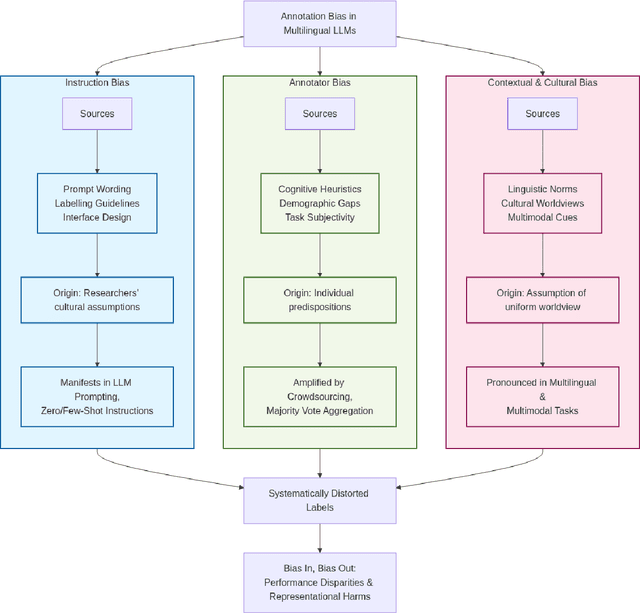

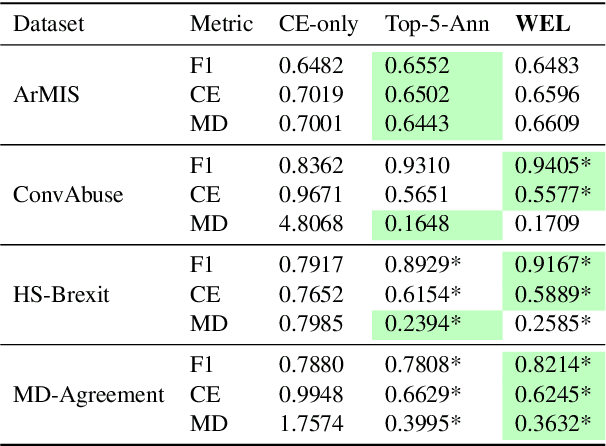
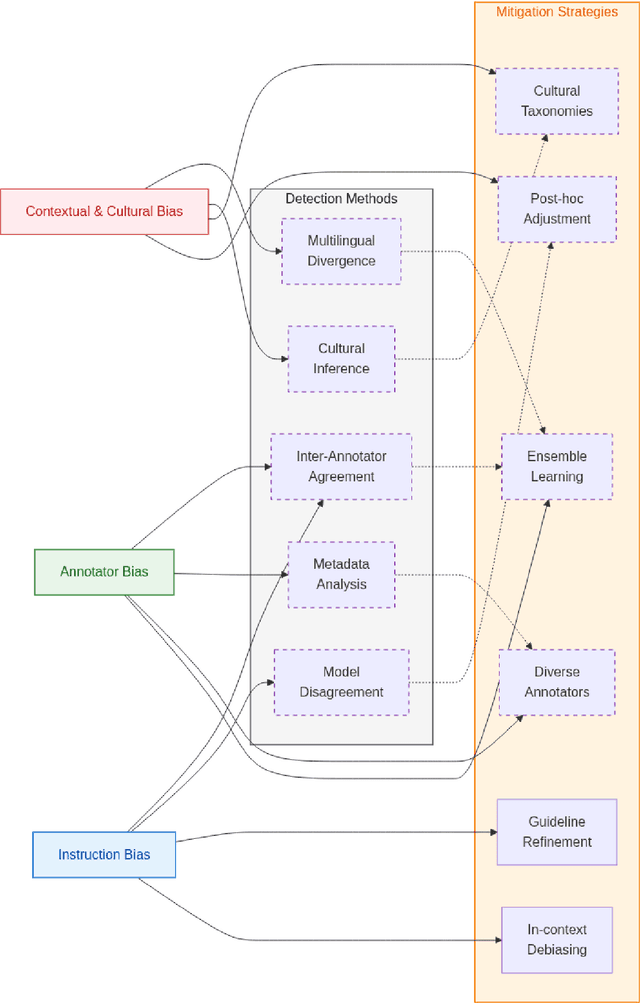
Annotation bias in NLP datasets remains a major challenge for developing multilingual Large Language Models (LLMs), particularly in culturally diverse settings. Bias from task framing, annotator subjectivity, and cultural mismatches can distort model outputs and exacerbate social harms. We propose a comprehensive framework for understanding annotation bias, distinguishing among instruction bias, annotator bias, and contextual and cultural bias. We review detection methods (including inter-annotator agreement, model disagreement, and metadata analysis) and highlight emerging techniques such as multilingual model divergence and cultural inference. We further outline proactive and reactive mitigation strategies, including diverse annotator recruitment, iterative guideline refinement, and post-hoc model adjustments. Our contributions include: (1) a typology of annotation bias; (2) a synthesis of detection metrics; (3) an ensemble-based bias mitigation approach adapted for multilingual settings, and (4) an ethical analysis of annotation processes. Together, these insights aim to inform more equitable and culturally grounded annotation pipelines for LLMs.
Addressing Data Imbalance in Transformer-Based Multi-Label Emotion Detection with Weighted Loss
Jul 15, 2025This paper explores the application of a simple weighted loss function to Transformer-based models for multi-label emotion detection in SemEval-2025 Shared Task 11. Our approach addresses data imbalance by dynamically adjusting class weights, thereby enhancing performance on minority emotion classes without the computational burden of traditional resampling methods. We evaluate BERT, RoBERTa, and BART on the BRIGHTER dataset, using evaluation metrics such as Micro F1, Macro F1, ROC-AUC, Accuracy, and Jaccard similarity coefficients. The results demonstrate that the weighted loss function improves performance on high-frequency emotion classes but shows limited impact on minority classes. These findings underscore both the effectiveness and the challenges of applying this approach to imbalanced multi-label emotion detection.
Multi-source Attention for Unsupervised Domain Adaptation
Apr 17, 2020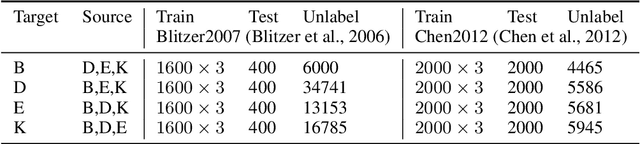
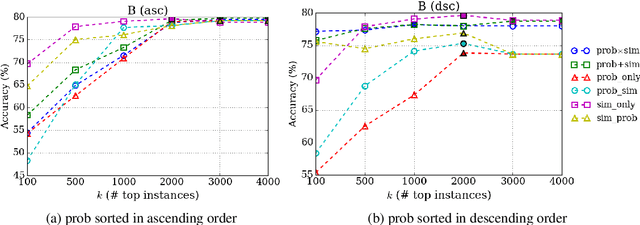
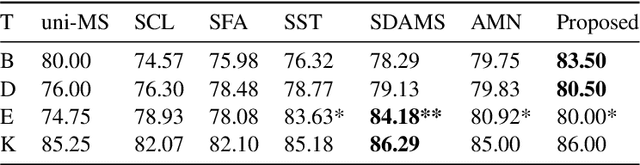
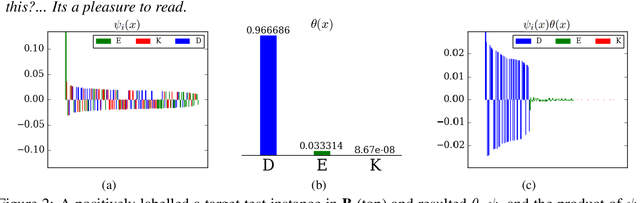
Domain adaptation considers the problem of generalising a model learnt using data from a particular source domain to a different target domain. Often it is difficult to find a suitable single source to adapt from, and one must consider multiple sources. Using an unrelated source can result in sub-optimal performance, known as the \emph{negative transfer}. However, it is challenging to select the appropriate source(s) for classifying a given target instance in multi-source unsupervised domain adaptation (UDA). We model source-selection as an attention-learning problem, where we learn attention over sources for a given target instance. For this purpose, we first independently learn source-specific classification models, and a relatedness map between sources and target domains using pseudo-labelled target domain instances. Next, we learn attention-weights over the sources for aggregating the predictions of the source-specific models. Experimental results on cross-domain sentiment classification benchmarks show that the proposed method outperforms prior proposals in multi-source UDA.