 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Laws for Neural Machine Translation
Sep 16, 2021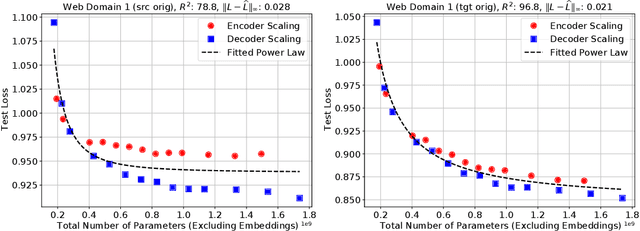
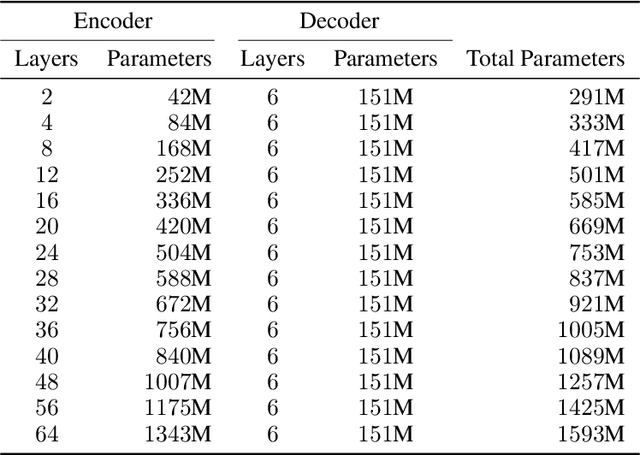
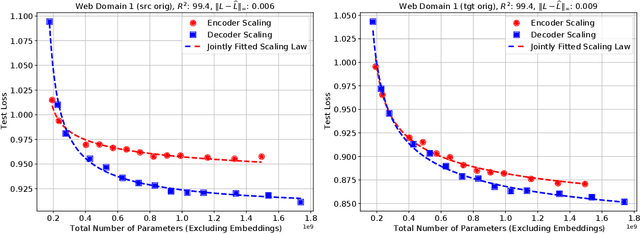
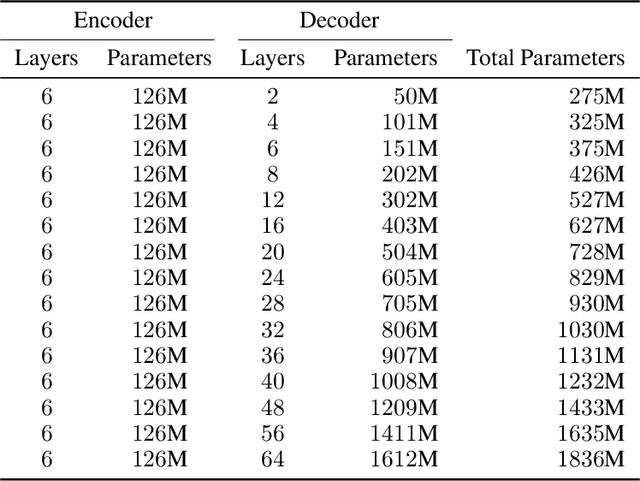
We present an empirical study of scaling properties of encoder-decoder Transformer models used in neural machine translation (NMT). We show that cross-entropy loss as a function of model size follows a certain scaling law. Specifically (i) We propose a formula which describes the scaling behavior of cross-entropy loss as a bivariate function of encoder and decoder size, and show that it gives accurate predictions under a variety of scaling approaches and languages; we show that the total number of parameters alone is not sufficient for such purposes. (ii) We observe different power law exponents when scaling the decoder vs scaling the encoder, and provide recommendations for optimal allocation of encoder/decoder capacity based on this observation. (iii) We also report that the scaling behavior of the model is acutely influenced by composition bias of the train/test sets, which we define as any deviation from naturally generated text (either via machine generated or human translated text). We observe that natural text on the target side enjoys scaling, which manifests as successful reduction of the cross-entropy loss. (iv) Finally, we investigate the relationship between the cross-entropy loss and the quality of the generated translations. We find two different behaviors, depending on the nature of the test data. For test sets which were originally translated from target language to source language, both loss and BLEU score improve as model size increases. In contrast, for test sets originally translated from source language to target language, the loss improves, but the BLEU score stops improving after a certain threshold. We release generated text from all models used in this study.
Towards Universality in Multilingual Text Rewriting
Jul 30, 2021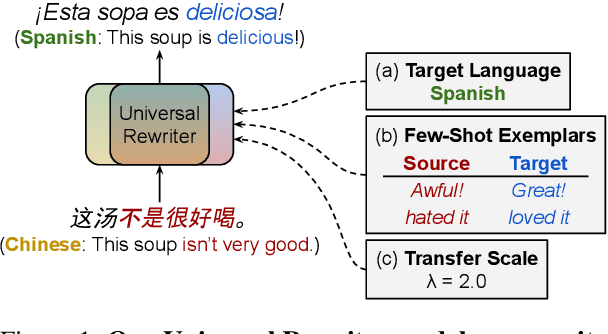
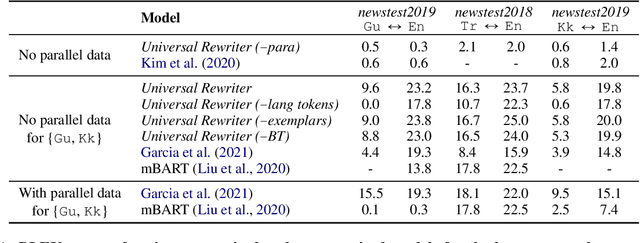
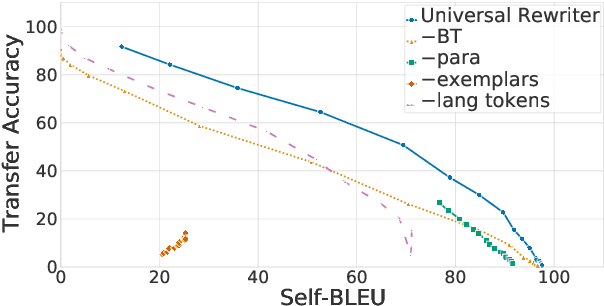

In this work, we take the first steps towards building a universal rewriter: a model capable of rewriting text in any language to exhibit a wide variety of attributes, including styles and languages, while preserving as much of the original semantics as possible. In addition to obtaining state-of-the-art results on unsupervised translation, we also demonstrate the ability to do zero-shot sentiment transfer in non-English languages using only English exemplars for sentiment. We then show that our model is able to modify multiple attributes at once, for example adjusting both language and sentiment jointly. Finally, we show that our model is capable of performing zero-shot formality-sensitive translation.
Towards Continual Learning for Multilingual Machine Translation via Vocabulary Substitution
Mar 11, 2021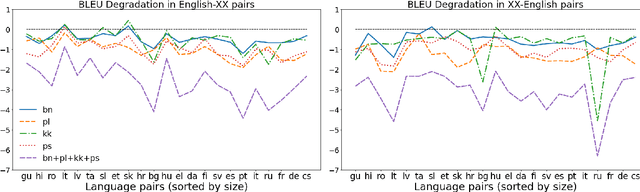
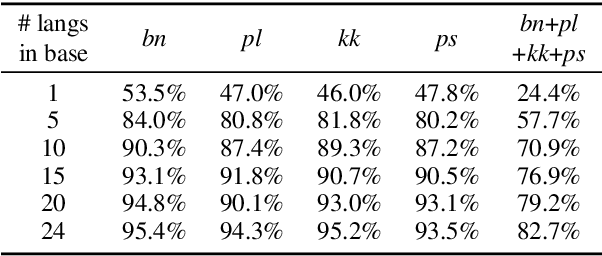
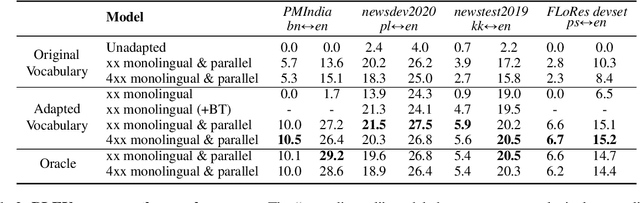
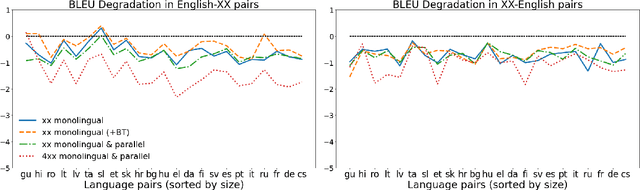
We propose a straightforward vocabulary adaptation scheme to extend the language capacity of multilingual machine translation models, paving the way towards efficient continual learning for multilingual machine translation. Our approach is suitable for large-scale datasets, applies to distant languages with unseen scripts, incurs only minor degradation on the translation performance for the original language pairs and provides competitive performance even in the case where we only possess monolingual data for the new languages.
Harnessing Multilinguality in Unsupervised Machine Translation for Rare Languages
Sep 23, 2020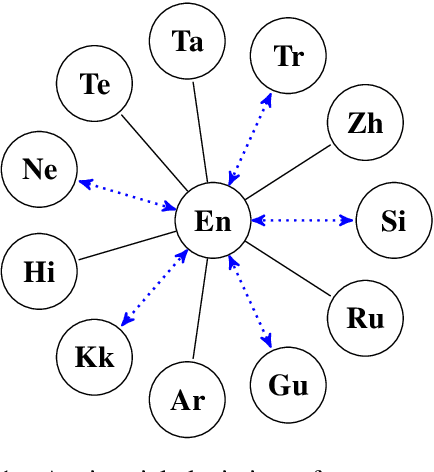

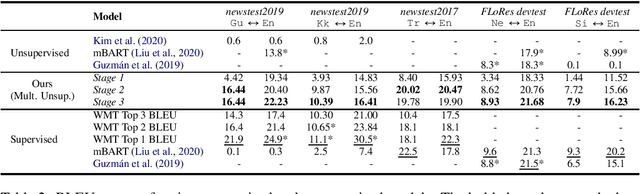
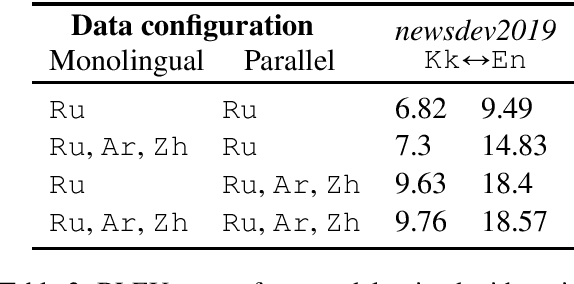
Unsupervised translation has reached impressive performance on resource-rich language pairs such as English-French and English-German. However, early studies have shown that in more realistic settings involving low-resource, rare languages, unsupervised translation performs poorly, achieving less than 3.0 BLEU. In this work, we show that multilinguality is critical to making unsupervised systems practical for low-resource settings. In particular, we present a single model for 5 low-resource languages (Gujarati, Kazakh, Nepali, Sinhala, and Turkish) to and from English directions, which leverages monolingual and auxiliary parallel data from other high-resource language pairs via a three-stage training scheme. We outperform all current state-of-the-art unsupervised baselines for these languages, achieving gains of up to 14.4 BLEU. Additionally, we outperform a large collection of supervised WMT submissions for various language pairs as well as match the performance of the current state-of-the-art supervised model for Nepali-English. We conduct a series of ablation studies to establish the robustness of our model under different degrees of data quality, as well as to analyze the factors which led to the superior performance of the proposed approach over traditional unsupervised models.
Machine learning applied in the multi-scale 3D stress modelling
Aug 25, 2020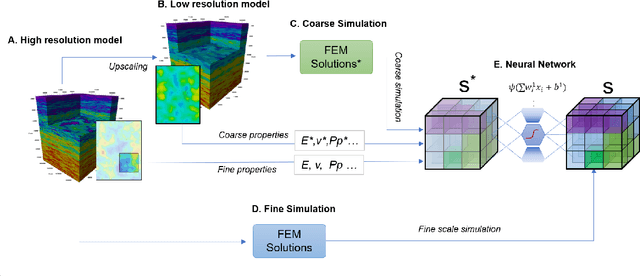
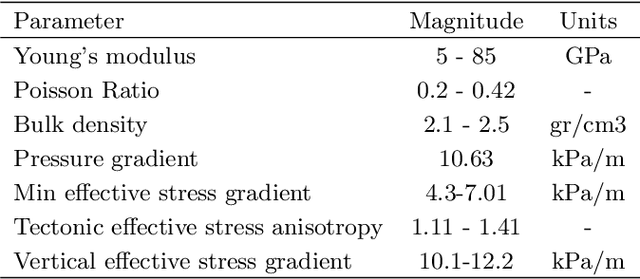

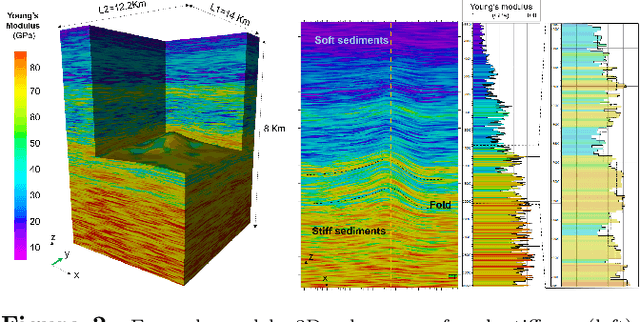
This paper proposes a methodology to estimate stress in the subsurface by a hybrid method combining finite element modeling and neural networks. This methodology exploits the idea of obtaining a multi-frequency solution in the numerical modeling of systems whose behavior involves a wide span of length scales. One low-frequency solution is obtained via inexpensive finite element modeling at a coarse scale. The second solution provides the fine-grained details introduced by the heterogeneity of the free parameters at the fine scale. This high-frequency solution is estimated via neural networks -trained with partial solutions obtained in high-resolution finite-element models. When the coarse finite element solutions are combined with the neural network estimates, the results are within a 2\% error of the results that would be computed with high-resolution finite element models. This paper discusses the benefits and drawbacks of the method and illustrates their applicability via a worked example.
A Multilingual View of Unsupervised Machine Translation
Feb 21, 2020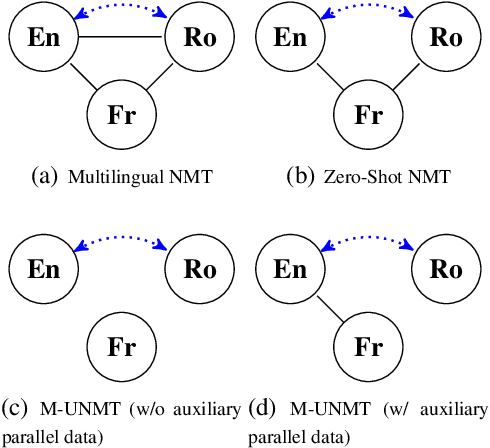
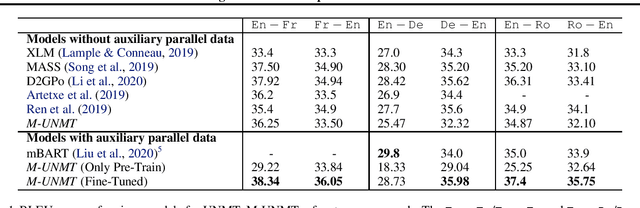
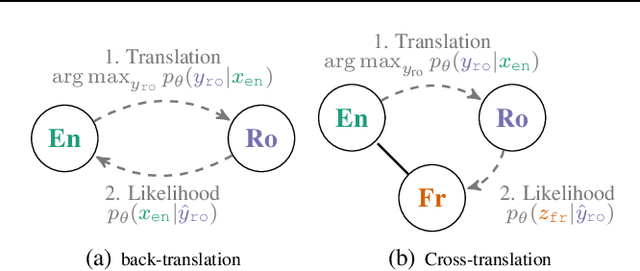
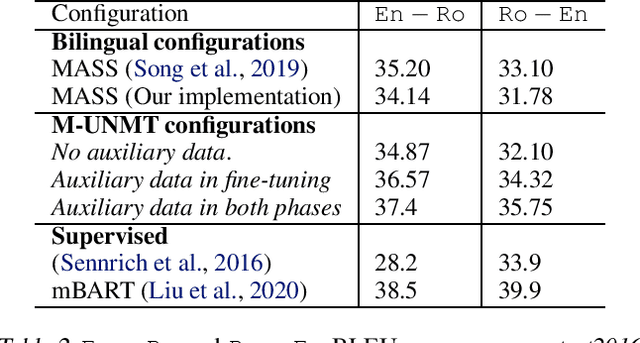
We present a probabilistic framework for multilingual neural machine translation that encompasses supervised and unsupervised setups, focusing on unsupervised translation. In addition to studying the vanilla case where there is only monolingual data available, we propose a novel setup where one language in the (source, target) pair is not associated with any parallel data, but there may exist auxiliary parallel data that contains the other. This auxiliary data can naturally be utilized in our probabilistic framework via a novel cross-translation loss term. Empirically, we show that our approach results in higher BLEU scores over state-of-the-art unsupervised models on the WMT'14 English-French, WMT'16 English-German, and WMT'16 English-Romanian datasets in most directions. In particular, we obtain a +1.65 BLEU advantage over the best-performing unsupervised model in the Romanian-English direction.