 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning a Robust Low-Level Agnostic Controller for a Quadrotor with Actor-Critic Reinforcement Learning
Oct 06, 2022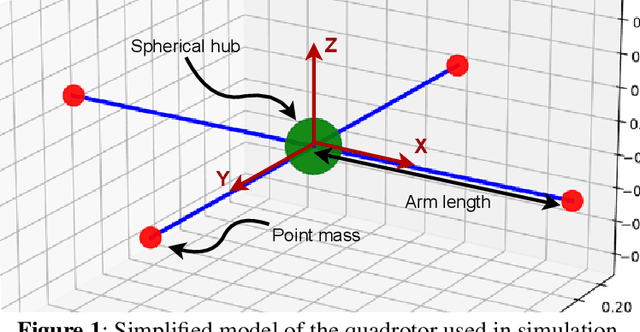
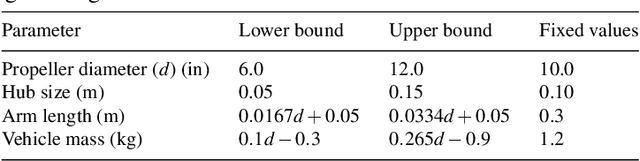

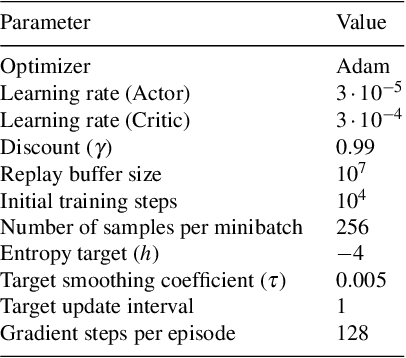
Purpose: Real-life applications using quadrotors introduce a number of disturbances and time-varying properties that pose a challenge to flight controllers. We observed that, when a quadrotor is tasked with picking up and dropping a payload, traditional PID and RL-based controllers found in literature struggle to maintain flight after the vehicle changes its dynamics due to interaction with this external object. Methods: In this work, we introduce domain randomization during the training phase of a low-level waypoint guidance controller based on Soft Actor-Critic. The resulting controller is evaluated on the proposed payload pick up and drop task with added disturbances that emulate real-life operation of the vehicle. Results & Conclusion: We show that, by introducing a certain degree of uncertainty in quadrotor dynamics during training, we can obtain a controller that is capable to perform the proposed task using a larger variation of quadrotor parameters. Additionally, the RL-based controller outperforms a traditional positional PID controller with optimized gains in this task, while remaining agnostic to different simulation parameters.
Online Weighted Q-Ensembles for Reduced Hyperparameter Tuning in Reinforcement Learning
Sep 29, 2022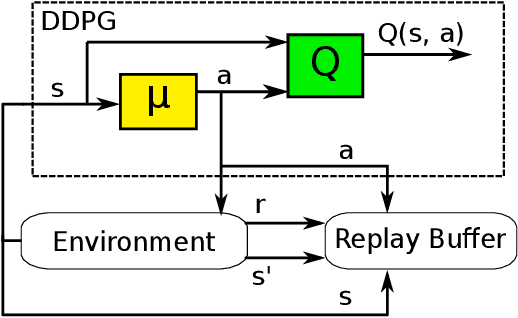
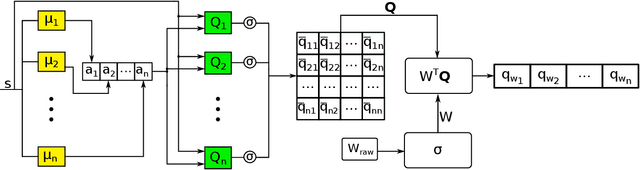
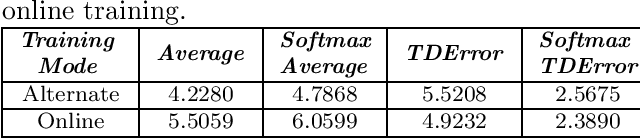
Reinforcement learning is a promising paradigm for learning robot control, allowing complex control policies to be learned without requiring a dynamics model. However, even state of the art algorithms can be difficult to tune for optimum performance. We propose employing an ensemble of multiple reinforcement learning agents, each with a different set of hyperparameters, along with a mechanism for choosing the best performing set(s) on-line. In the literature, the ensemble technique is used to improve performance in general, but the current work specifically addresses decreasing the hyperparameter tuning effort. Furthermore, our approach targets on-line learning on a single robotic system, and does not require running multiple simulators in parallel. Although the idea is generic, the Deep Deterministic Policy Gradient was the model chosen, being a representative deep learning actor-critic method with good performance in continuous action settings but known high variance. We compare our online weighted q-ensemble approach to q-average ensemble strategies addressed in literature using alternate policy training, as well as online training, demonstrating the advantage of the new approach in eliminating hyperparameter tuning. The applicability to real-world systems was validated in common robotic benchmark environments: the bipedal robot half cheetah and the swimmer. Online Weighted Q-Ensemble presented overall lower variance and superior results when compared with q-average ensembles using randomized parameterizations.
Deep Reinforcement Learning with Embedded LQR Controllers
Jan 18, 2021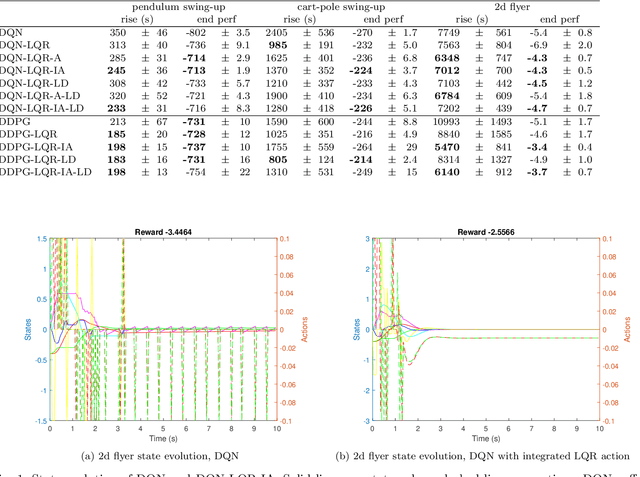
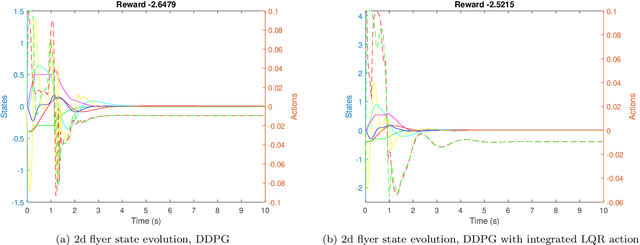
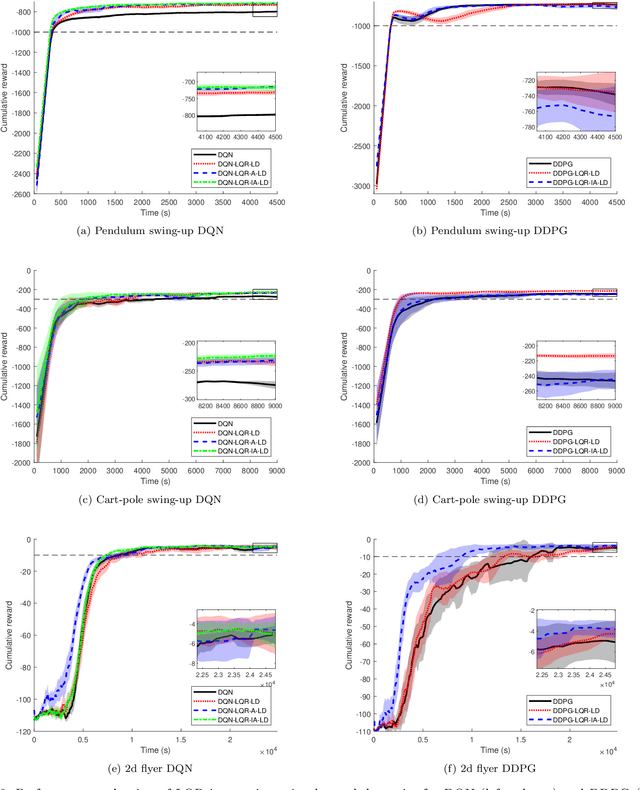

Reinforcement learning is a model-free optimal control method that optimizes a control policy through direct interaction with the environment. For reaching tasks that end in regulation, popular discrete-action methods are not well suited due to chattering in the goal state. We compare three different ways to solve this problem through combining reinforcement learning with classical LQR control. In particular, we introduce a method that integrates LQR control into the action set, allowing generalization and avoiding fixing the computed control in the replay memory if it is based on learned dynamics. We also embed LQR control into a continuous-action method. In all cases, we show that adding LQR control can improve performance, although the effect is more profound if it can be used to augment a discrete action set.
Deep Reinforcement Learning for Haptic Shared Control in Unknown Tasks
Jan 15, 2021
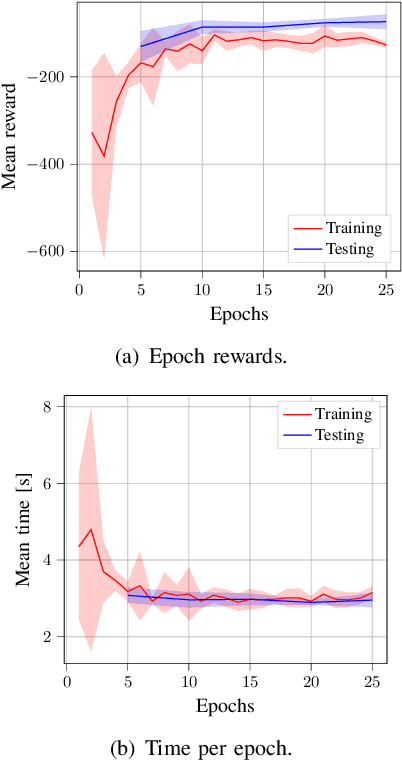
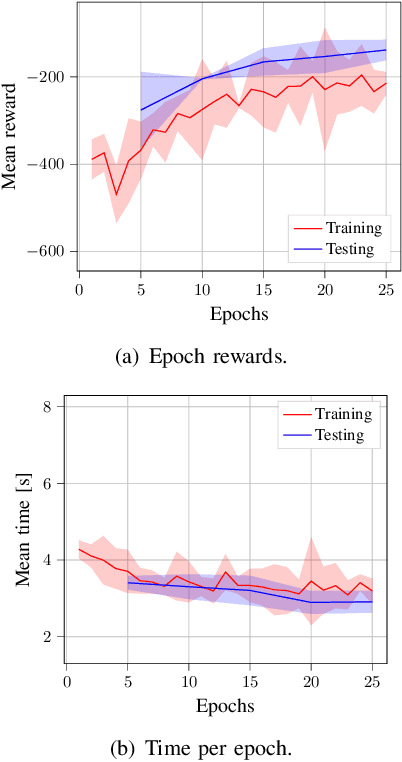
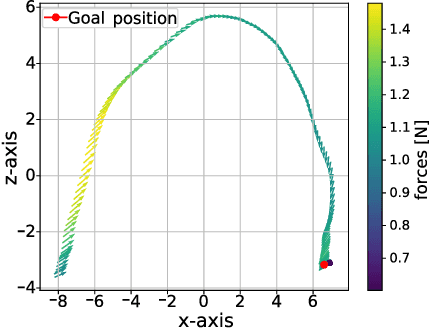
Recent years have shown a growing interest in using haptic shared control (HSC) in teleoperated systems. In HSC, the application of virtual guiding forces decreases the user's control effort and improves execution time in various tasks, presenting a good alternative in comparison with direct teleoperation. HSC, despite demonstrating good performance, opens a new gap: how to design the guiding forces. For this reason, the challenge lies in developing controllers to provide the optimal guiding forces for the tasks that are being performed. This work addresses this challenge by designing a controller based on the deep deterministic policy gradient (DDPG) algorithm to provide the assistance, and a convolutional neural network (CNN) to perform the task detection, called TAHSC (Task Agnostic Haptic Shared Controller). The agent learns to minimize the time it takes the human to execute the desired task, while simultaneously minimizing their resistance to the provided feedback. This resistance thus provides the learning algorithm with information about which direction the human is trying to follow, in this case, the pick-and-place task. Diverse results demonstrate the successful application of the proposed approach by learning custom policies for each user who was asked to test the system. It exhibits stable convergence and aids the user in completing the task with the least amount of time possible.