 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAGE: Sign-Adaptive Gradient for Memory-Efficient LLM Optimization
Apr 09, 2026The AdamW optimizer, while standard for LLM pretraining, is a critical memory bottleneck, consuming optimizer states equivalent to twice the model's size. Although light-state optimizers like SinkGD attempt to address this issue, we identify the embedding layer dilemma: these methods fail to handle the sparse, high-variance gradients inherent to embeddings, forcing a hybrid design that reverts to AdamW and partially negates the memory gains. We propose SAGE (Sign Adaptive GradiEnt), a novel optimizer that resolves this dilemma by replacing AdamW in this hybrid structure. SAGE combines a Lion-style update direction with a new, memory-efficient $O(d)$ adaptive scale. This scale acts as a "safe damper," provably bounded by 1.0, which tames high-variance dimensions more effectively than existing methods. This superior stability allows SAGE to achieve better convergence. On Llama models up to 1.3B parameters, our SAGE-based hybrid achieves new state-of-the-art perplexity, outperforming all baselines, including SinkGD hybrid, while significantly reducing optimizer state memory.
An Evaluation Dataset and Strategy for Building Robust Multi-turn Response Selection Model
Sep 10, 2021



Multi-turn response selection models have recently shown comparable performance to humans in several benchmark datasets. However, in the real environment, these models often have weaknesses, such as making incorrect predictions based heavily on superficial patterns without a comprehensive understanding of the context. For example, these models often give a high score to the wrong response candidate containing several keywords related to the context but using the inconsistent tense. In this study, we analyze the weaknesses of the open-domain Korean Multi-turn response selection models and publish an adversarial dataset to evaluate these weaknesses. We also suggest a strategy to build a robust model in this adversarial environment.
CoMPM: Context Modeling with Speaker's Pre-trained Memory Tracking for Emotion Recognition in Conversation
Aug 26, 2021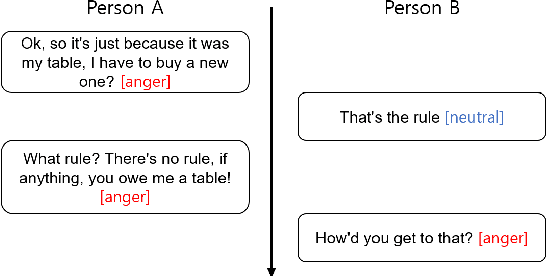
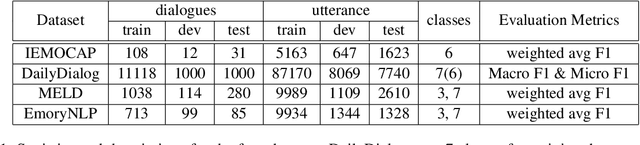
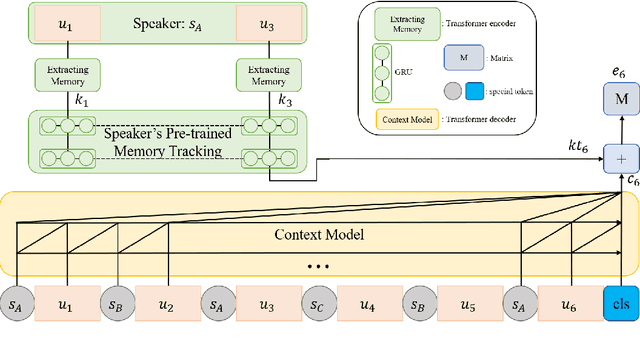
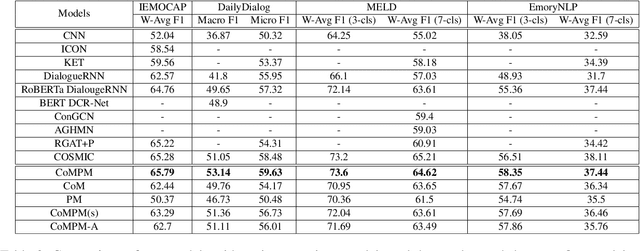
As the use of interactive machines grow, the task of Emotion Recognition in Conversation (ERC) became more important. If the machine generated sentences reflect emotion, more human-like sympathetic conversations are possible. Since emotion recognition in conversation is inaccurate if the previous utterances are not taken into account, many studies reflect the dialogue context to improve the performances. We introduce CoMPM, a context embedding module (CoM) combined with a pre-trained memory module (PM) that tracks memory of the speaker's previous utterances within the context, and show that the pre-trained memory significantly improves the final accuracy of emotion recognition. We experimented on both the multi-party datasets (MELD, EmoryNLP) and the dyadic-party datasets (IEMOCAP, DailyDialog), showing that our approach achieve competitive performance on all datasets.