 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Capability Frontier: Benchmarks Miss 82% of Model Performance
Jun 25, 2026Existing benchmarks typically report accuracy for a single model on a single run. This systematically understates real-world LLM capabilities, particularly under heterogeneous data distributions: (i) different models get different questions correct according to their specializations, and (ii) given a budget, multiple generations can be sampled and selectively retained. To quantify this gap, we introduce the Capability Frontier: a Pareto frontier over a set of models that characterizes the best achievable performance at each cost level under optimal selection across models and generations (i.e., via an oracle). Our construction corrects for two opposing biases: underestimation from single-model evaluation and overestimation from taking maxima over noisy samples. We study 21 LLMs across 16 widely used benchmarks spanning coding, reasoning, medicine, factuality, instruction following, and agentic tasks, comparing Capability Frontier performance at matched cost to each benchmark's top-performing model. Correcting for single-model evaluation yields a 54% error rate reduction; additionally correcting for single runs yields an 82% improvement, with SOTA accuracy matched at 85% cost reduction. Complementing these empirical results, we use controlled probabilistic simulations to show that higher query topic entropy produces a near-monotonic increase in the performance gap between oracle routing and the best single model. Our findings suggest collective LLM capabilities are substantially underestimated, with implications for evaluation and deployment in data-heterogeneous, multi-domain settings.
Embedding Grammars
Aug 14, 2018
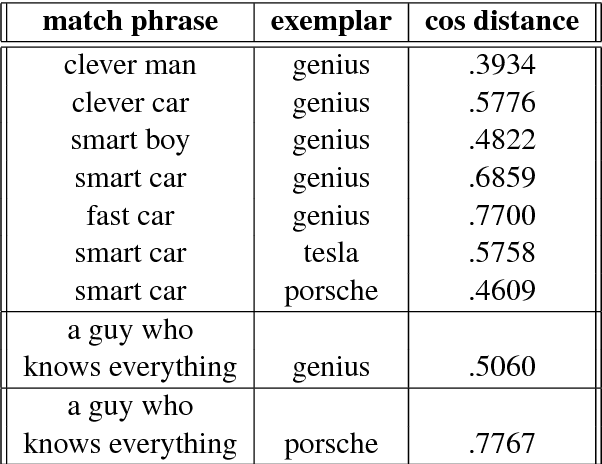
Classic grammars and regular expressions can be used for a variety of purposes, including parsing, intent detection, and matching. However, the comparisons are performed at a structural level, with constituent elements (words or characters) matched exactly. Recent advances in word embeddings show that semantically related words share common features in a vector-space representation, suggesting the possibility of a hybrid grammar and word embedding. In this paper, we blend the structure of standard context-free grammars with the semantic generalization capabilities of word embeddings to create hybrid semantic grammars. These semantic grammars generalize the specific terminals used by the programmer to other words and phrases with related meanings, allowing the construction of compact grammars that match an entire region of the vector space rather than matching specific elements.