 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHEIR: Learning Graph-Based Motion Hierarchies
Oct 30, 2025Hierarchical structures of motion exist across research fields, including computer vision, graphics, and robotics, where complex dynamics typically arise from coordinated interactions among simpler motion components. Existing methods to model such dynamics typically rely on manually-defined or heuristic hierarchies with fixed motion primitives, limiting their generalizability across different tasks. In this work, we propose a general hierarchical motion modeling method that learns structured, interpretable motion relationships directly from data. Our method represents observed motions using graph-based hierarchies, explicitly decomposing global absolute motions into parent-inherited patterns and local motion residuals. We formulate hierarchy inference as a differentiable graph learning problem, where vertices represent elemental motions and directed edges capture learned parent-child dependencies through graph neural networks. We evaluate our hierarchical reconstruction approach on three examples: 1D translational motion, 2D rotational motion, and dynamic 3D scene deformation via Gaussian splatting. Experimental results show that our method reconstructs the intrinsic motion hierarchy in 1D and 2D cases, and produces more realistic and interpretable deformations compared to the baseline on dynamic 3D Gaussian splatting scenes. By providing an adaptable, data-driven hierarchical modeling paradigm, our method offers a formulation applicable to a broad range of motion-centric tasks. Project Page: https://light.princeton.edu/HEIR/
* Code link: https://github.com/princeton-computational-imaging/HEIR
Flight Controller Synthesis Via Deep Reinforcement Learning
Sep 14, 2019



Traditional control methods are inadequate in many deployment settings involving control of Cyber-Physical Systems (CPS). In such settings, CPS controllers must operate and respond to unpredictable interactions, conditions, or failure modes. Dealing with such unpredictability requires the use of executive and cognitive control functions that allow for planning and reasoning. Motivated by the sport of drone racing, this dissertation addresses these concerns for state-of-the-art flight control by investigating the use of deep neural networks to bring essential elements of higher-level cognition for constructing low level flight controllers. This thesis reports on the development and release of an open source, full solution stack for building neuro-flight controllers. This stack consists of the methodology for constructing a multicopter digital twin for synthesize the flight controller unique to a specific aircraft, a tuning framework for implementing training environments (GymFC), and a firmware for the world's first neural network supported flight controller (Neuroflight). GymFC's novel approach fuses together the digital twinning paradigm for flight control training to provide seamless transfer to hardware. Additionally, this thesis examines alternative reward system functions as well as changes to the software environment to bridge the gap between the simulation and real world deployment environments. Work summarized in this thesis demonstrates that reinforcement learning is able to be leveraged for training neural network controllers capable, not only of maintaining stable flight, but also precision aerobatic maneuvers in real world settings. As such, this work provides a foundation for developing the next generation of flight control systems.
Neuroflight: Next Generation Flight Control Firmware
Jan 19, 2019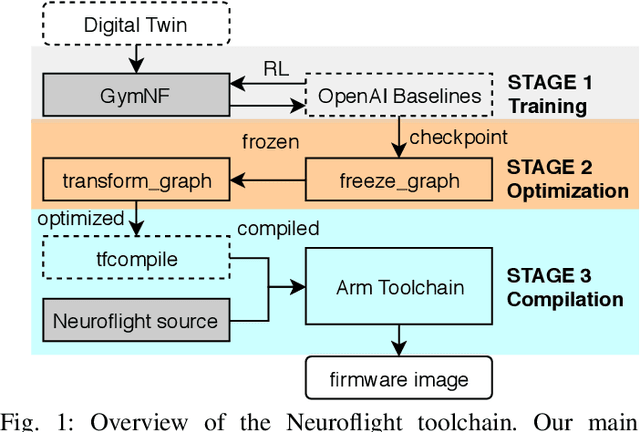
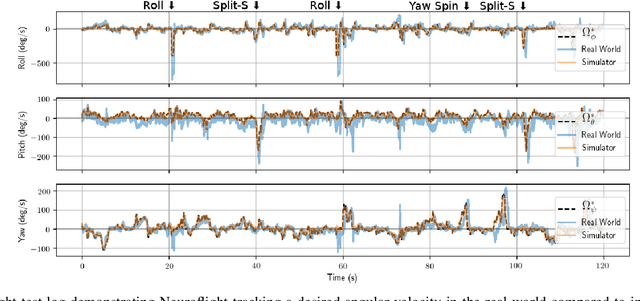

Little innovation has been made to low-level attitude flight control used by unmanned aerial vehicles, which still predominantly uses the classical PID controller. In this work we introduce Neuroflight, the first open source neuro-flight controller firmware. We present our toolchain for training a neural network in simulation and compiling it to run on embedded hardware. Challenges faced jumping from simulation to reality are discussed along with our solutions. Our evaluation shows the neural network can execute at over 2.67kHz on an Arm Cortex-M7 processor and flight tests demonstrate a quadcopter running Neuroflight can achieve stable flight and execute aerobatic maneuvers.
Reinforcement Learning for UAV Attitude Control
Apr 11, 2018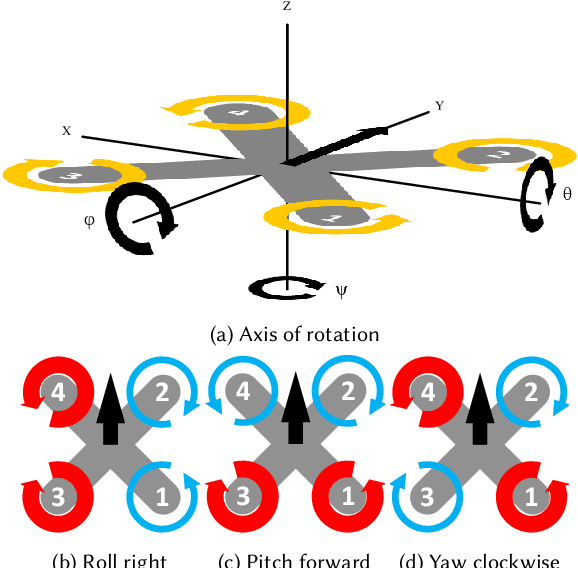
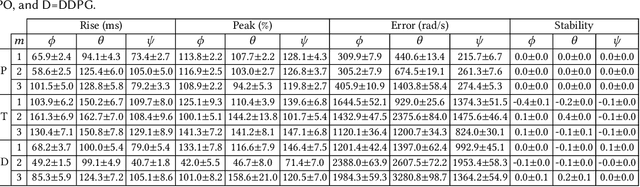
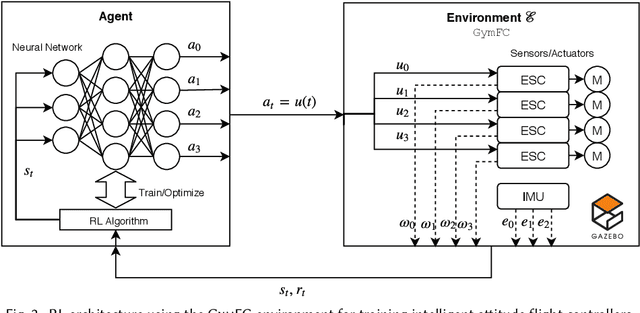
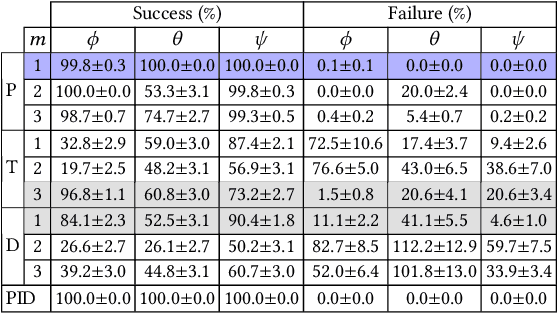
Autopilot systems are typically composed of an "inner loop" providing stability and control, while an "outer loop" is responsible for mission-level objectives, e.g. way-point navigation. Autopilot systems for UAVs are predominately implemented using Proportional, Integral Derivative (PID) control systems, which have demonstrated exceptional performance in stable environments. However more sophisticated control is required to operate in unpredictable, and harsh environments. Intelligent flight control systems is an active area of research addressing limitations of PID control most recently through the use of reinforcement learning (RL) which has had success in other applications such as robotics. However previous work has focused primarily on using RL at the mission-level controller. In this work, we investigate the performance and accuracy of the inner control loop providing attitude control when using intelligent flight control systems trained with the state-of-the-art RL algorithms, Deep Deterministic Gradient Policy (DDGP), Trust Region Policy Optimization (TRPO) and Proximal Policy Optimization (PPO). To investigate these unknowns we first developed an open-source high-fidelity simulation environment to train a flight controller attitude control of a quadrotor through RL. We then use our environment to compare their performance to that of a PID controller to identify if using RL is appropriate in high-precision, time-critical flight control.