 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken Management in Multi-Tenant AI Inference Platforms
Feb 27, 2026Multi-tenant AI inference platforms must balance resource utilization against service-level guarantees under variable demand. Conventional approaches fail to achieve this balance: dedicated endpoints strand capacity on idle models, while rate limits ignore the heterogeneous cost of inference requests. We introduce \emph{token pools}, a control-plane abstraction that represents inference capacity as explicit entitlements expressed in inference-native units (token throughput, KV cache, concurrency). Unlike rate limits, which govern request admission without regard to execution cost, token pools authorize both admission and autoscaling from the same capacity model, ensuring consistency between what is promised and what is provisioned. The abstraction captures burst modes across multiple dimensions invisible to conventional throttling. Dynamic per-entitlement limits on each burst dimension enable fine-grained control over resource consumption while permitting work-conserving backfill by low-priority traffic. The design supports priority-aware allocation, service tiers with differentiated guarantees, and debt-based fairness mechanisms, all without modifying the underlying inference runtime or cluster scheduler. In experiments on a Kubernetes cluster with vLLM backends, token pools maintain a bounded P99 latency for guaranteed workloads during overload by selectively throttling spot traffic, while a baseline without admission control experiences unbounded latency degradation across all workloads. A second experiment demonstrates debt-based fair-share convergence among elastic workloads with heterogeneous SLO requirements during capacity scarcity.
The Autodidactic Universe
Mar 29, 2021
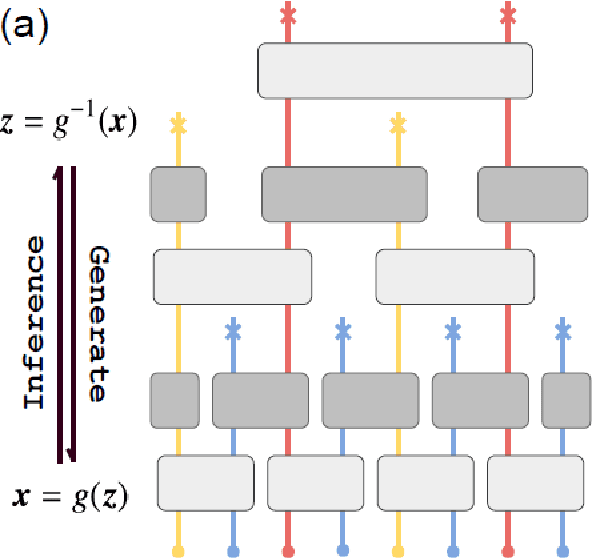
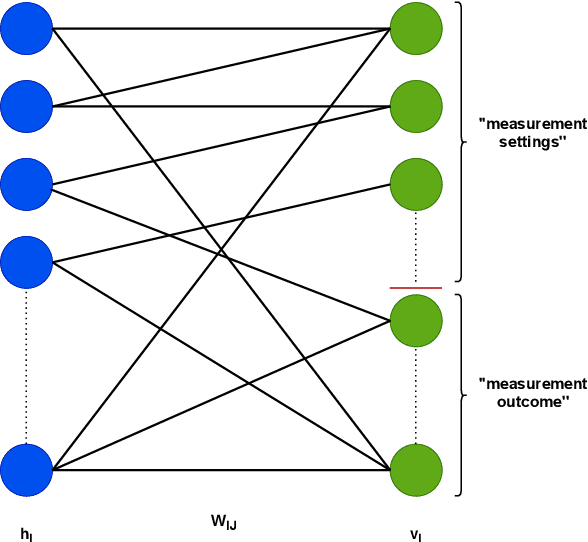
We present an approach to cosmology in which the Universe learns its own physical laws. It does so by exploring a landscape of possible laws, which we express as a certain class of matrix models. We discover maps that put each of these matrix models in correspondence with both a gauge/gravity theory and a mathematical model of a learning machine, such as a deep recurrent, cyclic neural network. This establishes a correspondence between each solution of the physical theory and a run of a neural network. This correspondence is not an equivalence, partly because gauge theories emerge from $N \rightarrow \infty $ limits of the matrix models, whereas the same limits of the neural networks used here are not well-defined. We discuss in detail what it means to say that learning takes place in autodidactic systems, where there is no supervision. We propose that if the neural network model can be said to learn without supervision, the same can be said for the corresponding physical theory. We consider other protocols for autodidactic physical systems, such as optimization of graph variety, subset-replication using self-attention and look-ahead, geometrogenesis guided by reinforcement learning, structural learning using renormalization group techniques, and extensions. These protocols together provide a number of directions in which to explore the origin of physical laws based on putting machine learning architectures in correspondence with physical theories.