 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Robustness of Vision in Open Foundation Models
Dec 19, 2025



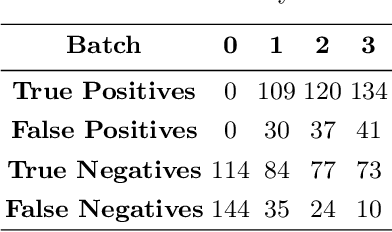
With the increase in deep learning, it becomes increasingly difficult to understand the model in which AI systems can identify objects. Thus, an adversary could aim to modify an image by adding unseen elements, which will confuse the AI in its recognition of an entity. This paper thus investigates the adversarial robustness of LLaVA-1.5-13B and Meta's Llama 3.2 Vision-8B-2. These are tested for untargeted PGD (Projected Gradient Descent) against the visual input modality, and empirically evaluated on the Visual Question Answering (VQA) v2 dataset subset. The results of these adversarial attacks are then quantified using the standard VQA accuracy metric. This evaluation is then compared with the accuracy degradation (accuracy drop) of LLaVA and Llama 3.2 Vision. A key finding is that Llama 3.2 Vision, despite a lower baseline accuracy in this setup, exhibited a smaller drop in performance under attack compared to LLaVA, particularly at higher perturbation levels. Overall, the findings confirm that the vision modality represents a viable attack vector for degrading the performance of contemporary open-weight VLMs, including Meta's Llama 3.2 Vision. Furthermore, they highlight that adversarial robustness does not necessarily correlate directly with standard benchmark performance and may be influenced by underlying architectural and training factors.
A Distributed Trust Framework for Privacy-Preserving Machine Learning
Jun 03, 2020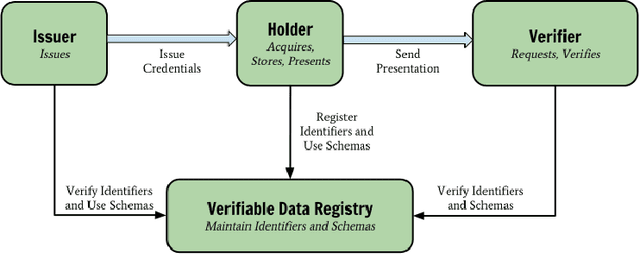
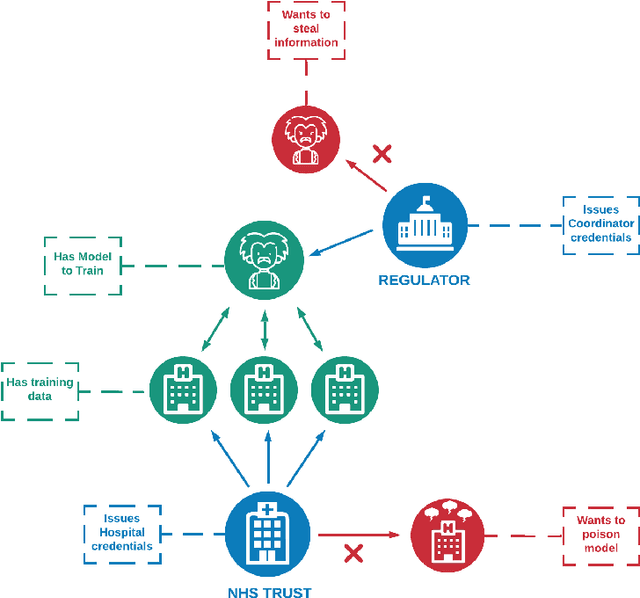
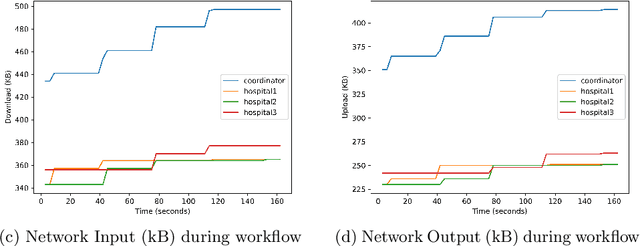
When training a machine learning model, it is standard procedure for the researcher to have full knowledge of both the data and model. However, this engenders a lack of trust between data owners and data scientists. Data owners are justifiably reluctant to relinquish control of private information to third parties. Privacy-preserving techniques distribute computation in order to ensure that data remains in the control of the owner while learning takes place. However, architectures distributed amongst multiple agents introduce an entirely new set of security and trust complications. These include data poisoning and model theft. This paper outlines a distributed infrastructure which is used to facilitate peer-to-peer trust between distributed agents; collaboratively performing a privacy-preserving workflow. Our outlined prototype sets industry gatekeepers and governance bodies as credential issuers. Before participating in the distributed learning workflow, malicious actors must first negotiate valid credentials. We detail a proof of concept using Hyperledger Aries, Decentralised Identifiers (DIDs) and Verifiable Credentials (VCs) to establish a distributed trust architecture during a privacy-preserving machine learning experiment. Specifically, we utilise secure and authenticated DID communication channels in order to facilitate a federated learning workflow related to mental health care data.