 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlatland: The Adventures of Gradient Descent with Large Step Sizes
Jun 04, 2026The training of neural networks often entails objective functions that are not globally $L$-smooth. For these functions, it is both theoretically and practically difficult to reply to the question: what is the largest possible step size that ensures the convergence of gradient descent (GD)? We address this longstanding open question in deep learning by providing a unifying definition of "large" step sizes that requires only local Lipschitz (or even Hölder) continuity of the gradient. We design first-order adaptive methods that provably yield large step sizes and show that they operate at the edge of stability (EoS) right from the start of the training. In particular, the loss decreases nonmonotonically and the product between the step size and sharpness, i.e., the largest eigenvalue of the Hessian, stays above the EoS threshold of 2 throughout training. Using our method, we are also able to minimize the sharpness all the way down to its global minimum. Contrary to expectation, we find that encountering globally-flat regions too early in the training may both slow down convergence and jeopardize the generalization ability of the network. Exploiting a self-stabilization argument, we allow GD to enter slightly sharper valleys and turn unsuccessful training runs into very successful ones.
Path classification by stochastic linear recurrent neural networks
Aug 06, 2021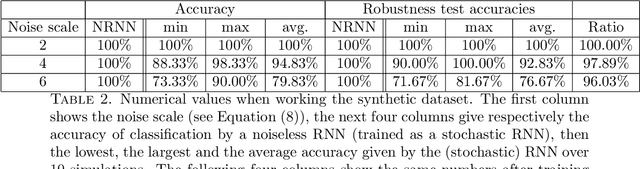
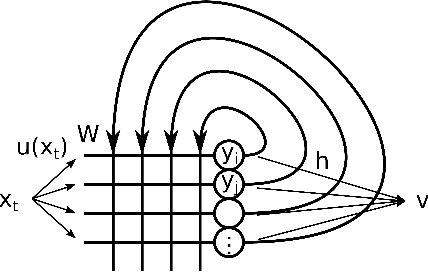
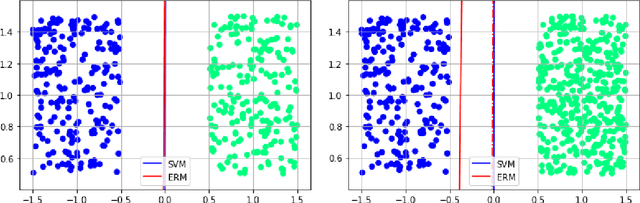
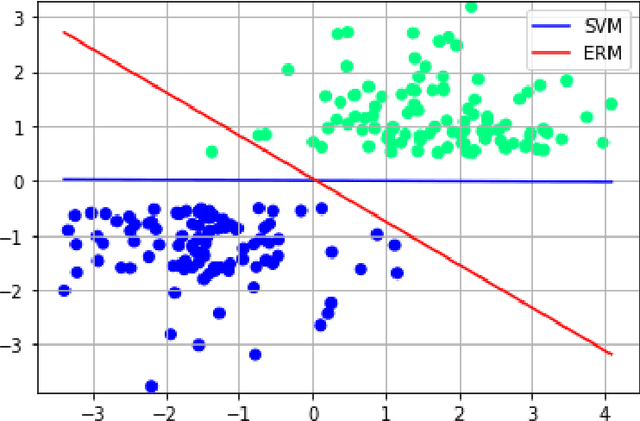
We investigate the functioning of a classifying biological neural network from the perspective of statistical learning theory, modelled, in a simplified setting, as a continuous-time stochastic recurrent neural network (RNN) with identity activation function. In the purely stochastic (robust) regime, we give a generalisation error bound that holds with high probability, thus showing that the empirical risk minimiser is the best-in-class hypothesis. We show that RNNs retain a partial signature of the paths they are fed as the unique information exploited for training and classification tasks. We argue that these RNNs are easy to train and robust and back these observations with numerical experiments on both synthetic and real data. We also exhibit a trade-off phenomenon between accuracy and robustness.