 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning To Rank Resources with GNN
Apr 17, 2023As the content on the Internet continues to grow, many new dynamically changing and heterogeneous sources of data constantly emerge. A conventional search engine cannot crawl and index at the same pace as the expansion of the Internet. Moreover, a large portion of the data on the Internet is not accessible to traditional search engines. Distributed Information Retrieval (DIR) is a viable solution to this as it integrates multiple shards (resources) and provides a unified access to them. Resource selection is a key component of DIR systems. There is a rich body of literature on resource selection approaches for DIR. A key limitation of the existing approaches is that they primarily use term-based statistical features and do not generally model resource-query and resource-resource relationships. In this paper, we propose a graph neural network (GNN) based approach to learning-to-rank that is capable of modeling resource-query and resource-resource relationships. Specifically, we utilize a pre-trained language model (PTLM) to obtain semantic information from queries and resources. Then, we explicitly build a heterogeneous graph to preserve structural information of query-resource relationships and employ GNN to extract structural information. In addition, the heterogeneous graph is enriched with resource-resource type of edges to further enhance the ranking accuracy. Extensive experiments on benchmark datasets show that our proposed approach is highly effective in resource selection. Our method outperforms the state-of-the-art by 6.4% to 42% on various performance metrics.
Boosting Entity Mention Detection for Targetted Twitter Streams with Global Contextual Embeddings
Jan 28, 2022
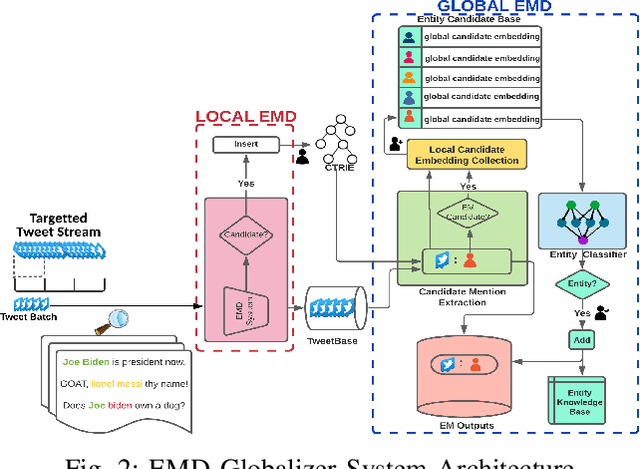
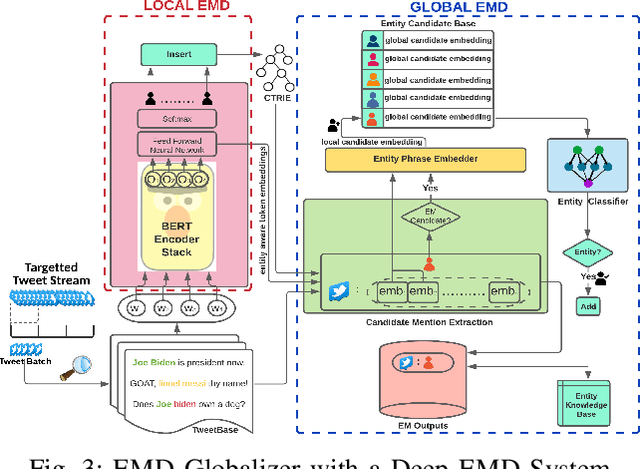
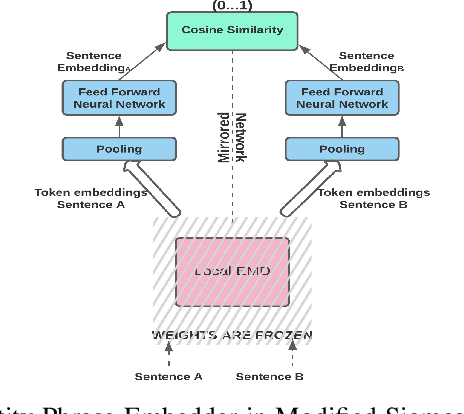
Microblogging sites, like Twitter, have emerged as ubiquitous sources of information. Two important tasks related to the automatic extraction and analysis of information in Microblogs are Entity Mention Detection (EMD) and Entity Detection (ED). The state-of-the-art EMD systems aim to model the non-literary nature of microblog text by training upon offline static datasets. They extract a combination of surface-level features -- orthographic, lexical, and semantic -- from individual messages for noisy text modeling and entity extraction. But given the constantly evolving nature of microblog streams, detecting all entity mentions from such varying yet limited context of short messages remains a difficult problem. To this end, we propose a framework named EMD Globalizer, better suited for the execution of EMD learners on microblog streams. It deviates from the processing of isolated microblog messages by existing EMD systems, where learned knowledge from the immediate context of a message is used to suggest entities. After an initial extraction of entity candidates by an EMD system, the proposed framework leverages occurrence mining to find additional candidate mentions that are missed during this first detection. Aggregating the local contextual representations of these mentions, a global embedding is drawn from the collective context of an entity candidate within a stream. The global embeddings are then utilized to separate entities within the candidates from false positives. All mentions of said entities from the stream are produced in the framework's final outputs. Our experiments show that EMD Globalizer can enhance the effectiveness of all existing EMD systems that we tested (on average by 25.61%) with a small additional computational overhead.