 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Dictionary based Data Representation
Dec 11, 2015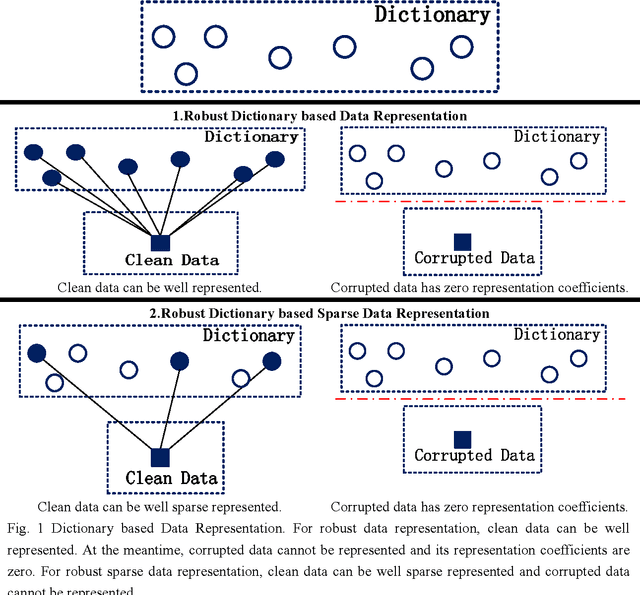
The robustness to noise and outliers is an important issue in linear representation in real applications. We focus on the problem that samples are grossly corrupted, which is also the 'sample specific' corruptions problem. A reasonable assumption is that corrupted samples cannot be represented by the dictionary while clean samples can be well represented. This assumption is enforced in this paper by investigating the coefficients of corrupted samples. Concretely, we require the coefficients of corrupted samples be zero. In this way, the representation quality of clean data can be assured without the effect of corrupted data. At last, a robust dictionary based data representation approach and its sparse representation version are proposed, which have directive significance for future applications.
Agglomerative clustering and collectiveness measure via exponent generating function
Aug 07, 2015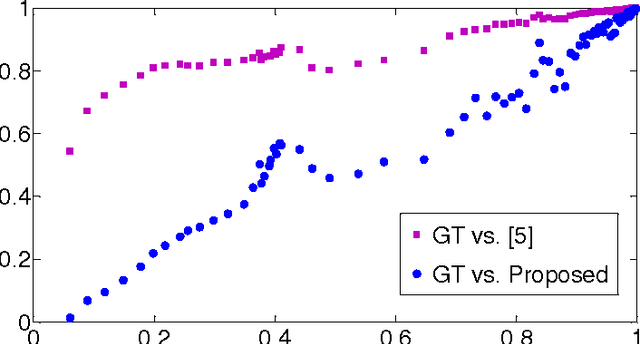
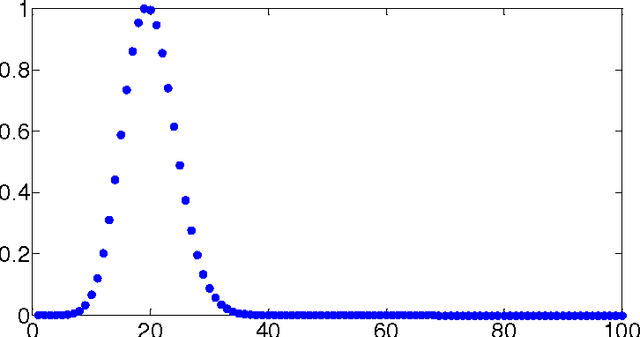
The key in agglomerative clustering is to define the affinity measure between two sets. A novel agglomerative clustering method is proposed by utilizing the path integral to define the affinity measure. Firstly, the path integral descriptor of an edge, a node and a set is computed by path integral and exponent generating function. Then, the affinity measure between two sets is obtained by path integral descriptor of sets. Several good properties of the path integral descriptor is proposed in this paper. In addition, we give the physical interpretation of the proposed path integral descriptor of a set. The proposed path integral descriptor of a set can be regard as the collectiveness measure of a set, which can be a moving system such as human crowd, sheep herd and so on. Self-driven particle (SDP) model is used to test the ability of the proposed method in measuring collectiveness.