 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting the Effectiveness of Self-Training: Application to Sentiment Classification
Jan 13, 2016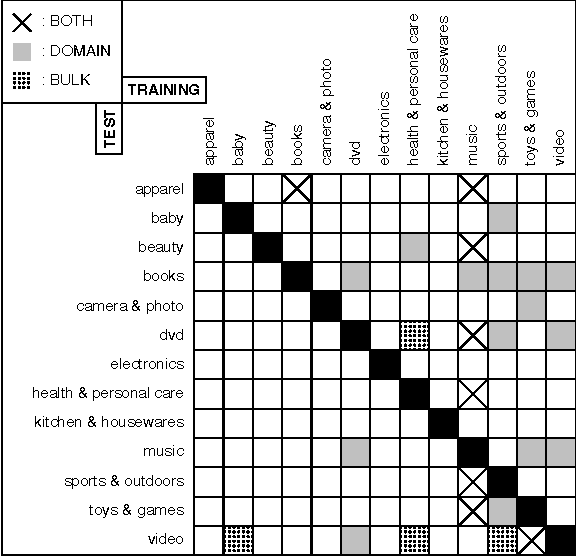
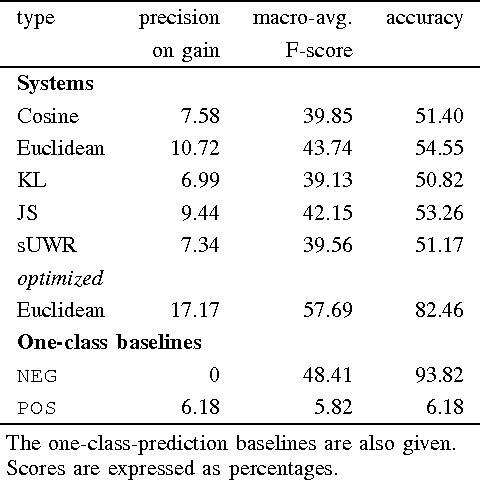
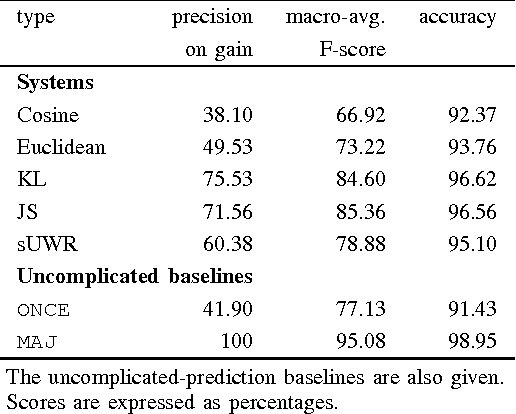
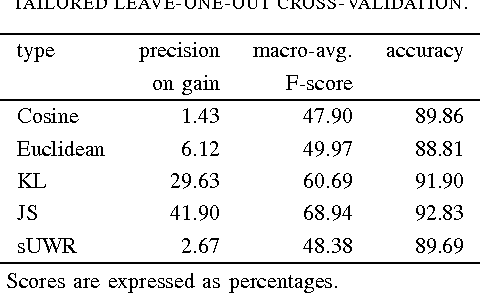
The goal of this paper is to investigate the connection between the performance gain that can be obtained by selftraining and the similarity between the corpora used in this approach. Self-training is a semi-supervised technique designed to increase the performance of machine learning algorithms by automatically classifying instances of a task and adding these as additional training material to the same classifier. In the context of language processing tasks, this training material is mostly an (annotated) corpus. Unfortunately self-training does not always lead to a performance increase and whether it will is largely unpredictable. We show that the similarity between corpora can be used to identify those setups for which self-training can be beneficial. We consider this research as a step in the process of developing a classifier that is able to adapt itself to each new test corpus that it is presented with.
The Effects of Age, Gender and Region on Non-standard Linguistic Variation in Online Social Networks
Jan 11, 2016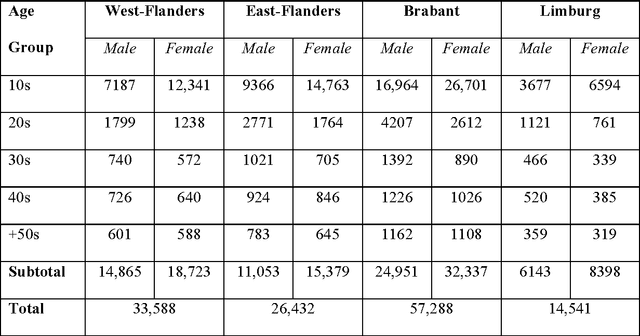
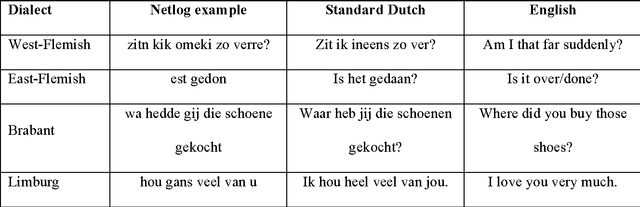
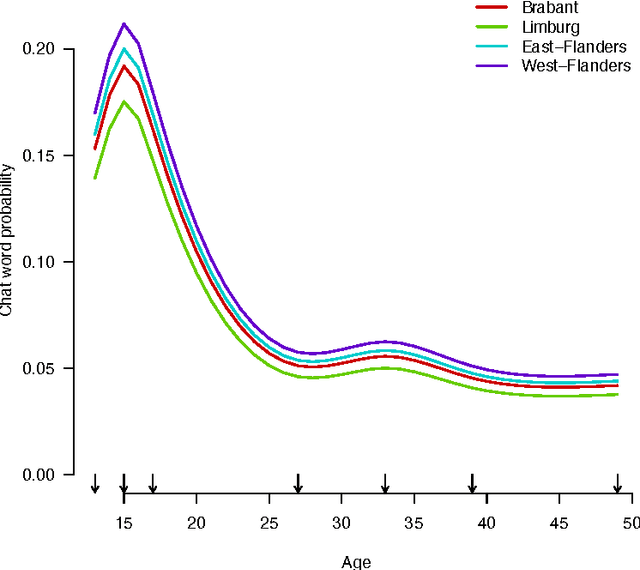
We present a corpus-based analysis of the effects of age, gender and region of origin on the production of both "netspeak" or "chatspeak" features and regional speech features in Flemish Dutch posts that were collected from a Belgian online social network platform. The present study shows that combining quantitative and qualitative approaches is essential for understanding non-standard linguistic variation in a CMC corpus. It also presents a methodology that enables the systematic study of this variation by including all non-standard words in the corpus. The analyses resulted in a convincing illustration of the Adolescent Peak Principle. In addition, our approach revealed an intriguing correlation between the use of regional speech features and chatspeak features.
Meta-Learning for Phonemic Annotation of Corpora
Aug 18, 2000
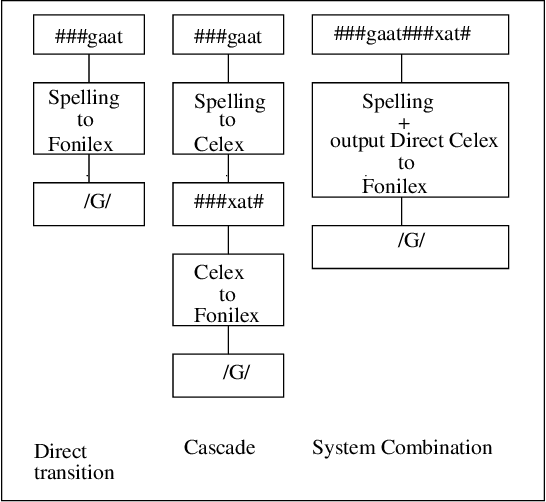

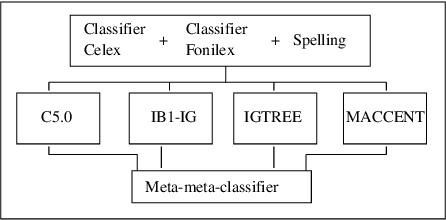
We apply rule induction, classifier combination and meta-learning (stacked classifiers) to the problem of bootstrapping high accuracy automatic annotation of corpora with pronunciation information. The task we address in this paper consists of generating phonemic representations reflecting the Flemish and Dutch pronunciations of a word on the basis of its orthographic representation (which in turn is based on the actual speech recordings). We compare several possible approaches to achieve the text-to-pronunciation mapping task: memory-based learning, transformation-based learning, rule induction, maximum entropy modeling, combination of classifiers in stacked learning, and stacking of meta-learners. We are interested both in optimal accuracy and in obtaining insight into the linguistic regularities involved. As far as accuracy is concerned, an already high accuracy level (93% for Celex and 86% for Fonilex at word level) for single classifiers is boosted significantly with additional error reductions of 31% and 38% respectively using combination of classifiers, and a further 5% using combination of meta-learners, bringing overall word level accuracy to 96% for the Dutch variant and 92% for the Flemish variant. We also show that the application of machine learning methods indeed leads to increased insight into the linguistic regularities determining the variation between the two pronunciation variants studied.
* 8 pages
Applying System Combination to Base Noun Phrase Identification
Aug 17, 2000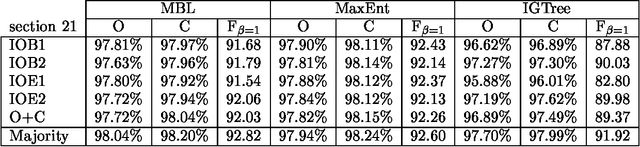
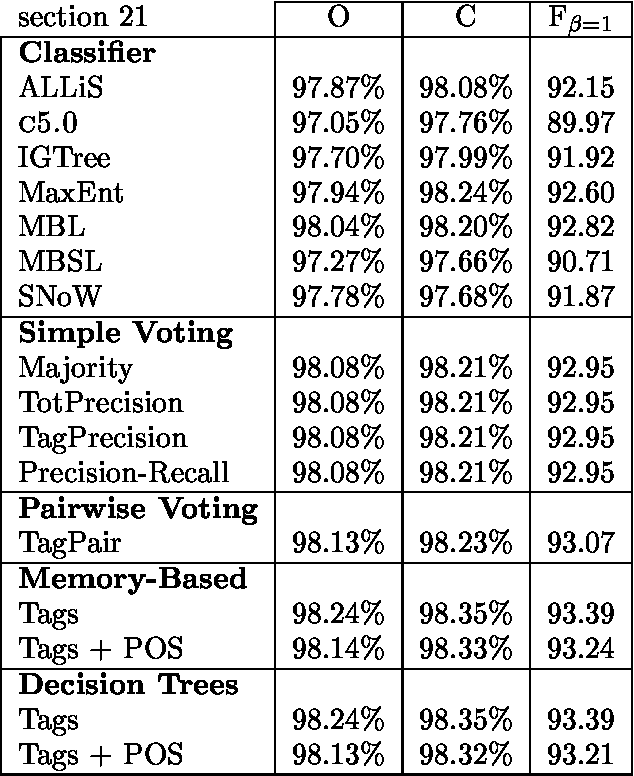

We use seven machine learning algorithms for one task: identifying base noun phrases. The results have been processed by different system combination methods and all of these outperformed the best individual result. We have applied the seven learners with the best combinator, a majority vote of the top five systems, to a standard data set and managed to improve the best published result for this data set.
* 7 pages
Bootstrapping a Tagged Corpus through Combination of Existing Heterogeneous Taggers
Jul 13, 2000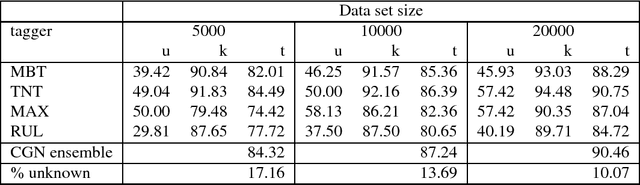
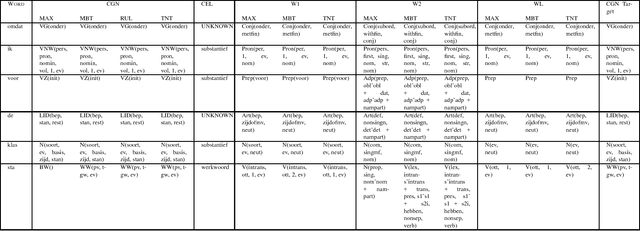
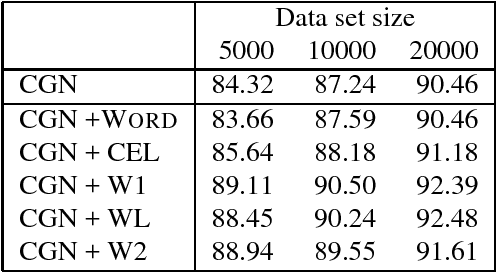
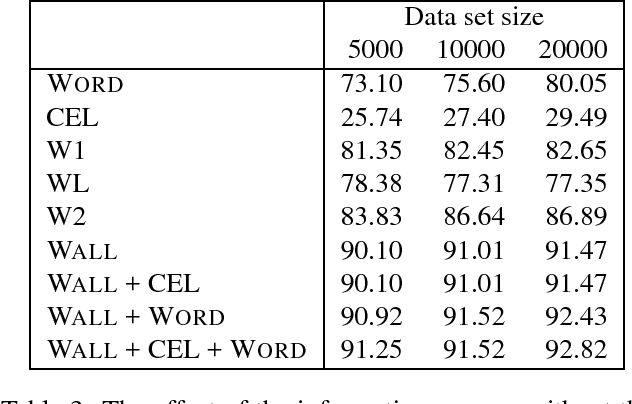
This paper describes a new method, Combi-bootstrap, to exploit existing taggers and lexical resources for the annotation of corpora with new tagsets. Combi-bootstrap uses existing resources as features for a second level machine learning module, that is trained to make the mapping to the new tagset on a very small sample of annotated corpus material. Experiments show that Combi-bootstrap: i) can integrate a wide variety of existing resources, and ii) achieves much higher accuracy (up to 44.7 % error reduction) than both the best single tagger and an ensemble tagger constructed out of the same small training sample.
* 4 pages
Memory-Based Shallow Parsing
Jun 02, 1999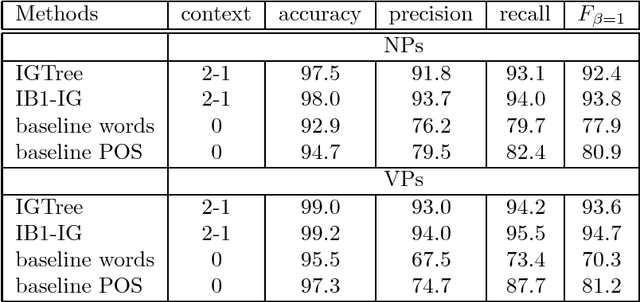

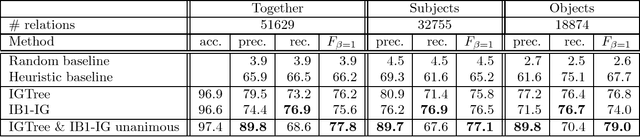
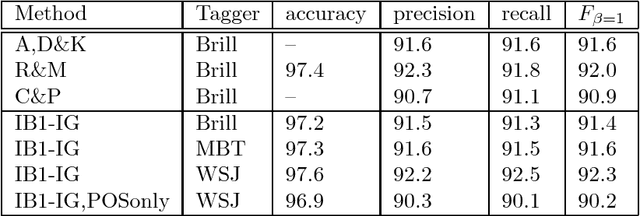
We present a memory-based learning (MBL) approach to shallow parsing in which POS tagging, chunking, and identification of syntactic relations are formulated as memory-based modules. The experiments reported in this paper show competitive results, the F-value for the Wall Street Journal (WSJ) treebank is: 93.8% for NP chunking, 94.7% for VP chunking, 77.1% for subject detection and 79.0% for object detection.
Cascaded Grammatical Relation Assignment
Jun 02, 1999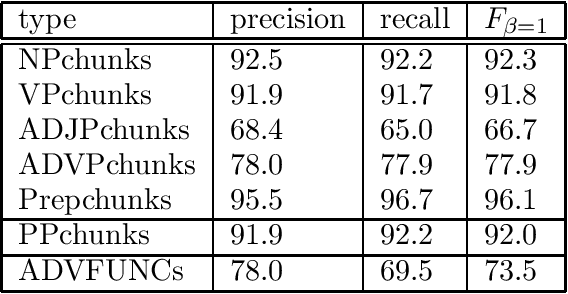


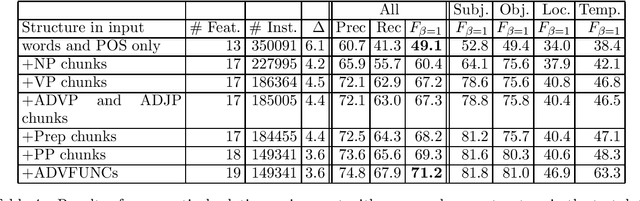
In this paper we discuss cascaded Memory-Based grammatical relations assignment. In the first stages of the cascade, we find chunks of several types (NP,VP,ADJP,ADVP,PP) and label them with their adverbial function (e.g. local, temporal). In the last stage, we assign grammatical relations to pairs of chunks. We studied the effect of adding several levels to this cascaded classifier and we found that even the less performing chunkers enhanced the performance of the relation finder.
Forgetting Exceptions is Harmful in Language Learning
Dec 22, 1998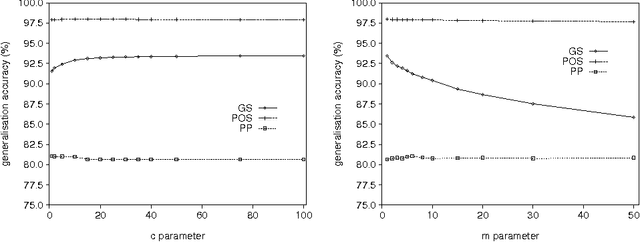
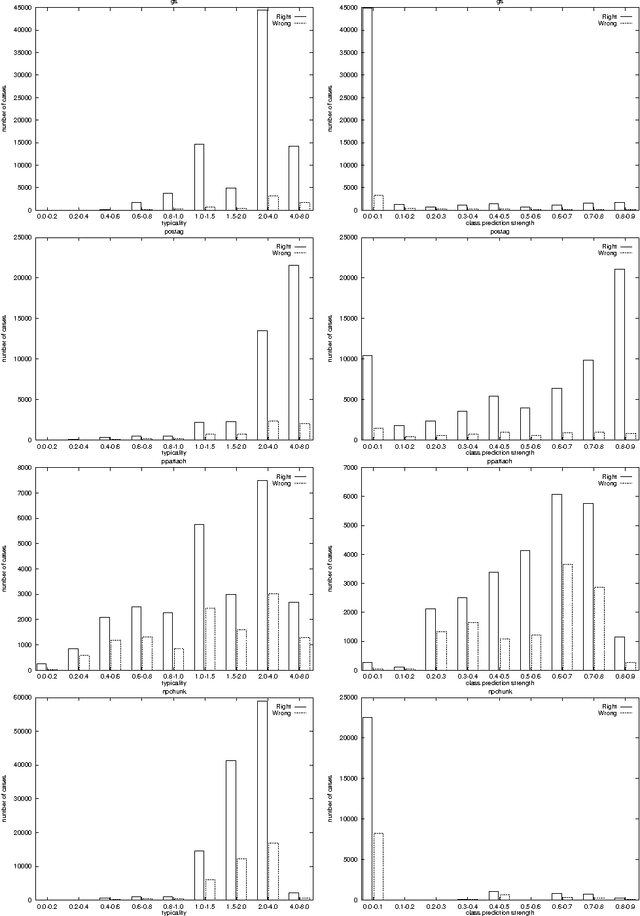
We show that in language learning, contrary to received wisdom, keeping exceptional training instances in memory can be beneficial for generalization accuracy. We investigate this phenomenon empirically on a selection of benchmark natural language processing tasks: grapheme-to-phoneme conversion, part-of-speech tagging, prepositional-phrase attachment, and base noun phrase chunking. In a first series of experiments we combine memory-based learning with training set editing techniques, in which instances are edited based on their typicality and class prediction strength. Results show that editing exceptional instances (with low typicality or low class prediction strength) tends to harm generalization accuracy. In a second series of experiments we compare memory-based learning and decision-tree learning methods on the same selection of tasks, and find that decision-tree learning often performs worse than memory-based learning. Moreover, the decrease in performance can be linked to the degree of abstraction from exceptions (i.e., pruning or eagerness). We provide explanations for both results in terms of the properties of the natural language processing tasks and the learning algorithms.
Improving Data Driven Wordclass Tagging by System Combination
Jul 31, 1998
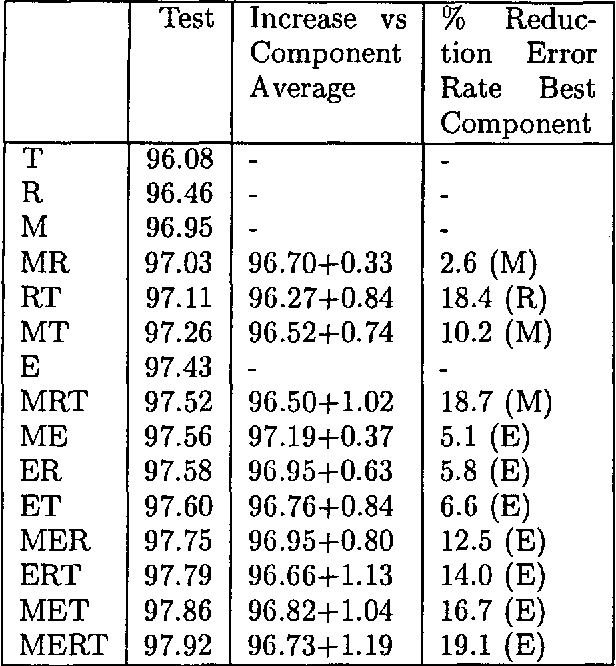
In this paper we examine how the differences in modelling between different data driven systems performing the same NLP task can be exploited to yield a higher accuracy than the best individual system. We do this by means of an experiment involving the task of morpho-syntactic wordclass tagging. Four well-known tagger generators (Hidden Markov Model, Memory-Based, Transformation Rules and Maximum Entropy) are trained on the same corpus data. After comparison, their outputs are combined using several voting strategies and second stage classifiers. All combination taggers outperform their best component, with the best combination showing a 19.1% lower error rate than the best individual tagger.
* 7 pages, LaTeX, uses acl.bst, colacl.sty
Modularity in inductively-learned word pronunciation systems
Jan 26, 1998In leading morpho-phonological theories and state-of-the-art text-to-speech systems it is assumed that word pronunciation cannot be learned or performed without in-between analyses at several abstraction levels (e.g., morphological, graphemic, phonemic, syllabic, and stress levels). We challenge this assumption for the case of English word pronunciation. Using IGTree, an inductive-learning decision-tree algorithms, we train and test three word-pronunciation systems in which the number of abstraction levels (implemented as sequenced modules) is reduced from five, via three, to one. The latter system, classifying letter strings directly as mapping to phonemes with stress markers, yields significantly better generalisation accuracies than the two multi-module systems. Analyses of empirical results indicate that positive utility effects of sequencing modules are outweighed by cascading errors passed on between modules.
* 10 pages, uses nemlap3.sty and epsf and ipamacs (WSU IPA) macros