 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRule induction for global explanation of trained models
Aug 29, 2018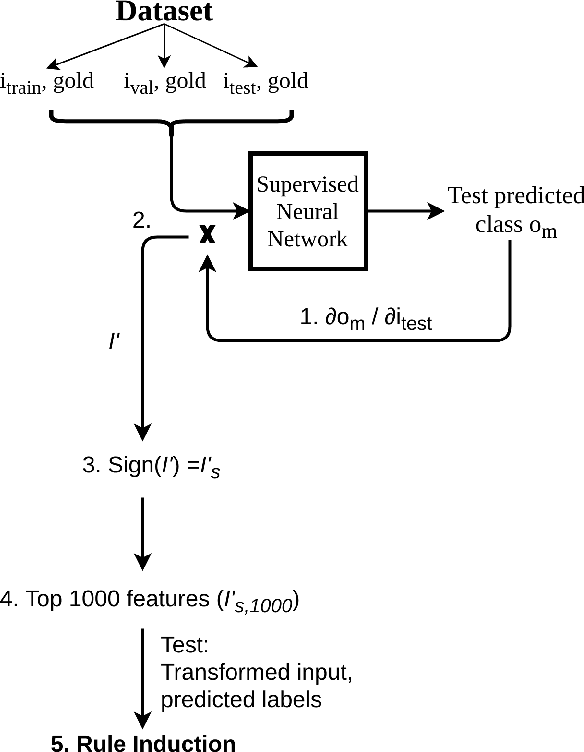
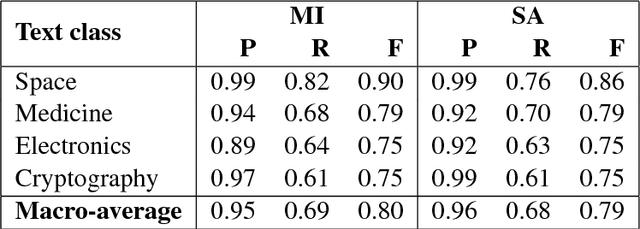
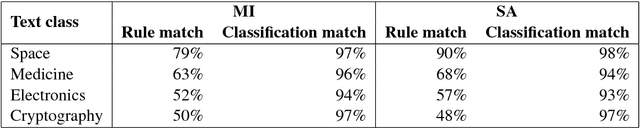
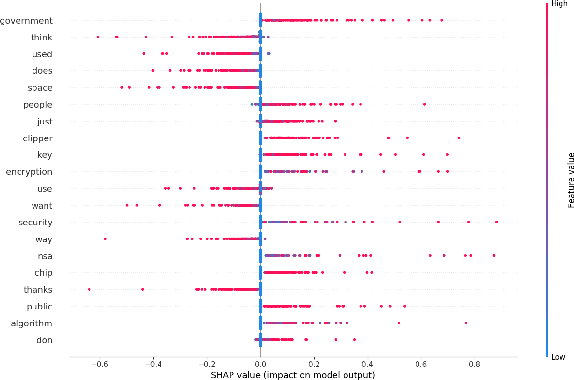
Understanding the behavior of a trained network and finding explanations for its outputs is important for improving the network's performance and generalization ability, and for ensuring trust in automated systems. Several approaches have previously been proposed to identify and visualize the most important features by analyzing a trained network. However, the relations between different features and classes are lost in most cases. We propose a technique to induce sets of if-then-else rules that capture these relations to globally explain the predictions of a network. We first calculate the importance of the features in the trained network. We then weigh the original inputs with these feature importance scores, simplify the transformed input space, and finally fit a rule induction model to explain the model predictions. We find that the output rule-sets can explain the predictions of a neural network trained for 4-class text classification from the 20 newsgroups dataset to a macro-averaged F-score of 0.80. We make the code available at https://github.com/clips/interpret_with_rules.
Patient representation learning and interpretable evaluation using clinical notes
Jul 03, 2018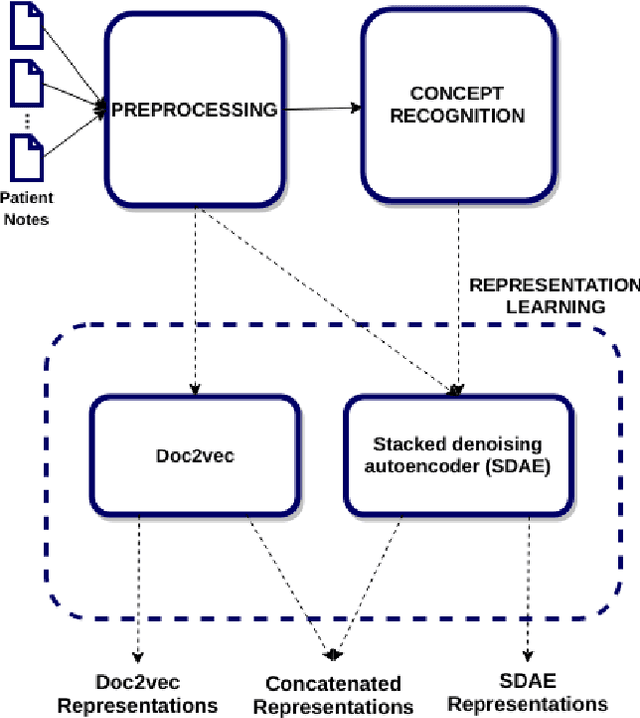
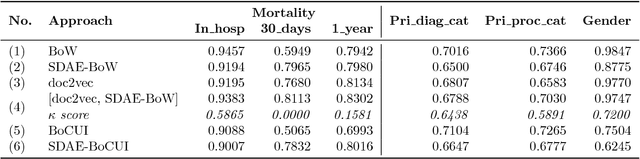
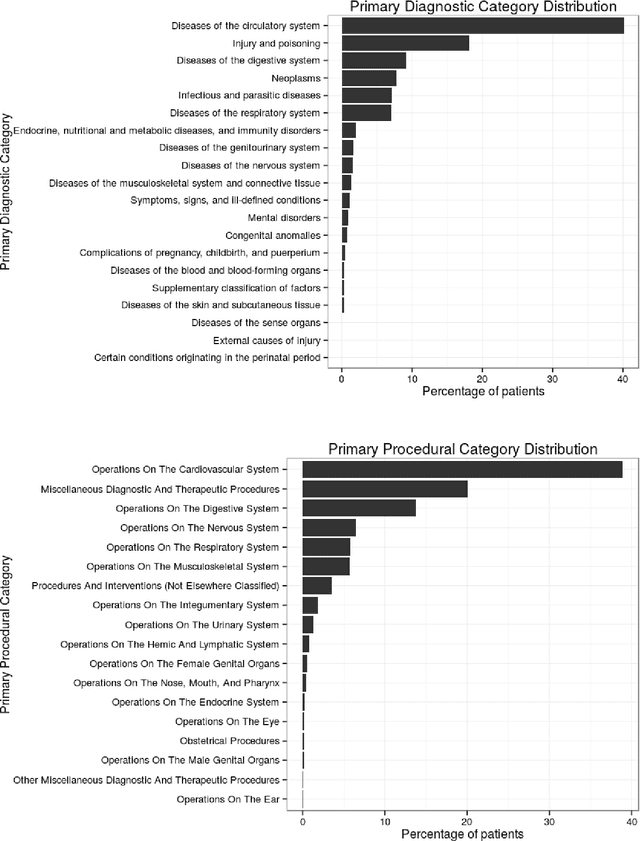
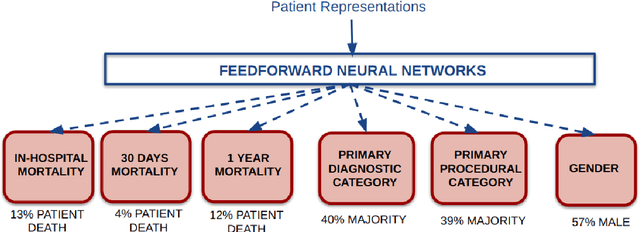
We have three contributions in this work: 1. We explore the utility of a stacked denoising autoencoder and a paragraph vector model to learn task-independent dense patient representations directly from clinical notes. To analyze if these representations are transferable across tasks, we evaluate them in multiple supervised setups to predict patient mortality, primary diagnostic and procedural category, and gender. We compare their performance with sparse representations obtained from a bag-of-words model. We observe that the learned generalized representations significantly outperform the sparse representations when we have few positive instances to learn from, and there is an absence of strong lexical features. 2. We compare the model performance of the feature set constructed from a bag of words to that obtained from medical concepts. In the latter case, concepts represent problems, treatments, and tests. We find that concept identification does not improve the classification performance. 3. We propose novel techniques to facilitate model interpretability. To understand and interpret the representations, we explore the best encoded features within the patient representations obtained from the autoencoder model. Further, we calculate feature sensitivity across two networks to identify the most significant input features for different classification tasks when we use these pretrained representations as the supervised input. We successfully extract the most influential features for the pipeline using this technique.
* Accepted manuscript at Journal of Biomedical Informatics
CliCR: A Dataset of Clinical Case Reports for Machine Reading Comprehension
Mar 26, 2018
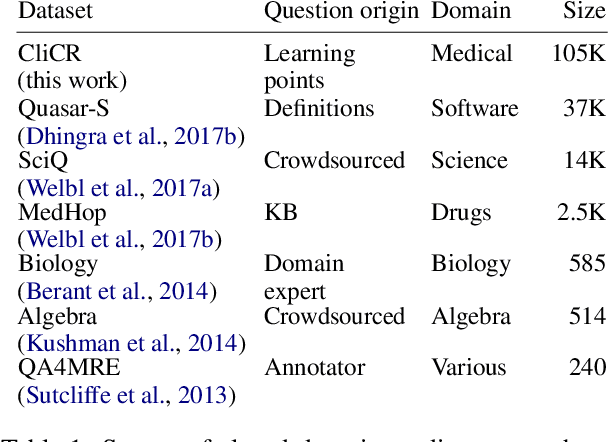

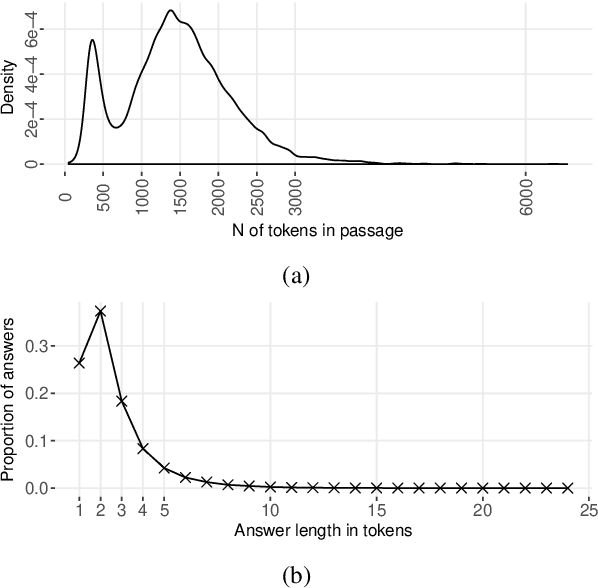
We present a new dataset for machine comprehension in the medical domain. Our dataset uses clinical case reports with around 100,000 gap-filling queries about these cases. We apply several baselines and state-of-the-art neural readers to the dataset, and observe a considerable gap in performance (20% F1) between the best human and machine readers. We analyze the skills required for successful answering and show how reader performance varies depending on the applicable skills. We find that inferences using domain knowledge and object tracking are the most frequently required skills, and that recognizing omitted information and spatio-temporal reasoning are the most difficult for the machines.
Automatic Detection of Cyberbullying in Social Media Text
Jan 17, 2018



While social media offer great communication opportunities, they also increase the vulnerability of young people to threatening situations online. Recent studies report that cyberbullying constitutes a growing problem among youngsters. Successful prevention depends on the adequate detection of potentially harmful messages and the information overload on the Web requires intelligent systems to identify potential risks automatically. The focus of this paper is on automatic cyberbullying detection in social media text by modelling posts written by bullies, victims, and bystanders of online bullying. We describe the collection and fine-grained annotation of a training corpus for English and Dutch and perform a series of binary classification experiments to determine the feasibility of automatic cyberbullying detection. We make use of linear support vector machines exploiting a rich feature set and investigate which information sources contribute the most for this particular task. Experiments on a holdout test set reveal promising results for the detection of cyberbullying-related posts. After optimisation of the hyperparameters, the classifier yields an F1-score of 64% and 61% for English and Dutch respectively, and considerably outperforms baseline systems based on keywords and word unigrams.
Unsupervised patient representations from clinical notes with interpretable classification decisions
Nov 14, 2017

We have two main contributions in this work: 1. We explore the usage of a stacked denoising autoencoder, and a paragraph vector model to learn task-independent dense patient representations directly from clinical notes. We evaluate these representations by using them as features in multiple supervised setups, and compare their performance with those of sparse representations. 2. To understand and interpret the representations, we explore the best encoded features within the patient representations obtained from the autoencoder model. Further, we calculate the significance of the input features of the trained classifiers when we use these pretrained representations as input.
Unsupervised Context-Sensitive Spelling Correction of English and Dutch Clinical Free-Text with Word and Character N-Gram Embeddings
Oct 19, 2017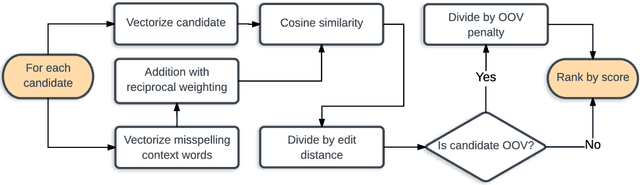

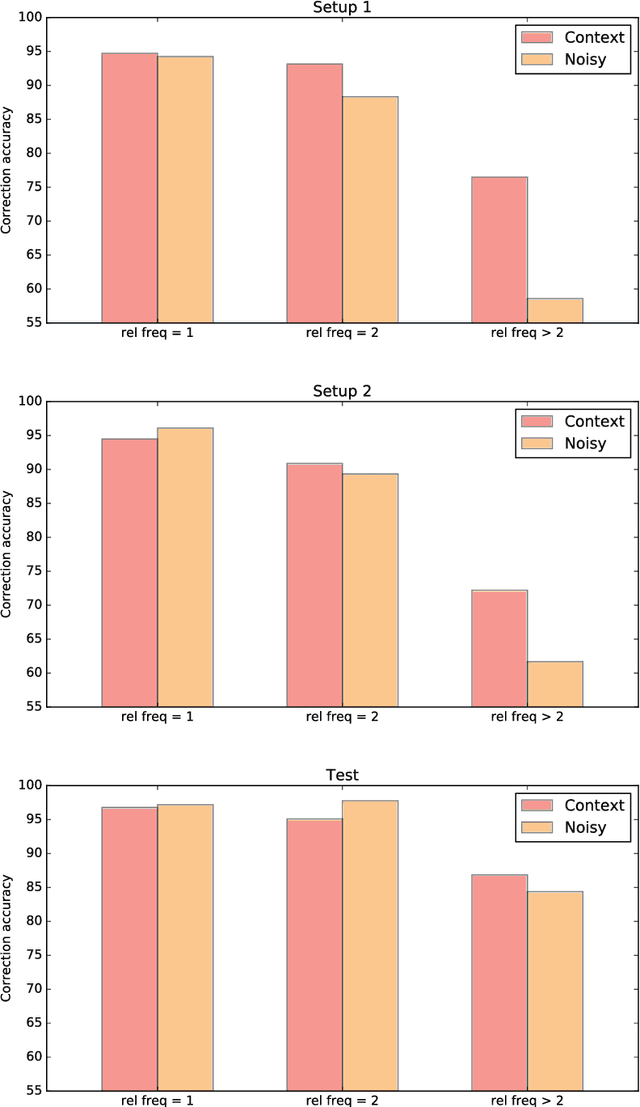
We present an unsupervised context-sensitive spelling correction method for clinical free-text that uses word and character n-gram embeddings. Our method generates misspelling replacement candidates and ranks them according to their semantic fit, by calculating a weighted cosine similarity between the vectorized representation of a candidate and the misspelling context. To tune the parameters of this model, we generate self-induced spelling error corpora. We perform our experiments for two languages. For English, we greatly outperform off-the-shelf spelling correction tools on a manually annotated MIMIC-III test set, and counter the frequency bias of a noisy channel model, showing that neural embeddings can be successfully exploited to improve upon the state-of-the-art. For Dutch, we also outperform an off-the-shelf spelling correction tool on manually annotated clinical records from the Antwerp University Hospital, but can offer no empirical evidence that our method counters the frequency bias of a noisy channel model in this case as well. However, both our context-sensitive model and our implementation of the noisy channel model obtain high scores on the test set, establishing a state-of-the-art for Dutch clinical spelling correction with the noisy channel model.
* Appears in volume 7 of the CLIN Journal, http://www.clinjournal.org/biblio/volume
A Short Review of Ethical Challenges in Clinical Natural Language Processing
Mar 29, 2017Clinical NLP has an immense potential in contributing to how clinical practice will be revolutionized by the advent of large scale processing of clinical records. However, this potential has remained largely untapped due to slow progress primarily caused by strict data access policies for researchers. In this paper, we discuss the concern for privacy and the measures it entails. We also suggest sources of less sensitive data. Finally, we draw attention to biases that can compromise the validity of empirical research and lead to socially harmful applications.
A Dictionary-based Approach to Racism Detection in Dutch Social Media
Aug 31, 2016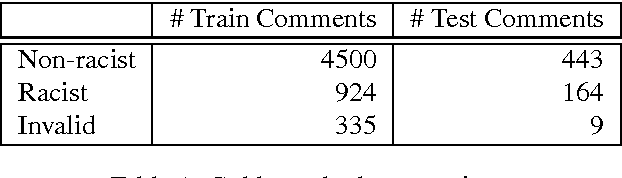

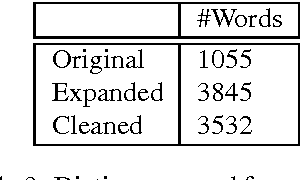

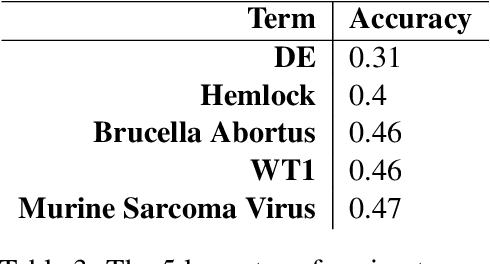
We present a dictionary-based approach to racism detection in Dutch social media comments, which were retrieved from two public Belgian social media sites likely to attract racist reactions. These comments were labeled as racist or non-racist by multiple annotators. For our approach, three discourse dictionaries were created: first, we created a dictionary by retrieving possibly racist and more neutral terms from the training data, and then augmenting these with more general words to remove some bias. A second dictionary was created through automatic expansion using a \texttt{word2vec} model trained on a large corpus of general Dutch text. Finally, a third dictionary was created by manually filtering out incorrect expansions. We trained multiple Support Vector Machines, using the distribution of words over the different categories in the dictionaries as features. The best-performing model used the manually cleaned dictionary and obtained an F-score of 0.46 for the racist class on a test set consisting of unseen Dutch comments, retrieved from the same sites used for the training set. The automated expansion of the dictionary only slightly boosted the model's performance, and this increase in performance was not statistically significant. The fact that the coverage of the expanded dictionaries did increase indicates that the words that were automatically added did occur in the corpus, but were not able to meaningfully impact performance. The dictionaries, code, and the procedure for requesting the corpus are available at: https://github.com/clips/hades
Using Distributed Representations to Disambiguate Biomedical and Clinical Concepts
Aug 19, 2016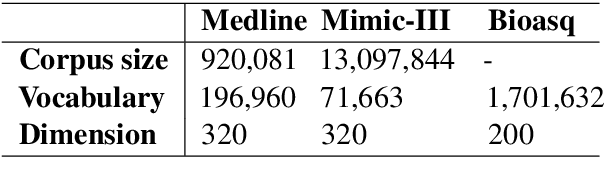

In this paper, we report a knowledge-based method for Word Sense Disambiguation in the domains of biomedical and clinical text. We combine word representations created on large corpora with a small number of definitions from the UMLS to create concept representations, which we then compare to representations of the context of ambiguous terms. Using no relational information, we obtain comparable performance to previous approaches on the MSH-WSD dataset, which is a well-known dataset in the biomedical domain. Additionally, our method is fast and easy to set up and extend to other domains. Supplementary materials, including source code, can be found at https: //github.com/clips/yarn
* 6 pages, 1 figure, presented at the 15th Workshop on Biomedical Natural Language Processing, Berlin 2016
Evaluating Unsupervised Dutch Word Embeddings as a Linguistic Resource
Jul 01, 2016
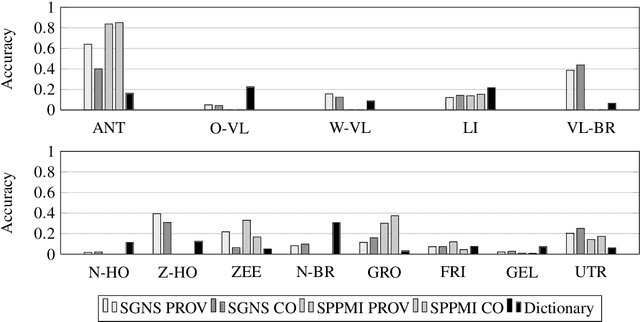
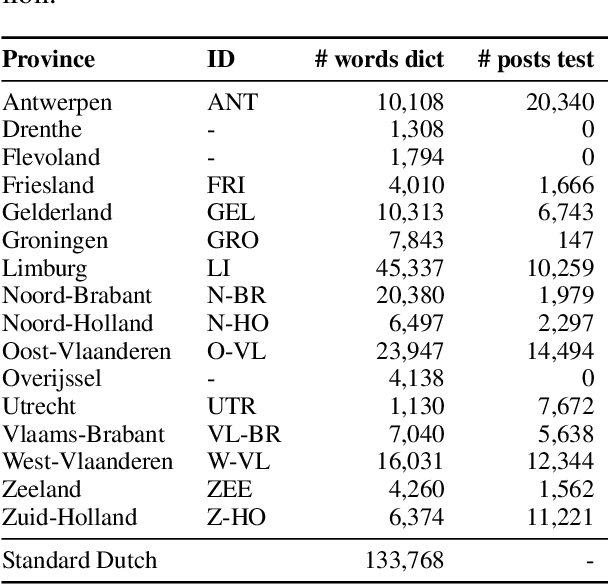
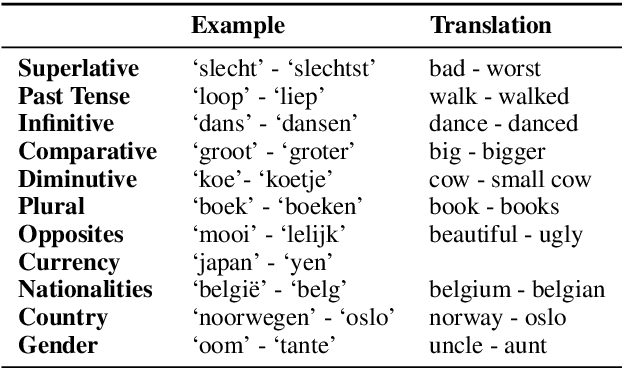
Word embeddings have recently seen a strong increase in interest as a result of strong performance gains on a variety of tasks. However, most of this research also underlined the importance of benchmark datasets, and the difficulty of constructing these for a variety of language-specific tasks. Still, many of the datasets used in these tasks could prove to be fruitful linguistic resources, allowing for unique observations into language use and variability. In this paper we demonstrate the performance of multiple types of embeddings, created with both count and prediction-based architectures on a variety of corpora, in two language-specific tasks: relation evaluation, and dialect identification. For the latter, we compare unsupervised methods with a traditional, hand-crafted dictionary. With this research, we provide the embeddings themselves, the relation evaluation task benchmark for use in further research, and demonstrate how the benchmarked embeddings prove a useful unsupervised linguistic resource, effectively used in a downstream task.