 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Reliable Synthetic Clinical Trial Data: The Role of Hyperparameter Optimization and Domain Constraints
May 08, 2025



The generation of synthetic clinical trial data offers a promising approach to mitigating privacy concerns and data accessibility limitations in medical research. However, ensuring that synthetic datasets maintain high fidelity, utility, and adherence to domain-specific constraints remains a key challenge. While hyperparameter optimization (HPO) has been shown to improve generative model performance, the effectiveness of different optimization strategies for synthetic clinical data remains unclear. This study systematically evaluates four HPO strategies across eight generative models, comparing single-metric optimization against compound metric optimization approaches. Our results demonstrate that HPO consistently improves synthetic data quality, with TVAE, CTGAN, and CTAB-GAN+ achieving improvements of up to 60%, 39%, and 38%, respectively. Compound metric optimization outperformed single-metric strategies, producing more balanced and generalizable synthetic datasets. Interestingly, HPO alone is insufficient to ensure clinically valid synthetic data, as all models exhibited violations of fundamental survival constraints. Preprocessing and postprocessing played a crucial role in reducing these violations, as models lacking robust processing steps produced invalid data in up to 61% of cases. These findings underscore the necessity of integrating explicit domain knowledge alongside HPO to create high quality synthetic datasets. Our study provides actionable recommendations for improving synthetic data generation, with future research needed to refine metric selection and validate these findings on larger datasets to enhance clinical applicability.
Convex space learning improves deep-generative oversampling for tabular imbalanced classification on smaller datasets
Jun 20, 2022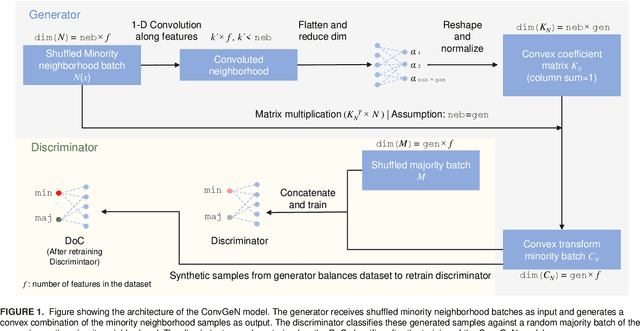
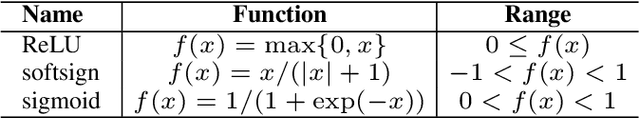
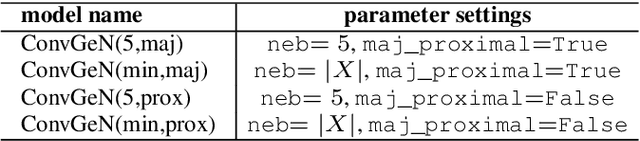
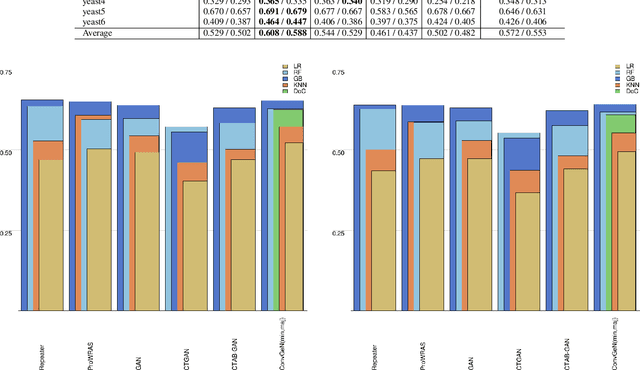
Data is commonly stored in tabular format. Several fields of research (e.g., biomedical, fault/fraud detection), are prone to small imbalanced tabular data. Supervised Machine Learning on such data is often difficult due to class imbalance, adding further to the challenge. Synthetic data generation i.e. oversampling is a common remedy used to improve classifier performance. State-of-the-art linear interpolation approaches, such as LoRAS and ProWRAS can be used to generate synthetic samples from the convex space of the minority class to improve classifier performance in such cases. Generative Adversarial Networks (GANs) are common deep learning approaches for synthetic sample generation. Although GANs are widely used for synthetic image generation, their scope on tabular data in the context of imbalanced classification is not adequately explored. In this article, we show that existing deep generative models perform poorly compared to linear interpolation approaches generating synthetic samples from the convex space of the minority class, for imbalanced classification problems on tabular datasets of small size. We propose a deep generative model, ConvGeN combining the idea of convex space learning and deep generative models. ConVGeN learns the coefficients for the convex combinations of the minority class samples, such that the synthetic data is distinct enough from the majority class. We demonstrate that our proposed model ConvGeN improves imbalanced classification on such small datasets, as compared to existing deep generative models while being at par with the existing linear interpolation approaches. Moreover, we discuss how our model can be used for synthetic tabular data generation in general, even outside the scope of data imbalance, and thus, improves the overall applicability of convex space learning.