 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQualBench: Benchmarking Chinese LLMs with Localized Professional Qualifications for Vertical Domain Evaluation
May 08, 2025



The rapid advancement of Chinese large language models (LLMs) underscores the need for domain-specific evaluations to ensure reliable applications. However, existing benchmarks often lack coverage in vertical domains and offer limited insights into the Chinese working context. Leveraging qualification exams as a unified framework for human expertise evaluation, we introduce QualBench, the first multi-domain Chinese QA benchmark dedicated to localized assessment of Chinese LLMs. The dataset includes over 17,000 questions across six vertical domains, with data selections grounded in 24 Chinese qualifications to closely align with national policies and working standards. Through comprehensive evaluation, the Qwen2.5 model outperformed the more advanced GPT-4o, with Chinese LLMs consistently surpassing non-Chinese models, highlighting the importance of localized domain knowledge in meeting qualification requirements. The best performance of 75.26% reveals the current gaps in domain coverage within model capabilities. Furthermore, we present the failure of LLM collaboration with crowdsourcing mechanisms and suggest the opportunities for multi-domain RAG knowledge enhancement and vertical domain LLM training with Federated Learning.
Dial-In LLM: Human-Aligned Dialogue Intent Clustering with LLM-in-the-loop
Dec 12, 2024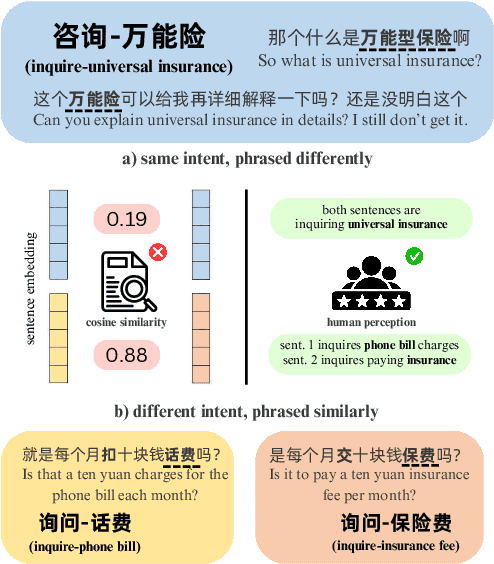
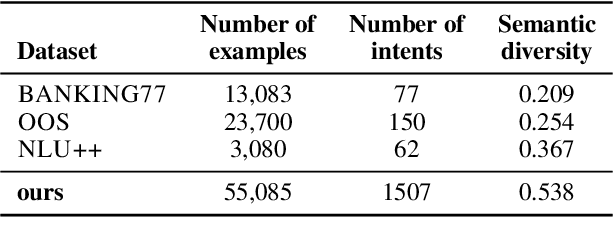
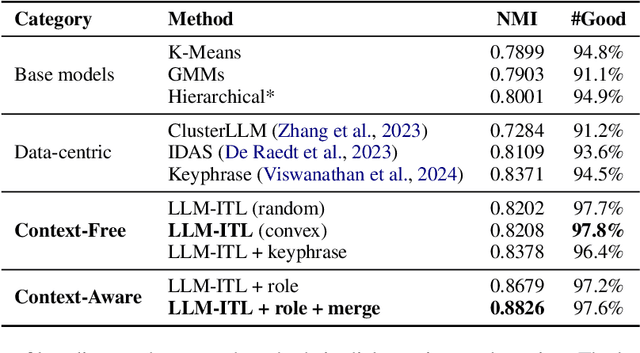
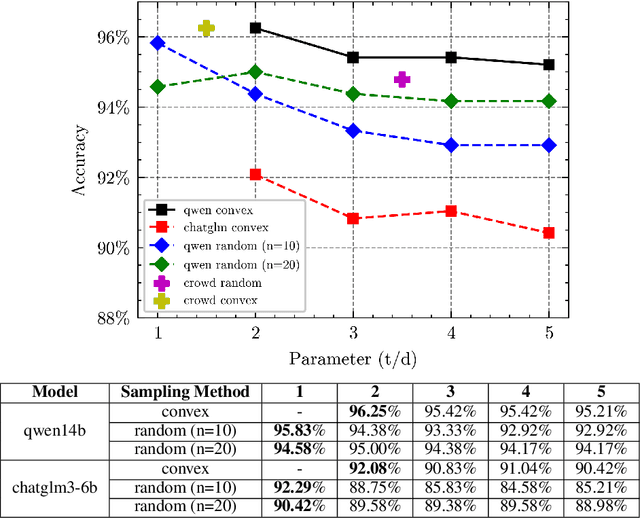
The discovery of customer intention from dialogue plays an important role in automated support system. However, traditional text clustering methods are poorly aligned with human perceptions due to the shift from embedding distance to semantic distance, and existing quantitative metrics for text clustering may not accurately reflect the true quality of intent clusters. In this paper, we leverage the superior language understanding capabilities of Large Language Models (LLMs) for designing better-calibrated intent clustering algorithms. We first establish the foundation by verifying the robustness of fine-tuned LLM utility in semantic coherence evaluation and cluster naming, resulting in an accuracy of 97.50% and 94.40%, respectively, when compared to the human-labeled ground truth. Then, we propose an iterative clustering algorithm that facilitates cluster-level refinement and the continuous discovery of high-quality intent clusters. Furthermore, we present several LLM-in-the-loop semi-supervised clustering techniques tailored for intent discovery from customer service dialogue. Experiments on a large-scale industrial dataset comprising 1,507 intent clusters demonstrate the effectiveness of the proposed techniques. The methods outperformed existing counterparts, achieving 6.25% improvement in quantitative metrics and 12% enhancement in application-level performance when constructing an intent classifier.