 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiroThinker-1.7 & H1: Towards Heavy-Duty Research Agents via Verification
Mar 16, 2026We present MiroThinker-1.7, a new research agent designed for complex long-horizon reasoning tasks. Building on this foundation, we further introduce MiroThinker-H1, which extends the agent with heavy-duty reasoning capabilities for more reliable multi-step problem solving. In particular, MiroThinker-1.7 improves the reliability of each interaction step through an agentic mid-training stage that emphasizes structured planning, contextual reasoning, and tool interaction. This enables more effective multi-step interaction and sustained reasoning across complex tasks. MiroThinker-H1 further incorporates verification directly into the reasoning process at both local and global levels. Intermediate reasoning decisions can be evaluated and refined during inference, while the overall reasoning trajectory is audited to ensure that final answers are supported by coherent chains of evidence. Across benchmarks covering open-web research, scientific reasoning, and financial analysis, MiroThinker-H1 achieves state-of-the-art performance on deep research tasks while maintaining strong results on specialized domains. We also release MiroThinker-1.7 and MiroThinker-1.7-mini as open-source models, providing competitive research-agent capabilities with significantly improved efficiency.
Brain-like Functional Organization within Large Language Models
Oct 25, 2024



The human brain has long inspired the pursuit of artificial intelligence (AI). Recently, neuroimaging studies provide compelling evidence of alignment between the computational representation of artificial neural networks (ANNs) and the neural responses of the human brain to stimuli, suggesting that ANNs may employ brain-like information processing strategies. While such alignment has been observed across sensory modalities--visual, auditory, and linguistic--much of the focus has been on the behaviors of artificial neurons (ANs) at the population level, leaving the functional organization of individual ANs that facilitates such brain-like processes largely unexplored. In this study, we bridge this gap by directly coupling sub-groups of artificial neurons with functional brain networks (FBNs), the foundational organizational structure of the human brain. Specifically, we extract representative patterns from temporal responses of ANs in large language models (LLMs), and use them as fixed regressors to construct voxel-wise encoding models to predict brain activity recorded by functional magnetic resonance imaging (fMRI). This framework links the AN sub-groups to FBNs, enabling the delineation of brain-like functional organization within LLMs. Our findings reveal that LLMs (BERT and Llama 1-3) exhibit brain-like functional architecture, with sub-groups of artificial neurons mirroring the organizational patterns of well-established FBNs. Notably, the brain-like functional organization of LLMs evolves with the increased sophistication and capability, achieving an improved balance between the diversity of computational behaviors and the consistency of functional specializations. This research represents the first exploration of brain-like functional organization within LLMs, offering novel insights to inform the development of artificial general intelligence (AGI) with human brain principles.
Machine Learning for UAV Propeller Fault Detection based on a Hybrid Data Generation Model
Feb 03, 2023



This paper describes the development of an on-board data-driven system that can monitor and localize the fault in a quadrotor unmanned aerial vehicle (UAV) and at the same time, evaluate the degree of damage of the fault under real scenarios. To achieve offline training data generation, a hybrid approach is proposed for the development of a virtual data-generative model using a combination of data-driven models as well as well-established dynamic models that describe the kinematics of the UAV. To effectively represent the drop in performance of a faulty propeller, a variation of the deep neural network, a LSTM network is proposed. With the RPM of the propeller as input and based on the fault condition of the propeller, the proposed propeller model estimates the resultant torque and thrust. Then, flight datasets of the UAV under various fault scenarios are generated via simulation using the developed data-generative model. Lastly, a fault classifier using a CNN model is proposed to identify as well as evaluate the degree of damage to the damaged propeller. The scope of this paper focuses on the identification of faulty propellers and classification of the fault level for quadrotor UAVs using RPM as well as flight data. Doing so allows for early minor fault detection to prevent serious faults from occurring if the fault is left unrepaired. To further validate the workability of this approach outside of simulation, a real-flight test is conducted indoors. The real flight data is collected and a simulation to real sim-real test is conducted. Due to the imperfections in the build of our experimental UAV, a slight calibration approach to our simulation model is further proposed and the experimental results obtained show that our trained model can identify the location of propeller fault as well as the degree/type of damage. Currently, the diagnosis accuracy on the testing set is over 80%.
GBLinks: GNN-Based Beam Selection and Link Activation for Ultra-dense D2D mmWave Networks
Jul 28, 2021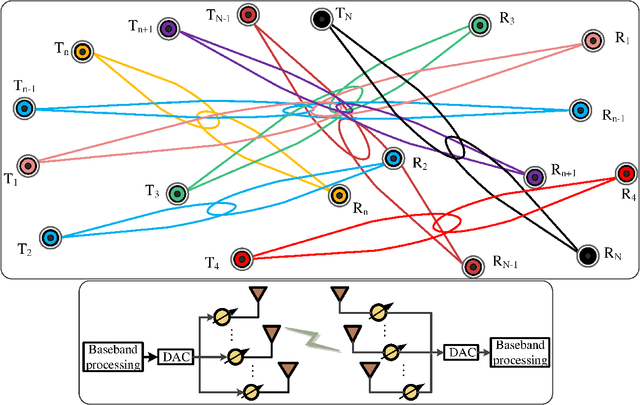
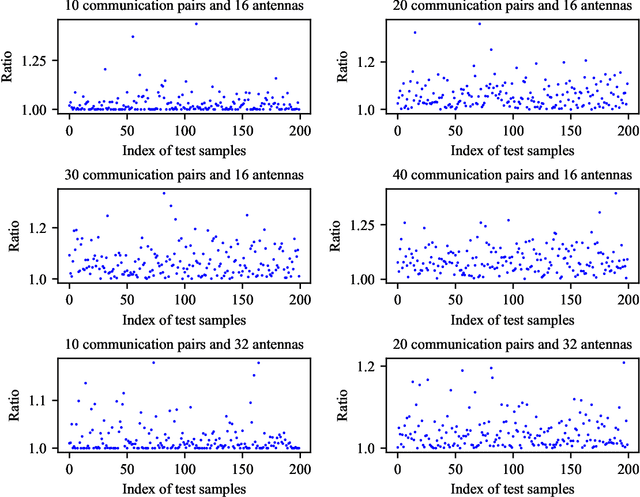
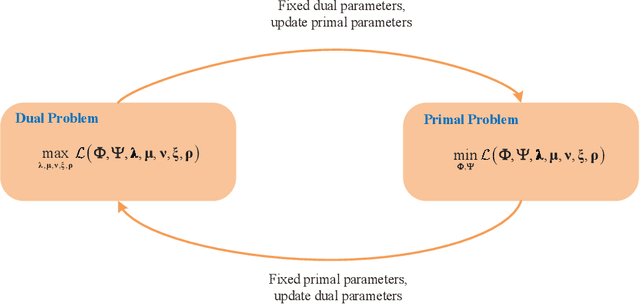
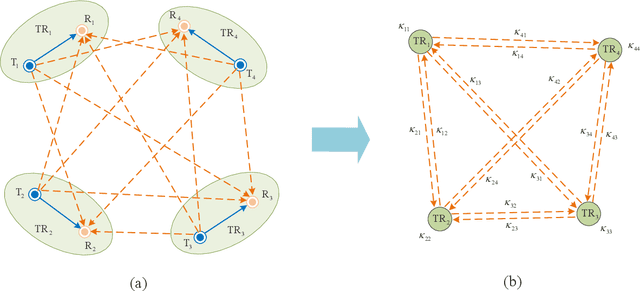
In this paper, we consider the problem of joint beam selection and link activation across a set of communication pairs to effectively control the interference between communication pairs via inactivating part communication pairs in ultra-dense device-to-device (D2D) mmWave communication networks. The resulting optimization problem is formulated as an integer programming problem that is nonconvex and NP-hard problem. Consequently, the global optimal solution, even the local optimal solution, cannot be generally obtained. To overcome this challenge, this paper resorts to design a deep learning architecture based on graph neural network to finish the joint beam selection and link activation, with taking the network topology information into account. Meanwhile, we present an unsupervised Lagrangian dual learning framework to train the parameters of GBLinks model. Numerical results show that the proposed GBLinks model can converges to a stable point with the number of iterations increases, in terms of the sum rate. Furthermore, the GBLinks model can reach near-optimal solution through comparing with the exhaustive search scheme in small-scale ultra-dense D2D mmWave communication networks and outperforms GreedyNoSched and the SCA-based method. It also shows that the GBLinks model can generalize to varying scales and densities of ultra-dense D2D mmWave communication networks.
A Multi-task Two-stream Spatiotemporal Convolutional Neural Network for Convective Storm Nowcasting
Oct 27, 2020
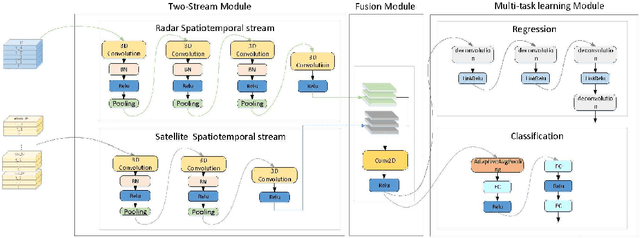
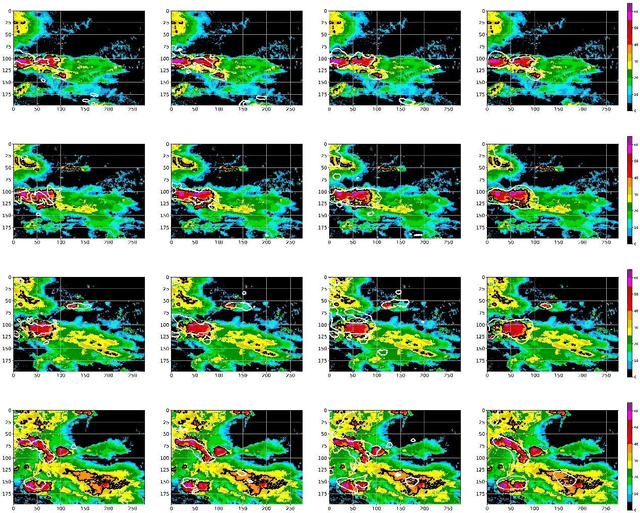
The goal of convective storm nowcasting is local prediction of severe and imminent convective storms. Here, we consider the convective storm nowcasting problem from the perspective of machine learning. First, we use a pixel-wise sampling method to construct spatiotemporal features for nowcasting, and flexibly adjust the proportions of positive and negative samples in the training set to mitigate class-imbalance issues. Second, we employ a concise two-stream convolutional neural network to extract spatial and temporal cues for nowcasting. This simplifies the network structure, reduces the training time requirement, and improves classification accuracy. The two-stream network used both radar and satellite data. In the resulting two-stream, fused convolutional neural network, some of the parameters are entered into a single-stream convolutional neural network, but it can learn the features of many data. Further, considering the relevance of classification and regression tasks, we develop a multi-task learning strategy that predicts the labels used in such tasks. We integrate two-stream multi-task learning into a single convolutional neural network. Given the compact architecture, this network is more efficient and easier to optimize than existing recurrent neural networks.
Phase Transitions and Backbones of the Asymmetric Traveling Salesman Problem
Jun 30, 2011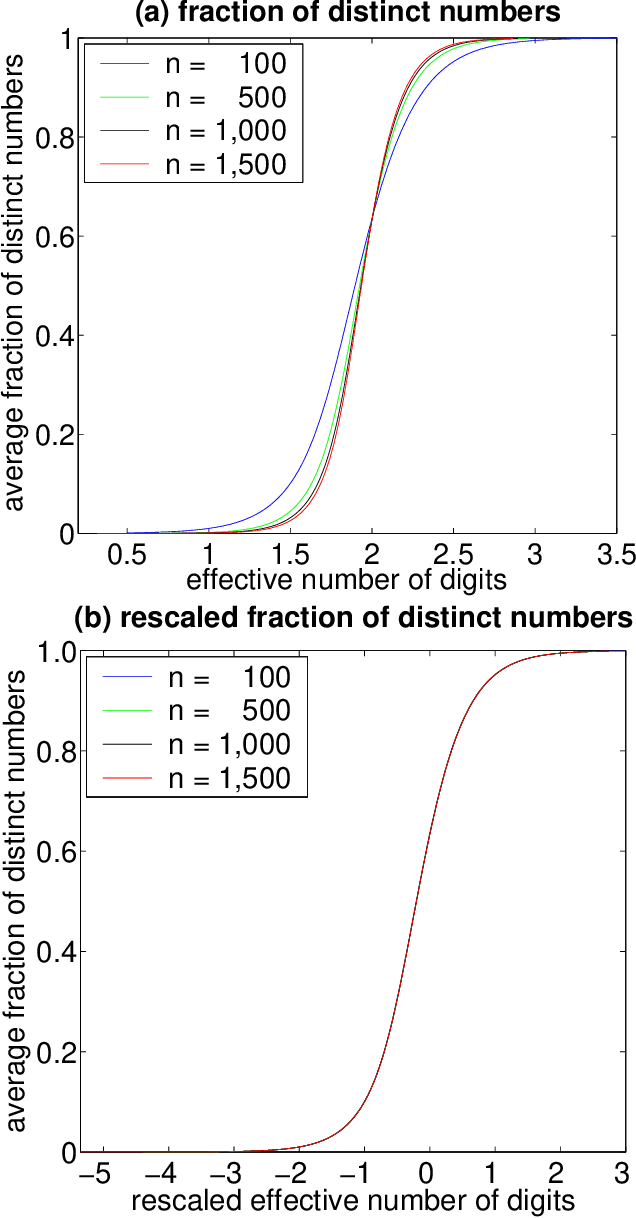
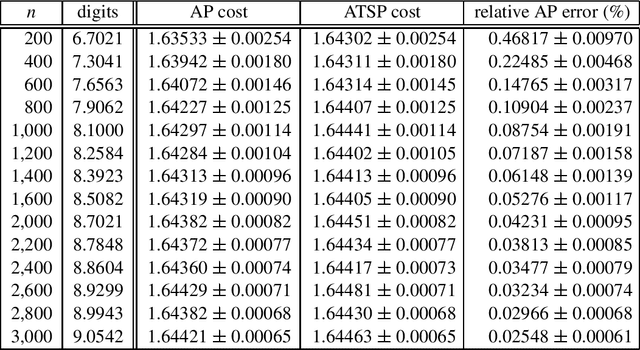
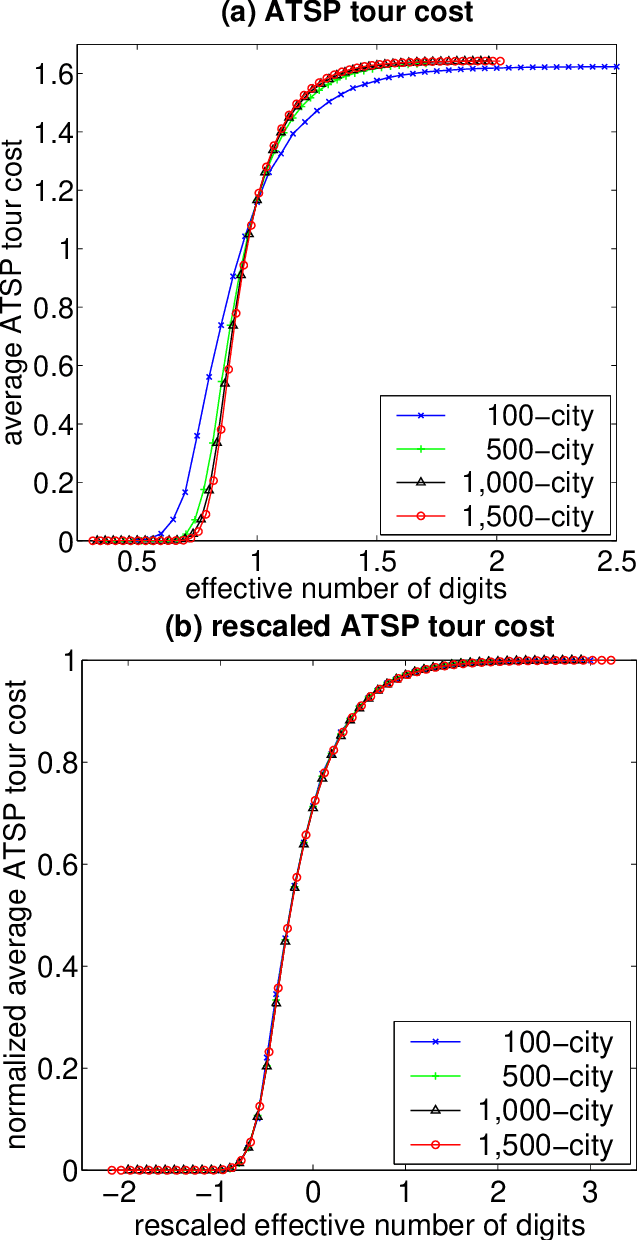
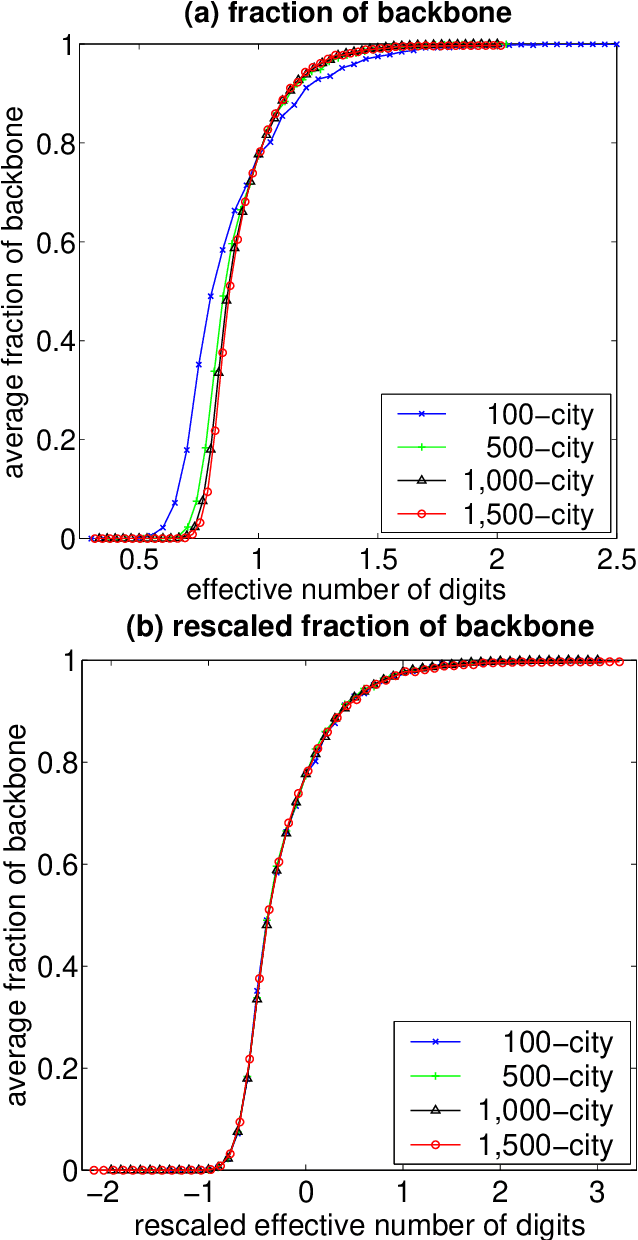
In recent years, there has been much interest in phase transitions of combinatorial problems. Phase transitions have been successfully used to analyze combinatorial optimization problems, characterize their typical-case features and locate the hardest problem instances. In this paper, we study phase transitions of the asymmetric Traveling Salesman Problem (ATSP), an NP-hard combinatorial optimization problem that has many real-world applications. Using random instances of up to 1,500 cities in which intercity distances are uniformly distributed, we empirically show that many properties of the problem, including the optimal tour cost and backbone size, experience sharp transitions as the precision of intercity distances increases across a critical value. Our experimental results on the costs of the ATSP tours and assignment problem agree with the theoretical result that the asymptotic cost of assignment problem is pi ^2 /6 the number of cities goes to infinity. In addition, we show that the average computational cost of the well-known branch-and-bound subtour elimination algorithm for the problem also exhibits a thrashing behavior, transitioning from easy to difficult as the distance precision increases. These results answer positively an open question regarding the existence of phase transitions in the ATSP, and provide guidance on how difficult ATSP problem instances should be generated.
Restricted Value Iteration: Theory and Algorithms
Jun 30, 2011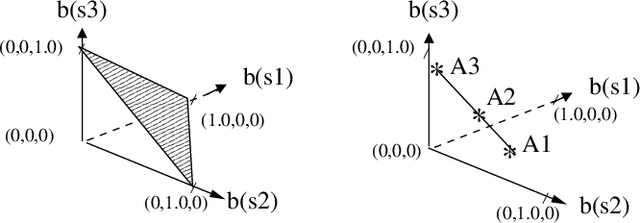
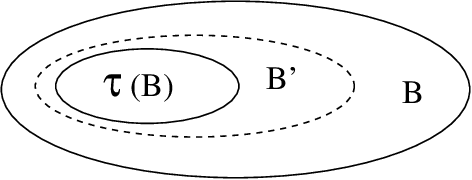
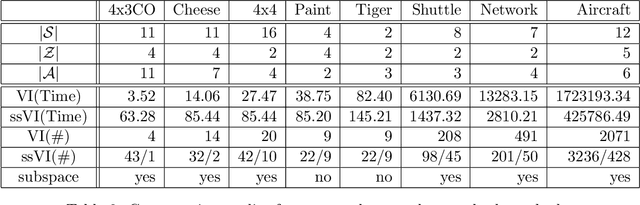
Value iteration is a popular algorithm for finding near optimal policies for POMDPs. It is inefficient due to the need to account for the entire belief space, which necessitates the solution of large numbers of linear programs. In this paper, we study value iteration restricted to belief subsets. We show that, together with properly chosen belief subsets, restricted value iteration yields near-optimal policies and we give a condition for determining whether a given belief subset would bring about savings in space and time. We also apply restricted value iteration to two interesting classes of POMDPs, namely informative POMDPs and near-discernible POMDPs.
Speeding Up the Convergence of Value Iteration in Partially Observable Markov Decision Processes
Jun 01, 2011Partially observable Markov decision processes (POMDPs) have recently become popular among many AI researchers because they serve as a natural model for planning under uncertainty. Value iteration is a well-known algorithm for finding optimal policies for POMDPs. It typically takes a large number of iterations to converge. This paper proposes a method for accelerating the convergence of value iteration. The method has been evaluated on an array of benchmark problems and was found to be very effective: It enabled value iteration to converge after only a few iterations on all the test problems.