 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScience Fiction and Fantasy in Wikipedia: Exploring Structural and Semantic Cues
Feb 27, 2026Identifying which Wikipedia articles are related to science fiction, fantasy, or their hybrids is challenging because genre boundaries are porous and frequently overlap. Wikipedia nonetheless offers machine-readable structure beyond text, including categories, internal links (wikilinks), and statements if corresponding Wikidata items. However, each of these signals reflects community conventions and can be biased or incomplete. This study examines structural and semantic features of Wikipedia articles that can be used to identify content related to science fiction and fantasy (SF/F).
Utilizing citation index and synthetic quality measure to compare Wikipedia languages across various topics
May 22, 2025This study presents a comparative analysis of 55 Wikipedia language editions employing a citation index alongside a synthetic quality measure. Specifically, we identified the most significant Wikipedia articles within distinct topical areas, selecting the top 10, top 25, and top 100 most cited articles in each topic and language version. This index was built on the basis of wikilinks between Wikipedia articles in each language version and in order to do that we processed 6.6 billion page-to-page link records. Next, we used a quality score for each Wikipedia article - a synthetic measure scaled from 0 to 100. This approach enabled quality comparison of Wikipedia articles even between language versions with different quality grading schemes. Our results highlight disparities among Wikipedia language editions, revealing strengths and gaps in content coverage and quality across topics.
OpenFact at CheckThat! 2024: Combining Multiple Attack Methods for Effective Adversarial Text Generation
Sep 04, 2024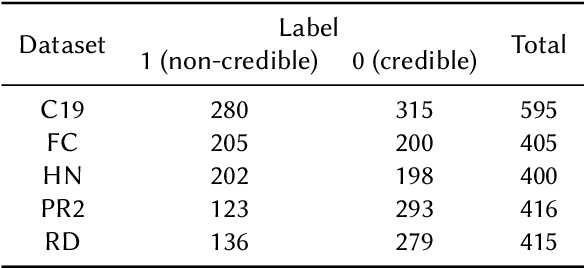

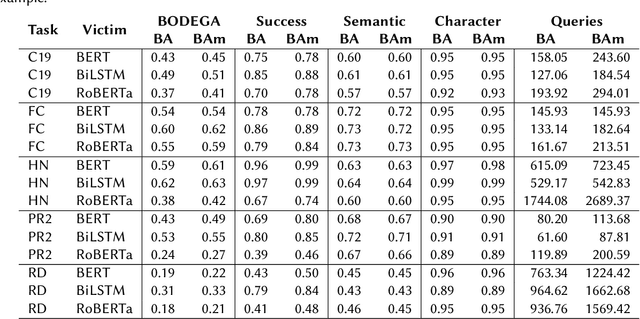
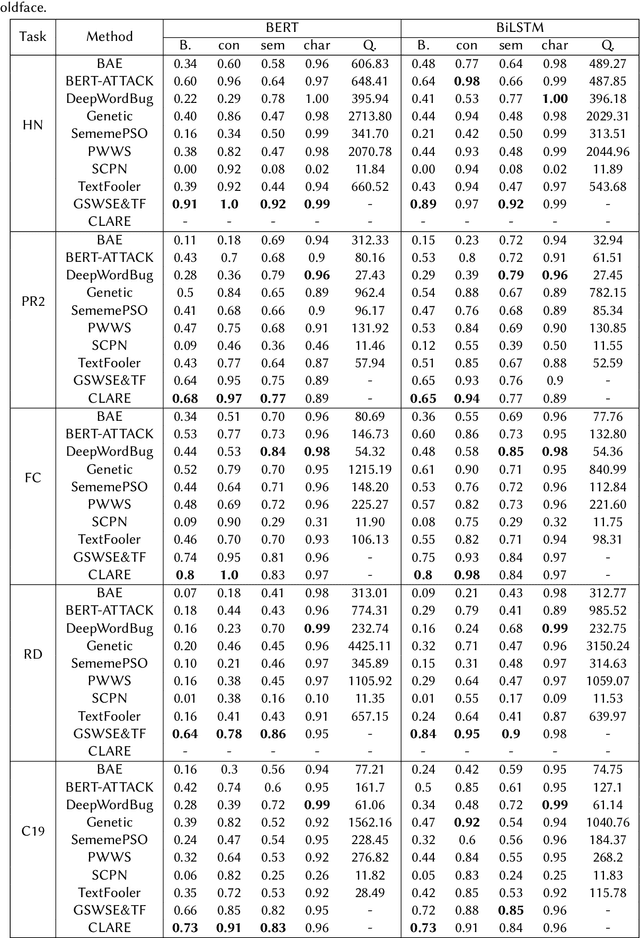
This paper presents the experiments and results for the CheckThat! Lab at CLEF 2024 Task 6: Robustness of Credibility Assessment with Adversarial Examples (InCrediblAE). The primary objective of this task was to generate adversarial examples in five problem domains in order to evaluate the robustness of widely used text classification methods (fine-tuned BERT, BiLSTM, and RoBERTa) when applied to credibility assessment issues. This study explores the application of ensemble learning to enhance adversarial attacks on natural language processing (NLP) models. We systematically tested and refined several adversarial attack methods, including BERT-Attack, Genetic algorithms, TextFooler, and CLARE, on five datasets across various misinformation tasks. By developing modified versions of BERT-Attack and hybrid methods, we achieved significant improvements in attack effectiveness. Our results demonstrate the potential of modification and combining multiple methods to create more sophisticated and effective adversarial attack strategies, contributing to the development of more robust and secure systems.
* CLEF 2024 - Conference and Labs of the Evaluation Forum
Measuring Americanization: A Global Quantitative Study of Interest in American Topics on Wikipedia
Jul 26, 2023We conducted a global comparative analysis of the coverage of American topics in different language versions of Wikipedia, using over 90 million Wikidata items and 40 million Wikipedia articles in 58 languages. Our study aimed to investigate whether Americanization is more or less dominant in different regions and cultures and to determine whether interest in American topics is universal.
Reliability in Time: Evaluating the Web Sources of Information on COVID-19 in Wikipedia across Various Language Editions from the Beginning of the Pandemic
Apr 29, 2022
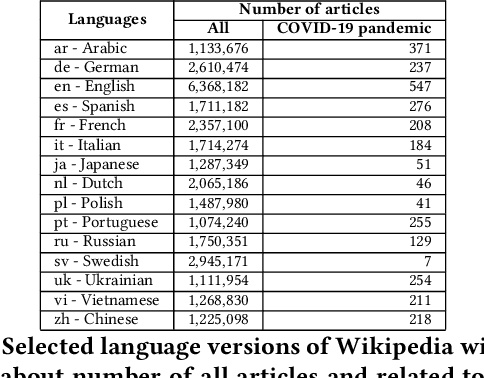
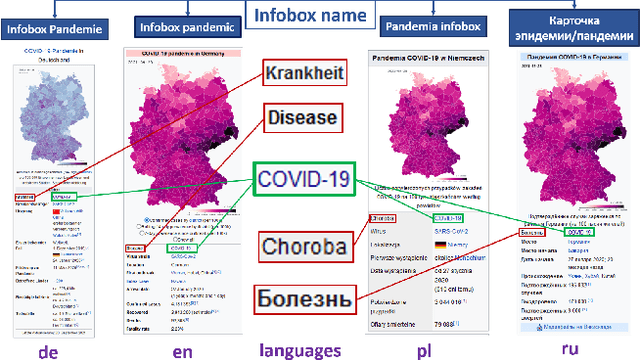
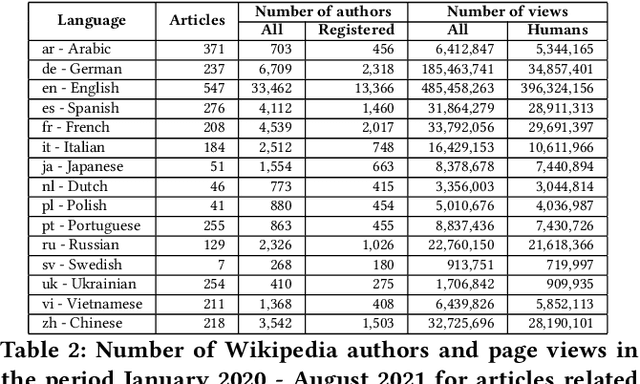
There are over a billion websites on the Internet that can potentially serve as sources of information on various topics. One of the most popular examples of such an online source is Wikipedia. This public knowledge base is co-edited by millions of users from all over the world. Information in each language version of Wikipedia can be created and edited independently. Therefore, we can observe certain inconsistencies in the statements and facts described therein - depending on language and topic. In accordance with the Wikipedia content authoring guidelines, information in Wikipedia articles should be based on reliable, published sources. So, based on data from such a collaboratively edited encyclopedia, we should also be able to find important sources on specific topics. This effect can be potentially useful for people and organizations. The reliability of a source in Wikipedia articles depends on the context. So the same source (website) may have various degrees of reliability in Wikipedia depending on topic and language version. Moreover, reliability of the same source can change over the time. The purpose of this study is to identify reliable sources on a specific topic - the COVID-19 pandemic. Such an analysis was carried out on real data from Wikipedia within selected language versions and within a selected time period.