 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTendem: A Hybrid AI+Human Platform
Feb 01, 2026Tendem is a hybrid system where AI handles structured, repeatable work and Human Experts step in when the models fail or to verify results. Each result undergoes a comprehensive quality review before delivery to the Client. To assess Tendem's performance, we conducted a series of in-house evaluations on 94 real-world tasks, comparing it with AI-only agents and human-only workflows carried out by Upwork freelancers. The results show that Tendem consistently delivers higher-quality outputs with faster turnaround times. At the same time, its operational costs remain comparable to human-only execution. On third-party agentic benchmarks, Tendem's AI Agent (operating autonomously, without human involvement) performs near state-of-the-art on web browsing and tool-use tasks while demonstrating strong results in frontier domain knowledge and reasoning.
RuCoCo: a new Russian corpus with coreference annotation
Jun 10, 2022
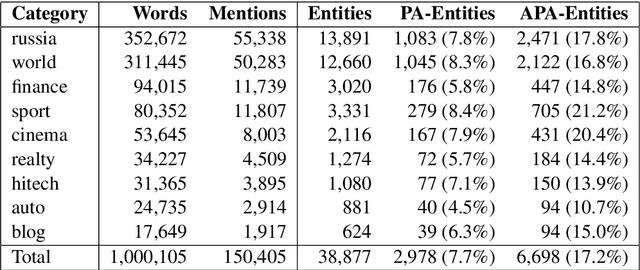
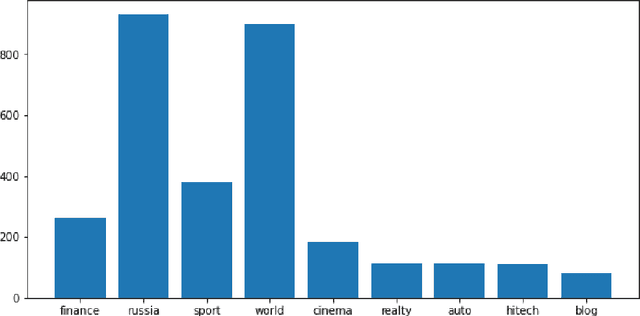

We present a new corpus with coreference annotation, Russian Coreference Corpus (RuCoCo). The goal of RuCoCo is to obtain a large number of annotated texts while maintaining high inter-annotator agreement. RuCoCo contains news texts in Russian, part of which were annotated from scratch, and for the rest the machine-generated annotations were refined by human annotators. The size of our corpus is one million words and around 150,000 mentions. We make the corpus publicly available.
Word-Level Coreference Resolution
Sep 09, 2021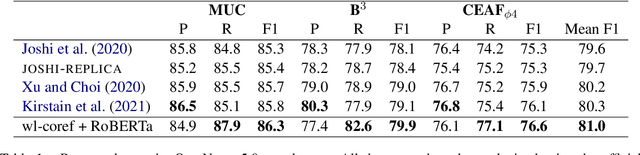
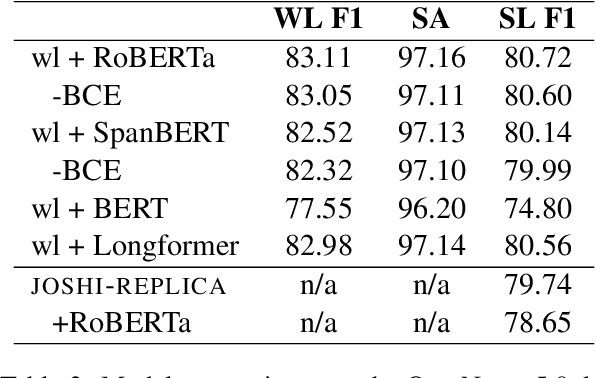

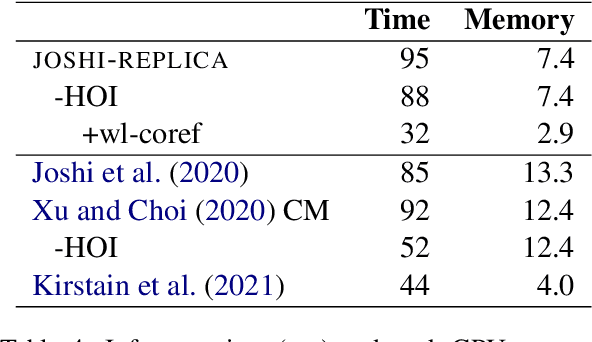
Recent coreference resolution models rely heavily on span representations to find coreference links between word spans. As the number of spans is $O(n^2)$ in the length of text and the number of potential links is $O(n^4)$, various pruning techniques are necessary to make this approach computationally feasible. We propose instead to consider coreference links between individual words rather than word spans and then reconstruct the word spans. This reduces the complexity of the coreference model to $O(n^2)$ and allows it to consider all potential mentions without pruning any of them out. We also demonstrate that, with these changes, SpanBERT for coreference resolution will be significantly outperformed by RoBERTa. While being highly efficient, our model performs competitively with recent coreference resolution systems on the OntoNotes benchmark.