 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExactly mergeable summaries
Mar 25, 2023In the analysis of large/big data sets, aggregation (replacing values of a variable over a group by a single value) is a standard way of reducing the size (complexity) of the data. Data analysis programs provide different aggregation functions. Recently some books dealing with the theoretical and algorithmic background of traditional aggregation functions were published. A problem with traditional aggregation is that often too much information is discarded thus reducing the precision of the obtained results. A much better, preserving more information, summarization of original data can be achieved by representing aggregated data using selected types of complex data. In complex data analysis the measured values over a selected group $A$ are aggregated into a complex object $\Sigma(A)$ and not into a single value. Most of the aggregation functions theory does not apply directly. In our contribution, we present an attempt to start building a theoretical background of complex aggregation. We introduce and discuss exactly mergeable summaries for which it holds for merging of disjoint sets of units \[ \Sigma(A \cup B) = F( \Sigma(A),\Sigma(B)),\qquad \mbox{ for } \quad A\cap B = \emptyset .\]
Clustering of Modal Valued Symbolic Data
Jul 23, 2015
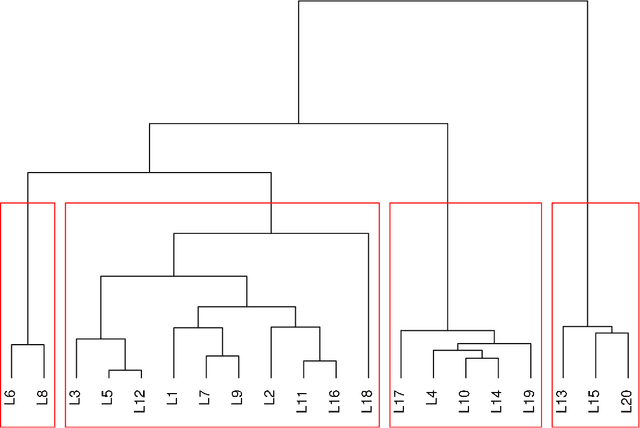
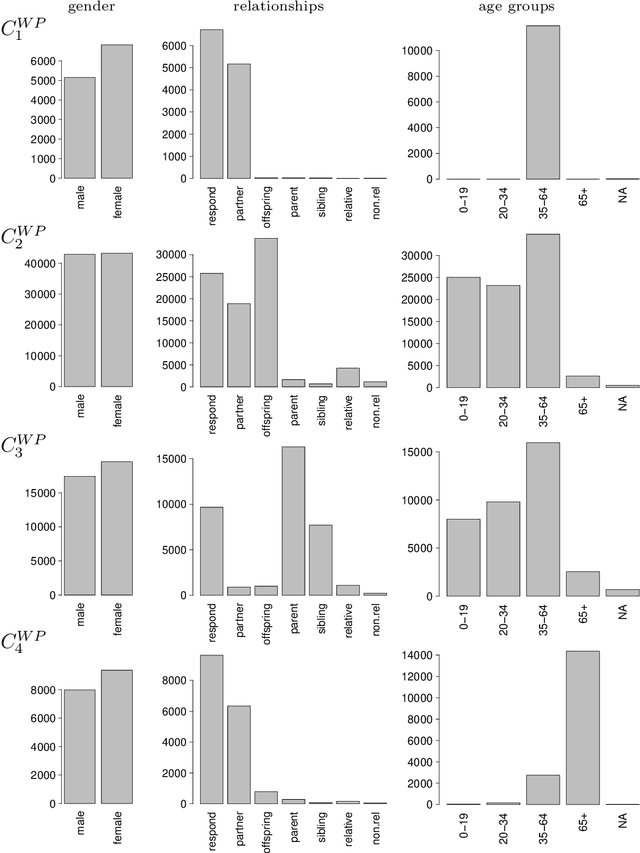
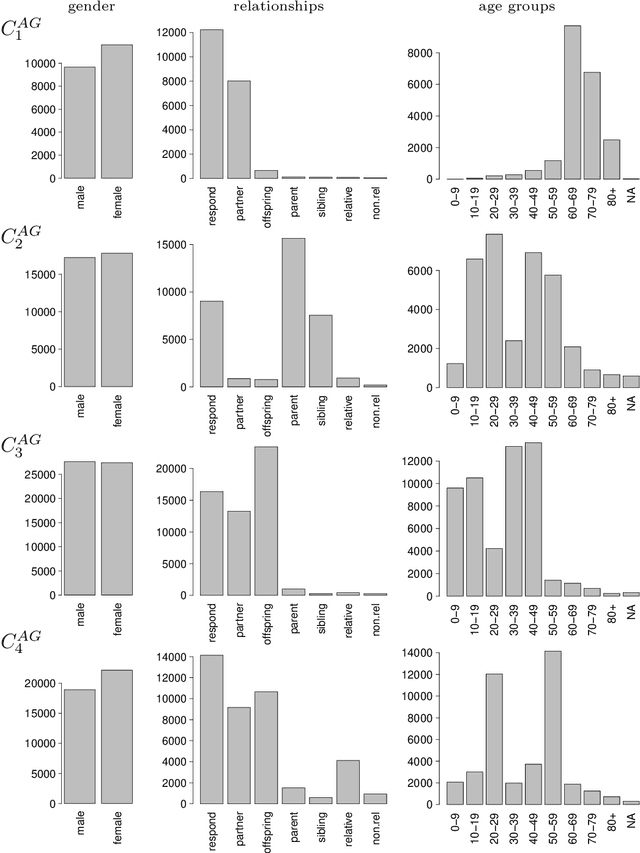
Symbolic Data Analysis is based on special descriptions of data - symbolic objects (SO). Such descriptions preserve more detailed information about units and their clusters than the usual representations with mean values. A special kind of symbolic object is a representation with frequency or probability distributions (modal values). This representation enables us to consider in the clustering process the variables of all measurement types at the same time. In the paper a clustering criterion function for SOs is proposed such that the representative of each cluster is again composed of distributions of variables' values over the cluster. The corresponding leaders clustering method is based on this result. It is also shown that for the corresponding agglomerative hierarchical method a generalized Ward's formula holds. Both methods are compatible - they are solving the same clustering optimization problem. The leaders method efficiently solves clustering problems with large number of units; while the agglomerative method can be applied alone on the smaller data set, or it could be applied on leaders, obtained with compatible nonhierarchical clustering method. Such a combination of two compatible methods enables us to decide upon the right number of clusters on the basis of the corresponding dendrogram. The proposed methods were applied on different data sets. In the paper, some results of clustering of ESS data are presented.