 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMACKO: Sparse Matrix-Vector Multiplication for Low Sparsity
Nov 17, 2025Sparse Matrix-Vector Multiplication (SpMV) is a fundamental operation in the inference of sparse Large Language Models (LLMs). Because existing SpMV methods perform poorly under the low and unstructured sparsity (30-90%) commonly observed in pruned LLMs, unstructured pruning provided only limited memory reduction and speedup. We propose MACKO-SpMV, a GPU-optimized format and kernel co-designed to reduce storage overhead while preserving compatibility with the GPU's execution model. This enables efficient SpMV for unstructured sparsity without specialized hardware units (e.g., tensor cores) or format-specific precomputation. Empirical results show that at sparsity 50%, MACKO is the first approach with significant 1.5x memory reduction and 1.2-1.5x speedup over dense representation. Speedups over other SpMV baselines: 2.8-13.0x over cuSPARSE, 1.9-2.6x over Sputnik, and 2.2-2.5x over DASP. Applied to Llama2-7B pruned with Wanda to sparsity 50%, it delivers 1.5x memory reduction and 1.5x faster inference at fp16 precision. Thanks to MACKO, unstructured pruning at 50% sparsity is now justified in real-world LLM workloads.
Addition is almost all you need: Compressing neural networks with double binary factorization
May 16, 2025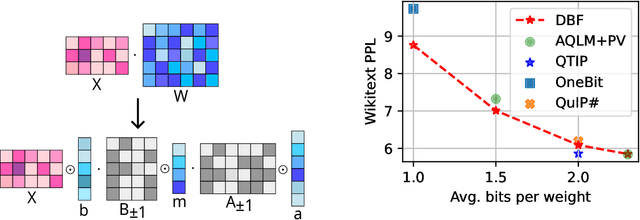
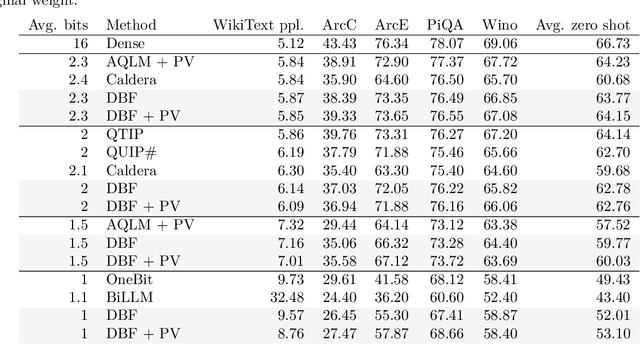
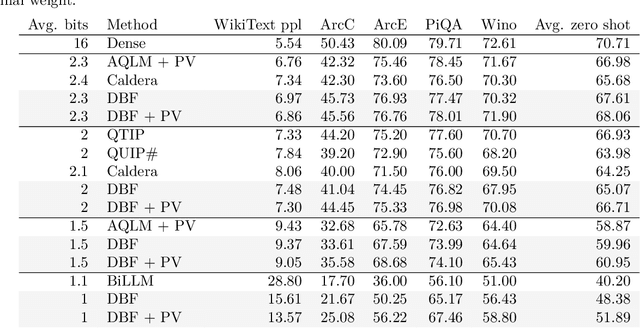
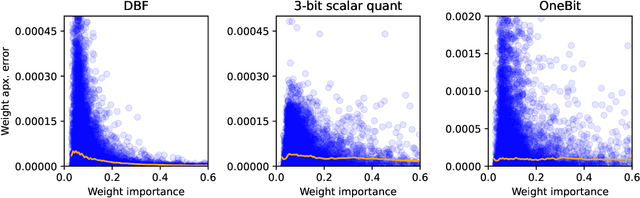
Binary quantization approaches, which replace weight matrices with binary matrices and substitute costly multiplications with cheaper additions, offer a computationally efficient approach to address the increasing computational and storage requirements of Large Language Models (LLMs). However, the severe quantization constraint ($\pm1$) can lead to significant accuracy degradation. In this paper, we propose Double Binary Factorization (DBF), a novel method that factorizes dense weight matrices into products of two binary (sign) matrices, each accompanied by scaling vectors. DBF preserves the efficiency advantages of binary representations while achieving compression rates that are competitive with or superior to state-of-the-art methods. Specifically, in a 1-bit per weight range, DBF is better than existing binarization approaches. In a 2-bit per weight range, DBF is competitive with the best quantization methods like QuIP\# and QTIP. Unlike most existing compression techniques, which offer limited compression level choices, DBF allows fine-grained control over compression ratios by adjusting the factorization's intermediate dimension. Based on this advantage, we further introduce an algorithm for estimating non-uniform layer-wise compression ratios for DBF, based on previously developed channel pruning criteria. Code available at: https://github.com/usamec/double_binary
Two Sparse Matrices are Better than One: Sparsifying Neural Networks with Double Sparse Factorization
Sep 27, 2024



Neural networks are often challenging to work with due to their large size and complexity. To address this, various methods aim to reduce model size by sparsifying or decomposing weight matrices, such as magnitude pruning and low-rank or block-diagonal factorization. In this work, we present Double Sparse Factorization (DSF), where we factorize each weight matrix into two sparse matrices. Although solving this problem exactly is computationally infeasible, we propose an efficient heuristic based on alternating minimization via ADMM that achieves state-of-the-art results, enabling unprecedented sparsification of neural networks. For instance, in a one-shot pruning setting, our method can reduce the size of the LLaMA2-13B model by 50% while maintaining better performance than the dense LLaMA2-7B model. We also compare favorably with Optimal Brain Compression, the state-of-the-art layer-wise pruning approach for convolutional neural networks. Furthermore, accuracy improvements of our method persist even after further model fine-tuning. Code available at: https://github.com/usamec/double_sparse.