 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Hateful Memes Using a Multimodal Deep Ensemble
Dec 24, 2020

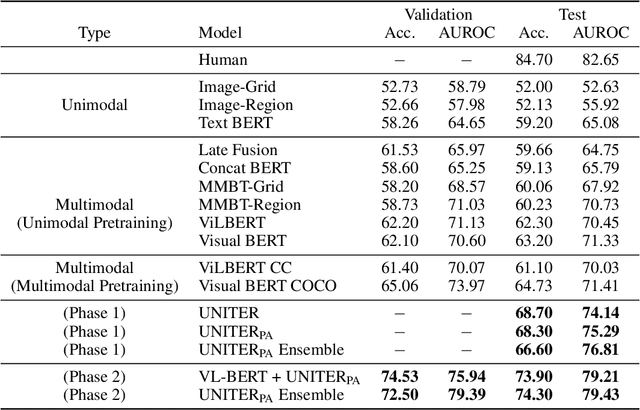
While significant progress has been made using machine learning algorithms to detect hate speech, important technical challenges still remain to be solved in order to bring their performance closer to human accuracy. We investigate several of the most recent visual-linguistic Transformer architectures and propose improvements to increase their performance for this task. The proposed model outperforms the baselines by a large margin and ranks 5$^{th}$ on the leaderboard out of 3,100+ participants.
* 6 pages, NeurIPS 2020, The Hateful Memes Challenge Workshop at NeurIPS 2020
Predicting the future relevance of research institutions - The winning solution of the KDD Cup 2016
Sep 09, 2016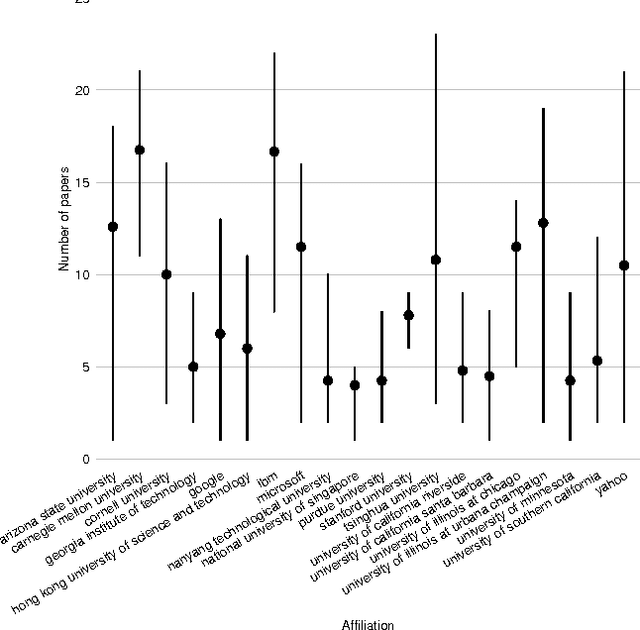

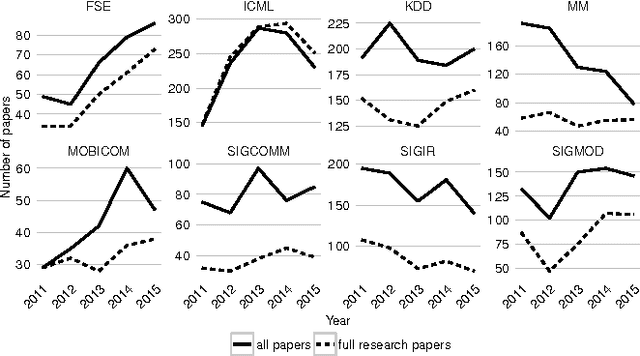

The world's collective knowledge is evolving through research and new scientific discoveries. It is becoming increasingly difficult to objectively rank the impact research institutes have on global advancements. However, since the funding, governmental support, staff and students quality all mirror the projected quality of the institution, it becomes essential to measure the affiliation's rating in a transparent and widely accepted way. We propose and investigate several methods to rank affiliations based on the number of their accepted papers at future academic conferences. We carry out our investigation using publicly available datasets such as the Microsoft Academic Graph, a heterogeneous graph which contains various information about academic papers. We analyze several models, starting with a simple probabilities-based method and then gradually expand our training dataset, engineer many more features and use mixed models and gradient boosted decision trees models to improve our predictions.
Detecting Singleton Review Spammers Using Semantic Similarity
Sep 09, 2016



Online reviews have increasingly become a very important resource for consumers when making purchases. Though it is becoming more and more difficult for people to make well-informed buying decisions without being deceived by fake reviews. Prior works on the opinion spam problem mostly considered classifying fake reviews using behavioral user patterns. They focused on prolific users who write more than a couple of reviews, discarding one-time reviewers. The number of singleton reviewers however is expected to be high for many review websites. While behavioral patterns are effective when dealing with elite users, for one-time reviewers, the review text needs to be exploited. In this paper we tackle the problem of detecting fake reviews written by the same person using multiple names, posting each review under a different name. We propose two methods to detect similar reviews and show the results generally outperform the vectorial similarity measures used in prior works. The first method extends the semantic similarity between words to the reviews level. The second method is based on topic modeling and exploits the similarity of the reviews topic distributions using two models: bag-of-words and bag-of-opinion-phrases. The experiments were conducted on reviews from three different datasets: Yelp (57K reviews), Trustpilot (9K reviews) and Ott dataset (800 reviews).
* 6 pages, WWW 2015